【问题现象】
在查询多个监控网元性能数据时候,发现都有断点,查看采集程序都正常,而队列中有一个代理的队列突然积压了40多万个指标未处理
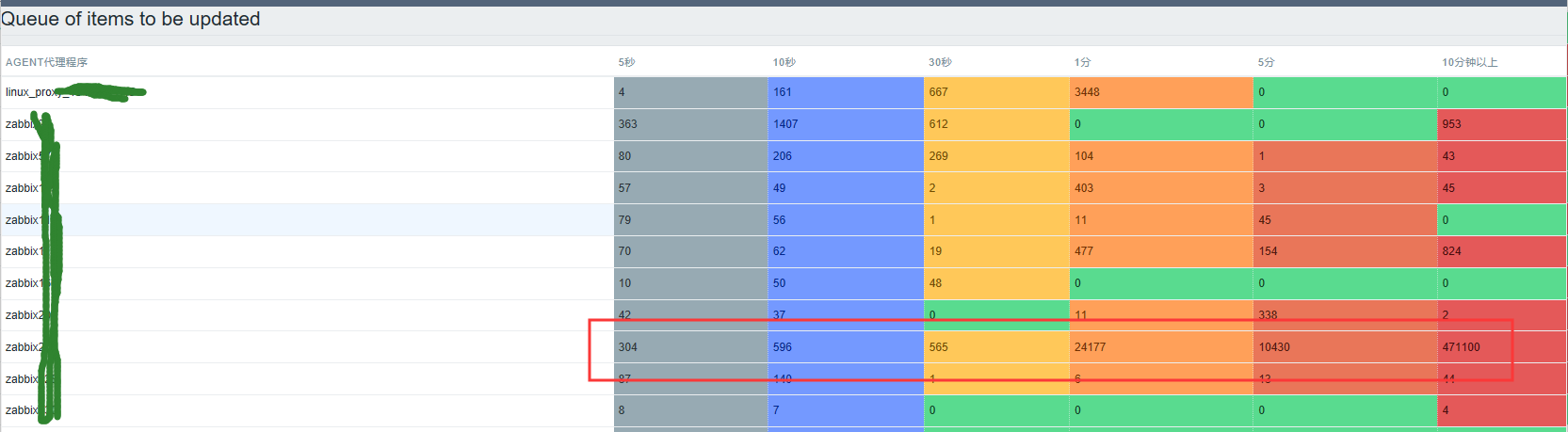
【处理过程】
1、查看proxy的日志情况,无任何异常信息反馈
2、查看代理对应的mysql,无异常等待时间
3、查看代理和数据库所在的主机性能,CPU、内存、网络、IO指标都正常
4、尝试重启数据库和代理进程,问题未解决
5、通过队列的“细节”选项,查看堵塞的监控项情况,发现有大量的容器主机节点的监控信息
6、查看对应主机的监控信息,发现通过自动发现模版,扫描出10多万个监控项

这个也是直接导致积压的原因
经确认,这一批容器节点中的pod之前出现接近一千多次的异常重启,使proxy产生大量异常的监控项导致
将这几个容器主机的监控置为失效后,队列瞬间恢复正常