mycat安装过程
mycat下载地址:
wget http://dl.mycat.io/1.6-RELEASE/Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
1,下载
首先 cd /usr/local/
wget http://dl.mycat.io/1.6-RELEASE/Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
2 ,安装
tar -zxvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
3 ,启动mycat
/usr/local/mycat/bin/mycat start

之前启动过了 就重新启动下
[root@zhuangy local]# /usr/local/mycat/bin/mycat
Usage: /usr/local/mycat/bin/mycat { console | start | stop | restart | status | dump }
查看 命令
主要配置介绍
1,schema.xml
cat /usr/local/mycat/conf/schema.xml
如果配置成功连接mycat就有TESTDB库和表,这里给出方便理解

<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- schema 标签用于定义 MyCat 实例中的逻辑库,MyCat 可以有多个逻辑库,每个逻辑库都有自己的相关配置。可以使用
schema 标签来划分这些不同的逻辑库。 checkSQLschema False 过滤schema定义。
select * from testdb.company => select * from company;True 不过滤schema定义。有可能报错大小写等。
sqlMaxLimit Limit 自动加入limit,会影响最后返回条数。例如:select * from company。-->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!-- auto sharding by id (long)
制定Mycat中的逻辑表。最后要做数据分片的表。 dataNode把相应的表存到对应的DB中。rule分片规则。对应
rule.xml中的规则。 type逻辑表的类型。普通表和全局表。name表名
-->
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
<!-- global table is auto cloned to all defined data nodes ,so can join
with any table whose sharding node is in the same data node -->
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
<table name="goods" primaryKey="ID" type="global" dataNode="dn1,dn2" />
<!-- random sharding using mod sharind rule autoIncrement Mycat根据last_insert_id()返回结果。这个需要mysql主键设置配合。
-->
<table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3"
rule="mod-long" />
<!-- needAddLimit 是否自动在每一条SQL语句后面加上limit限制。
<table name="dual" primaryKey="ID" dataNode="dnx,dnoracle2" type="global"
needAddLimit="false"/> <table name="worker" primaryKey="ID" dataNode="jdbc_dn1,jdbc_dn2,jdbc_dn3"
rule="mod-long" /> -->
<table name="employee" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile" />
<table name="customer" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id"
parentKey="id">
<childTable name="order_items" joinKey="order_id"
parentKey="id" />
</childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id"
parentKey="id" />
</table>
<!-- <table name="oc_call" primaryKey="ID" dataNode="dn1$0-743" rule="latest-month-calldate"
/> -->
</schema>
<!-- <dataNode name="dn1$0-743" dataHost="localhost1" database="db$0-743"
/> -->
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<!--<dataNode name="dn4" dataHost="sequoiadb1" database="SAMPLE" />
<dataNode name="jdbc_dn1" dataHost="jdbchost" database="db1" />
<dataNode name="jdbc_dn2" dataHost="jdbchost" database="db2" />
<dataNode name="jdbc_dn3" dataHost="jdbchost" database="db3" /> -->
<!--dataHost 主要定义和Mysql集群有关的信息,数据实例、读写分离配置和心跳检测语句。
balance
负载均衡配置
0 代表不开启读写分离,所有的读操作都发送到writeHost上。
1 writeHost和readHost都要参与select语句的负载均衡。
双主双从模式 M1->S1, M2->S2, M1和M2互为主备。M2/S1/S2都要参与select语句的负载均衡。
2 所有读操作都随机分配给writeHost/readHost
3 所有的读操作随机分发到writeHost下面的readHost上执行。
writeType
0 所有的写操作都分发到第一个writeHost。如果第二个挂了,分发到第二个。
1 所有的写操作都要随机分发到所有配置的writeHost上。1.5以后不推荐。
dbType
支持多种db类型。
switchType
-1 代表不自动切换
1 默认值,自动切换。
2 基于Mysql主从同步的状态决定是否切换
show slave status;
3 基于MySQL Galera Cluster切换机制。
show status like ‘wsrep%’;
-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="172.17.0.4:3306" user="root"
password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="172.17.0.2:3306" user="root" password="123456" />
</writeHost>
<!-- <writeHost host="hostS1" url="172.17.0.4:3306" user="root"
password="123" />
-->
</dataHost>
<!--
<dataHost name="sequoiadb1" maxCon="1000" minCon="1" balance="0" dbType="sequoiadb" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="sequoiadb://1426587161.dbaas.sequoialab.net:11920/SAMPLE" user="jifeng" password="jifeng"></writeHost>
</dataHost>
<dataHost name="oracle1" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="oracle" dbDriver="jdbc"> <heartbeat>select 1 from dual</heartbeat>
<connectionInitSql>alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'</connectionInitSql>
<writeHost host="hostM1" url="jdbc:oracle:thin:@127.0.0.1:1521:nange" user="base" password="123456" > </writeHost> </dataHost>
<dataHost name="jdbchost" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="mongodb" dbDriver="jdbc">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM" url="mongodb://192.168.0.99/test" user="admin" password="123456" ></writeHost> </dataHost>
<dataHost name="sparksql" maxCon="1000" minCon="1" balance="0" dbType="spark" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="jdbc:hive2://feng01:10000" user="jifeng" password="jifeng"></writeHost> </dataHost> -->
<!-- <dataHost name="jdbchost" maxCon="1000" minCon="10" balance="0" dbType="mysql"
dbDriver="jdbc"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1"
url="jdbc:mysql://localhost:3306" user="root" password="123456"> </writeHost>
</dataHost> -->
</mycat:schema>
Server.xml文件
cat /usr/local/mycat/conf/server.xml
是Mycat最重要的配置文件之一。主要管理Mycat逻辑库、逻辑表、表、分片规则、Datasource。
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 -->
<property name="sequnceHandlerType">2</property>
<!-- <property name="useCompression">1</property>--> <!--1为开启mysql压缩协议-->
<!-- <property name="fakeMySQLVersion">5.6.20</property>--> <!--设置模拟的MySQL版本号-->
<!-- <property name="processorBufferChunk">40960</property> -->
<!--
<property name="processors">1</property>
<property name="processorExecutor">32</property>
-->
<!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena-->
<property name="processorBufferPoolType">0</property>
<!--默认是65535 64K 用于sql解析时最大文本长度 -->
<!--<property name="maxStringLiteralLength">65535</property>-->
<!--<property name="sequnceHandlerType">0</property>-->
<!--<property name="backSocketNoDelay">1</property>-->
<!--<property name="frontSocketNoDelay">1</property>-->
<!--<property name="processorExecutor">16</property>-->
<!--
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
<property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property>
<property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> -->
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property>
<!--
off heap for merge/order/group/limit 1开启 0关闭
-->
<property name="useOffHeapForMerge">1</property>
<!--
单位为m
-->
<property name="memoryPageSize">1m</property>
<!--
单位为k
-->
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<!--
单位为m
-->
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">true</property>
</system>
<!-- 全局SQL防火墙设置 -->
<!--
<firewall>
<whitehost>
<host host="127.0.0.1" user="mycat"/>
<host host="127.0.0.2" user="mycat"/>
</whitehost>
<blacklist check="false">
</blacklist>
</firewall>
-->
<user name="root">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
主要用于管理Mycat的用户名,权限,黑白名单等等设置。这个文件主要和Mycat Server运行环境有关。
System标签
| 属性 |
说明 |
备注 |
| useSqlStat |
开启实时统计 |
1为开启,0为关闭 |
| useGlobleTableCheck |
全局表一致性检测 |
1为开启,0为关闭 |
| sequnceHandlerType |
Mycat全局ID类型 |
0本地文件方式 |
| useCompression |
mysql压缩协议 |
1为开启,0为不开启 |
| fakeMySQLVersion |
伪装的MySQL版本号 |
|
| processorBufferChunk |
每次分配Socket Direct Buffer大小 |
默认4096字节 |
| processors |
系统可用线程数 |
默认Runtime.getRuntime().availableProcessors()返回值 |
| processorExecutor |
NIOProcessor共享businessExecutor线程池大小 |
|
| processorBufferPoolType |
每次分配Socket Direct Buffer大小 |
默认是4096个字节 |
| maxStringLiteralLength |
sql解析时最大文本长度 |
默认是65535(即64K) |
| backSocketNoDelay |
TCP连接相关属性 |
默认值1 |
| frontSocketNoDelay |
TCP连接相关属性 |
默认值1 |
| serverPort |
指定服务端口 |
默认8066 |
| managerPort |
制定管理端口 |
默认9066 |
| idleTimeout |
连接空闲时间 |
默认30分钟,单位毫秒 |
| bindIp |
Mycat服务监听的IP地址 |
|
| frontWriteQueueSize |
前端连接写队列长度 |
为了让用户知道是否队列过长(SQL结果集返回太多)。当超过指定阀值后,会产生一个告警日志 |
| handleDistributedTransactions |
分布式事务开关 |
0不过滤分布式事务 |
| useOffHeapForMerge |
是否让Mycat开启非堆内存 |
1 开启,0关闭 |
| memoryPageSize |
内存分页大小 |
|
| useStreamOutput |
是否使用流输出 |
|
| systemReserveMemorySize |
系统保留内存大小 |
|
| useZKSwitch |
是否采用zookeeper协调切换 |
true/false |
Firewall标签
定义访问控制策略:如白名单/黑名单
User标签
定义可访问mycat的用户名称/密码/是否只读
Privileges标签
控制DML:insert update select delete
单独给select权限:0010
单独给insert权限:1000
rule.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="rule2">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<tableRule name="latest-month-calldate">
<rule>
<columns>calldate</columns>
<algorithm>latestMonth</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule>
<tableRule name="jch">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule>
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function>
<function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="latestMonth"
class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function>
<function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function>
<function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">3</property>
</function>
</mycat:rule>
定义分片规则策略文件。
tableRule标签
定义table分片策略
rule标签
策略定义标签
columns
对应的分片字段
algorithm标签
tableRule分片策略对应的function名称
function标签
定义分片函数
最简单的配置
这里面需要自己配置
如果只想简单的配置,
1 ,只需要修改
<writeHost 写 url="172.17.0.4:3306" 主mysql数据库地址 ,user="root"主用户名password="123456"主密码
< readHost url="172.17.0.2:3306" 从mysql数据库地址 user="root" 从用户名password="123456" 从密码/>
</writeHost >
2 ,启动mycat
/usr/local/mycat/bin/mycat start
3,连接mycat
mysql -uroot -p123456 -hzhuangy -P8066
mysql -uroot(server.xml里面配置的user name) -p123456(server.xml里面配置的password)
-hzhuangy(主机地址,mycat安装地址,可以是localhost) -P8066 (mycat端口数据端口是8066,管理端口是9066)
<user name="root">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>cat /etc/hosts 查看绑定地址

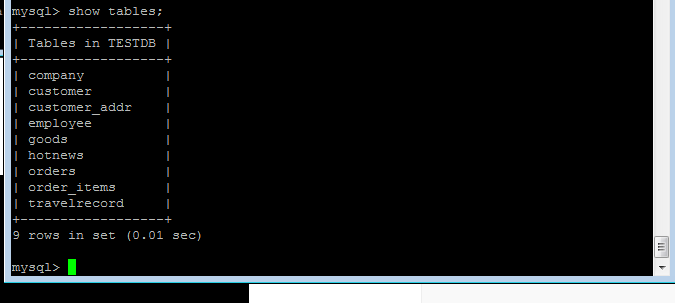
4查看db
show databases;
show tables;
可以看出就是之前Schema.xml文件中的table表
5 创建db
连接主mysql创建db(这里是mysql的主从复制,
参考https://my.oschina.net/u/3647713/blog/1801735)
create database db1;
create database db2;
create database db2;
use db1;
创建create table travelrecord (id bigint not null primary key,user_id varchar(100),traveldate DATE, fee decimal,days int);
show tables;

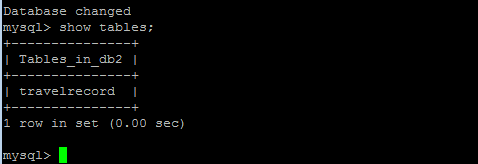
use db2;
创建create table travelrecord (id bigint not null primary key,user_id varchar(100),traveldate DATE, fee decimal,days int);
show tables;
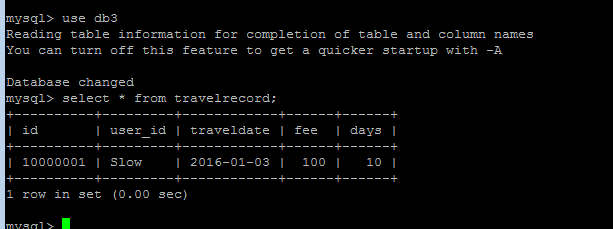
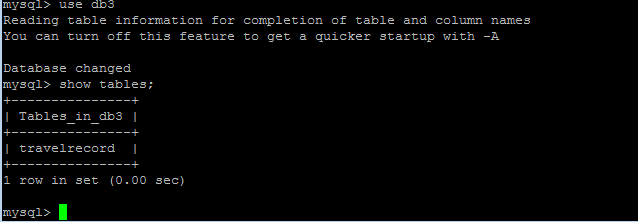
use db3;
创建create table travelrecord (id bigint not null primary key,user_id varchar(100),traveldate DATE, fee decimal,days int);
show tables;
这样的从库就会自动同步了 ,
6 切换到mycat库
cat /usr/local/mycat/conf/auto-sharding-long.txt
查看travelrecord分片规则根据id分片

插入数据
mysql> insert into travelrecord(id,user_id,traveldate,fee,days) values(1,'Victor',20160101,100,10);
Query OK, 1 row affected (0.00 sec)
mysql>insert into travelrecord(id,user_id,traveldate,fee,days) values(1,'Victor',20160101,100,10);
Query OK, 1 row affected (0.00 sec)
Query OK, 1 row affected (0.00 sec)
mysql>insert into travelrecord(id,user_id,traveldate,fee,days) values(1,'Victor',20160101,100,10);
Query OK, 1 row affected (0.00 sec)
7 切换主库查看
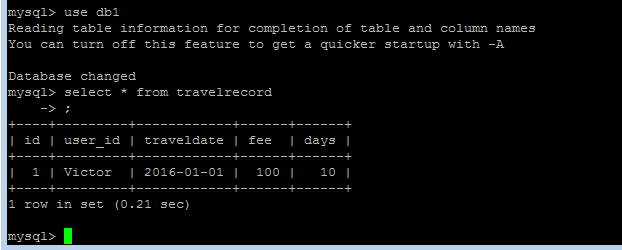
use db1
select * from travelrecord;可以看出db1中travelrecord只有一条数据ID=1
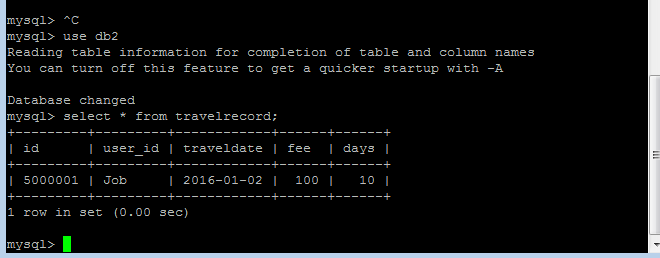
use db2;
select * from travelrecord;db2中travelrecord只有一条数据ID=5000001
use db3;
select * from travelrecord;db3中travelrecord只有一条数据ID=10000001