0.序
我同学论文需要数据建模,想用爬虫软件爬取数据,就问有没有人会用爬虫软件,我回了句:我不会用爬虫软件,但我会写爬虫。然后爬虫事件就拉开了序幕。
1.
我同学要的数据是P2P借款人信息,她就选了翼龙贷上的数据,我先去浏览了翼龙贷网站,然后知道了数据的位置。先要进入产品列表页面,这里有各期产品列表,再进入一期产品页面,这里就有个债权列表,这就是要的借款人列表,点击借款人就会进入借款人的详细信息了,这要跳转3个页面才是我们要的最终数据。
这是我首先想到的是,先抓取产品列表页面的产品链接,再通过产品链接抓取债权列表页面上的借款人链接,最后进入借款人信息页面抓取所需数据。想到就做,打开浏览器,进入网站,按下F12,结果我懵逼了。。。
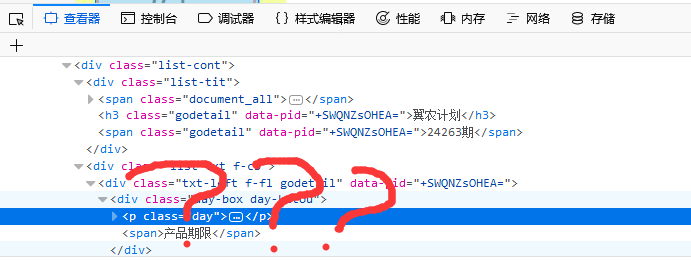
链接在何方???我仔细想了想,不对,这个网站的数据根本不在页面上,我打开页面源代码,果然没有。一般数据抓取有2种方式,一种是直接抓取html源码,然后解析html获取数据,另一种就是通过向数据源接口(如ajax接口)发送请求来获取数据源,再解析数据源。我再重新看了看这个网站,发现它先加载html页面框架,再通过javascript来加载数据的,这意味着我们可以直接通过某个api接口来获取数据。F12再刷新页面,然后发现了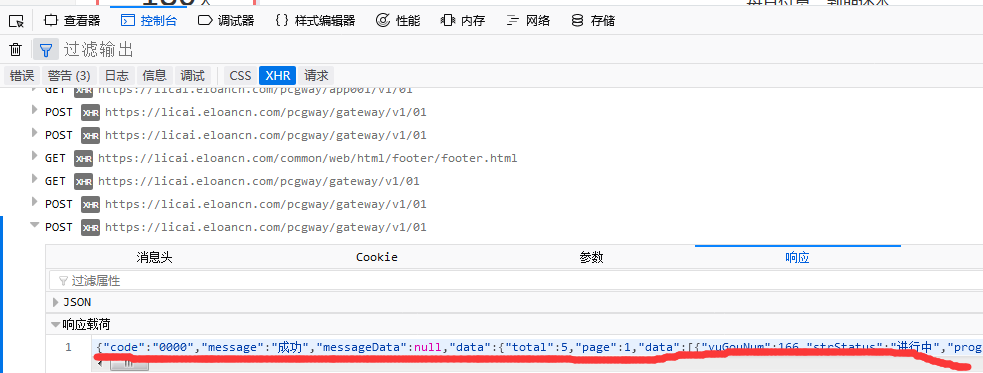
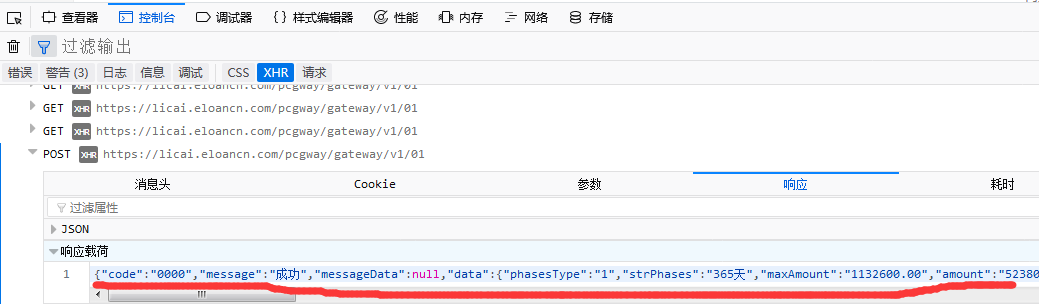
这个网站的数据源居然都是通过同一个api来获取json数据的,这样不就太方便我们了吗?再仔细研究了下POST参数,发现了要获取数据要分三步走,第一步,获取产品列表的id值; 第二步,用第一步获取的id值做为第二步POST表格参数的pid值,发送POST,获取借款人id;
第二步,用第一步获取的id值做为第二步POST表格参数的pid值,发送POST,获取借款人id;
第三步,用第二步得到的id来作为POST表格参数的id值,发送POST,获取最终数据。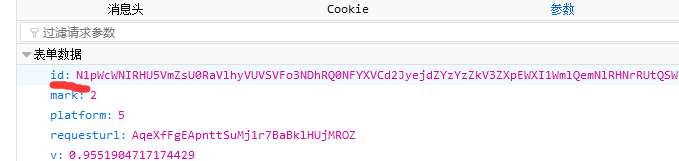
提醒下,不同产品列表的requesturl不同,同一产品列表则相同。
知道获取数据的思路,那剩下的就是爬虫逻辑的构造了,首先就是横推过去(单线程)
# -*- coding:utf-8 -*-
import requests
Headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64;x64;rv:58.0) Gecko/20100101 Firefox/58.0",
"Host":"licai.eloancn.com",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Encoding": "gzip, deflate, br",
"Content-Type": "application/x-www-form-urlencoded;charset=utf8"
}
params = {
"pageNo":1,
"platform":5,
"requesturl":"IjE9HTj42YUib_sYkABPPFnldpmC7Qbc",
"v":0.4797244526462968
}
params2 = {'pageNo': 1,
'pid': '',
'requesturl': 'IjE9HTj42YWoZVeH5M3LwlnldpmC7Qbc'
}
params3 = {'id': '',
'mark': 2,
'platform': 5,
'requesturl': 'AqeXfFgEApnttSuMj1r7BaBklHUjMROZ',
'v': 0.29441846044222364
}
url = "https://licai.eloancn.com/pcgway/gateway/v1/01"
PID = []
ID = []
rep = requests.post(url,data=params,headers=Headers).json()
for i in rep["data"]["data"]:
PID.append((i["id"],i["strPhases"],i["strInterestrate"],i["title"]))
for i in PID:
params2["pid"]=i[0]
rep2 = requests.post(url,data=params2,headers=Headers).json()
for j in rep2["data"]["data"]:
ID.append((j["id"],i[1],i[2],i[3]))
for i in ID:
params3["id"] = i[0]
rep3 = request.post(url,data=params3,headers=Headers).json()
#数据就在rep3["data"]里,自己提取需要的数据
我是直接用了xlwt模块将提取到的数据做成了xls文件,然后就给了我同学。
2.
再看了看代码,太不优雅了,丑。。。而且速度还慢(虽然最主要还是丑0.0),就琢磨了下,要不用多线程?多线程!这个爬虫主要是网络IO花时间,那就搞个线程与主进程分离开来,然后就是再搞个线程来处理返回的reponse,嗯,再最后搞个线程来写数据到xls吧,附草图来纪念一下
 (额,字丑别笑)
(额,字丑别笑)
然后就是用多线程出了种种问题,但是我还是搞定了,最完善的版本就是第四版了(别问我第二第三哪去了。。。。)在第四版里有详细注释,哎已经凌晨2点半了,马上毕业了,工作还没签,愁!算了,还是洗洗睡吧。
源码:https://github.com/MrLiupython/Spider/tree/master/yld