首先,我们打开中国天气网,找到黄石市近7天天气的网页。http://www.weather.com.cn/weather/101200601.shtml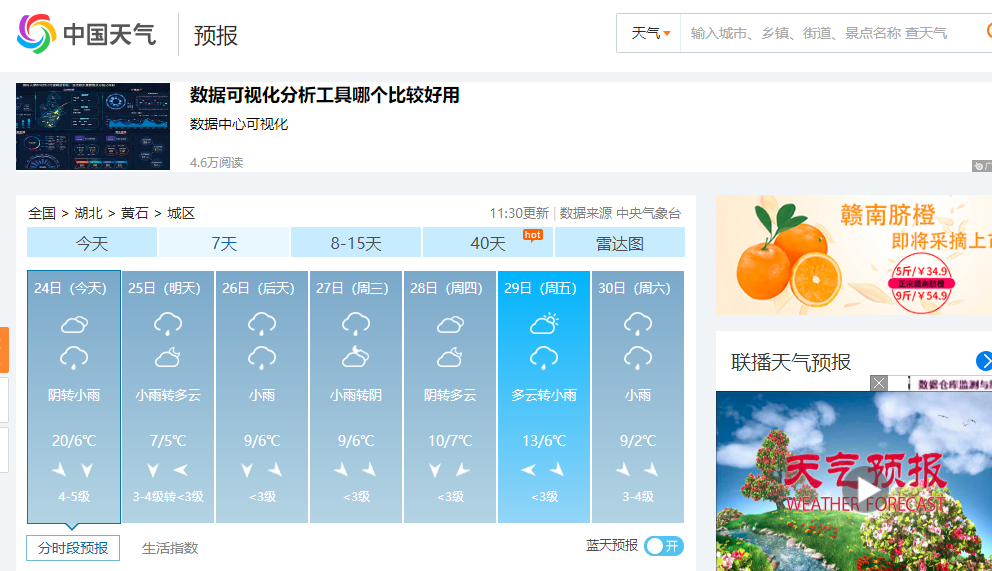
然后按F12开始分析网页结构,找到各个标签,并分析它们的作用。h1:日期;p:天气;tem-span:最高温;tem-i:最低温;win:风;em:风向;win-i:风力。
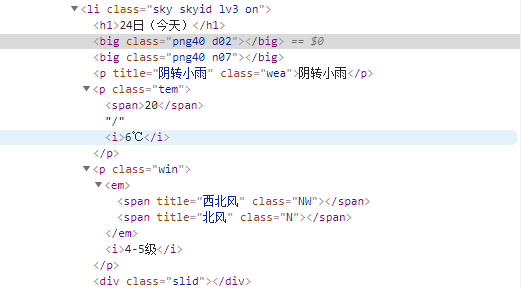
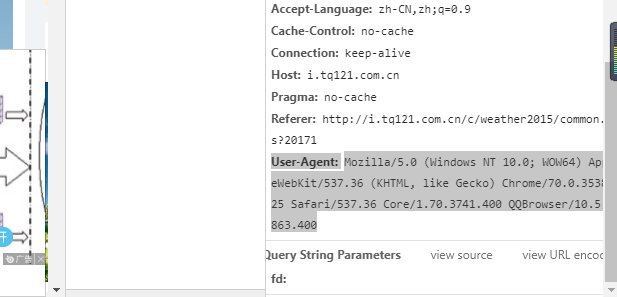
接下来,我们需要找到它的用户代理,即User-agent。
分析的差不多了,我们就开始写代码,下面是我写的全部代码及运行结果:
import re import requests from bs4 import BeautifulSoup def get_page(url): #获取URL try: headers = {'user-agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36'} r = requests.get(url,headers) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return '出现异常' #异常处理,防止出现错误 def parse_page(html, weather_list): soup = BeautifulSoup(html, 'html.parser') day_list = soup.find('ul', 't clearfix').find_all('li') for day in day_list: date = day.find('h1').get_text() wea = day.find('p', 'wea').get_text() if day.find('p', 'tem').find('span'): #判断标签'p','tem'下是否有标签'span',以此判断是否有最高温 tem_h = day.find('p', 'tem').find('span').get_text() else: tem_h = '' #最高温 tem_l = day.find('p', 'tem').find('i').get_text() #最低温 win1 = re.findall('(?<= title=").*?(?=")', str(day.find('p','win').find('em'))) win2 = '-'.join(win1) #风向,win1-win2 level = day.find('p', 'win').find('i').get_text() #风力 weather_list.append([date, wea, tem_l, tem_h, win2, level]) def print_wea(weather_list): s = ' \t' * 3 print(s.join(('日期', '天气', '最低温', '最高温', '风向', '风力'))) for i in weather_list: print(i[0], '\t',i[1],'\t\t\t',i[2],'\t\t\t',i[3],'\t\t',i[4],'\t\t',i[5]) #按格式输出 def main(): url = 'http://www.weather.com.cn/weather/101200601.shtml' html = get_page(url) wea_list = [] parse_page(html, wea_list) print("\t\t\t\t\t\t\t\t\t黄石市近7天天气预报") print_wea(wea_list) if __name__ == '__main__': main()
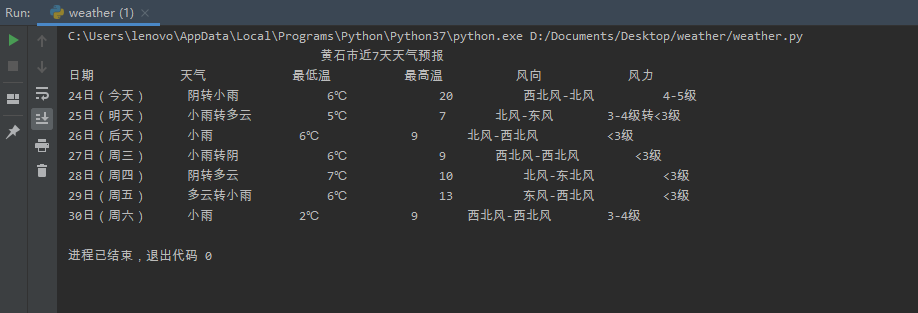
在格式输出这方面,我的这份代码还存在着很大的缺陷,把它发出来,欢迎大家跟我一起讨论,改进。