python 2.7编码问题,着实令人头疼不已,这两天抽闲想真正弄明白。需要弄清楚这个问题,首先需要明白ASCII,Unicode 和 UTF-8之间的关系。
进行对上述几种概念进行描述之前,先进行简单的总结:
1、第一个阶段,计算机出现初期,计算机中用8位表示一个字节,共256种状态,用来表示英文、标点、以及其他的一些特殊符号(控制码)等,已经足够了,这种方式被大家成为是ANSI的ASCII编码
2、随着计算机慢慢渗透到其他国家,127种状态已经不能满足需求,比如中文常用的字符上万种,中国人民基于ASCII编码对中文进行扩充改造,于是出现了GB2312,但由于汉字实在太多,所以后面又出现了GBK、GB18030
3、和我们国家的情况类似,都有自己的编码系统,如果不安装相应的解码系统,那就只有乱码了
4、ISO这个组织终于看不下去了,于是规定了一种字符集,包括目前世界上所有的字符
5、UNICODE 在网络传输中,出现了两个标准 UTF-8 和 UTF-16,分别每次传输 8个位和 16个位。于是就会有人产生疑问,UTF-8 既然能保存那么多文字、符号,为什么国内还有这么多使用 GBK 等编码的人?因为 UTF-8 等编码体积比较大,占电脑空间比较多,如果面向的使用人群绝大部分都是中国人,用 GBK 等编码也可以。
一、ASCII编码
计算机内部的所有信息都是由二进制表示,每一位都可以用0和1两种状态表示,8位共可以表示256种状态,8位二进制表示一个字节,则一个字节可以代表256字符,因为英文用128个字符表示已经足够了,则ASCII码只用了128个字符编码,最高位0位,2的7次方刚好为128。
我们可以知道ASCII码表示英文没有问题,但是世界上还有其它许多种的字符,ASCII码肯定是表示不了这么多的字符,需要其它的编码方式。比如中文常用的汉字上数万个,256种的编码方式肯定不适合,汉字一般使用GB2312编码。
二、ANSI编码
ANSI可以认为是ASCII的扩展集,表示对应当前系统的locale的遗留编码,根据当前的locale选定具体的编码,比如简体中文就是GBK,繁体就是BIG5,其它的有其它的编码方式,所以ASCII的扩展集,不同语言地域使用的是不一样的,所以各国都有自己的编码规则,相互不能兼容,所以ISO牵头着手解决了这个问题,于是推出了下面的Unicode编码
三、Unicode编码
由上一节我们可以知道,现在存在多种编码方式,我们在解码文件的时候,就一定知道其编码方式,否则解码的时候就会出现乱码。Unicode可以包括100多万的字符,每一种字符都存在唯一的编码,但是需要Unicode是字符集,而并没有规定字符的存储方式。Unicode规定每一个字符需要用3个字节或者4个字节表示,但是对于英文字符只需要一个字符表示,这种字节的浪费是不能接受的。
四、UTF-8编码
UTF-8是一种可变长的编码,字节为1~4字节,值得注意的是UTF-8与Unicode的关系是:前者是后者的一种实现方式。
UTF-8编码有两种规则:
1、对于单字节,首位BIT为0,这与ASCII保持一致,编码也与ASCII一样,完全兼容了ASCII编码
2、对于多字节,比如N个字节,第一个字节前N位为1,第N+1位为0,后续字节的前两位为10,其它全部为字符的Unicode编码。
由上可知,如果是UTF-8编码,如果首位为0,表示该字符编码占一个字节,如果首位不为0,有几个1,就表示一共占几个字节
UTF编码在windows平台下,默认带BOM(unicode协议规定的码点),比如你在记事本上编辑的代码,都会带有这个所谓的码头;这样的是不能跨平台处理的;因为Linux/Unix是不会解析这个BOM。所以建议windows开发的同学,建议使用Notepad++,并使用无BOM方式保存。
当然还有UTF-16、UTF-32等编码方式,你会发现在windows平台下,用记事本保存为UNICODE,其码值对应就是UTF-16,但是不能说在windows上unicode就是utf-16,原因前面已经说了。
四、举个例子
打开记事本,输入“中”,然后以不同的编码方式存储。
然后可以用“UE”查看各种编码下的十六进制。
UTF-8对应的十六进制:EF BB BF E4 B8 AD,前面三个字节为BOM,后面三个字节才是“中”对应的编码,转换为二进制位:111001001011100010101101
UNICODE对应的十六进制:FF FE 2D 4E,前面两个字节表示大/小端,FF FE表示是小端的存储方式,所以其码值为4E2D,转换为二进制位:100111000101101
由上面的二进制可知,UTF-8与UNICODE之间的转换,能够满足上述的规则的。
那么问题来了,GBK或者其他地区的编码如何与UNICODE进行转换呢?---codepage,所谓codepage就是各国的文字编码与UNICODE对应关系的映射表。GBK与UNICODE的codepage为936。
四、Python编码问题
终于进入主题,Python2.7中文编码的时候容易出现乱码。其原因是你提供字符的编码与默认的编码格式不一致。比如在windows平台(简中)上,cmd中断默认的编码是gdk,你在cmd中窗口中,以gdk解码成unicode是没有问题的,但是要是以utf-8进行解码,是会报错的。
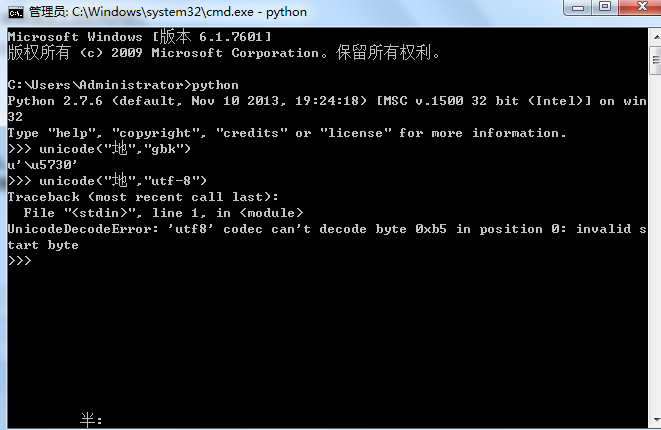
如果是在cmd下想采用utf-8的编码怎么办呢?先解码成unicode然后再采用utf-8进行编码,其他的编码转换方式类似,先解码再编码。
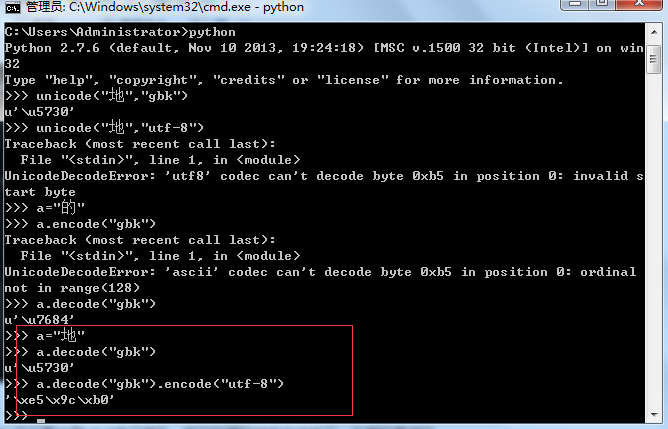
总之,在python2.7版本上,要想不乱码,就需要使文本的编码与平台默认的编码方式一致,这样就不会出现乱码了。 文中部分内容来自网络,如果涉及侵权,请联系我。