------------恢复内容开始------------
大家好,我这段时间有点忙,没有时间更新博客,这几天在学习这个scrapy的框架,学习这个新的框架,我主要是分两部分去学习,第一步通过百度搜索Scrapy框架的入门知识,第二步通过github去搜索scrapy项目,看看别人对于需求如何去做的。
第一步:掌握scrapy框架的运行原理

这张是原理图,是我在网上抓取下来的,谈谈我的理解。
爬虫抓取网页前提是跟我们平常访问网页一样, 需要发起请求,返回结果。Request这类请求网页,Response是返回结果
Scrapy框架主体是通过Spider(爬虫)为核心进展的,ItemPip(通道)理解就是需要采集的内容定义,调度器(Scheduler)理解是任务调度,一个网站包含了很多内容,需要多个爬虫去工作,需要调度器来协调
Downloader是下载器,也可以理解成处理结果数据的工具
Scrapy框架的运行业务流程
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
第二步:安装Scrapy框架
我的环境是:window10 、python3.7 、Anaconda3
pip install scrapy
安装时候经常会安装失败,需要保证安装的网络,确保可以安装完成
命令语法:
scrapy startproject 项目名称 #创建新项目,生成常规的目录结构
scrapy list #查询爬虫列表
scrapy crawl 爬虫名称 #启动爬虫
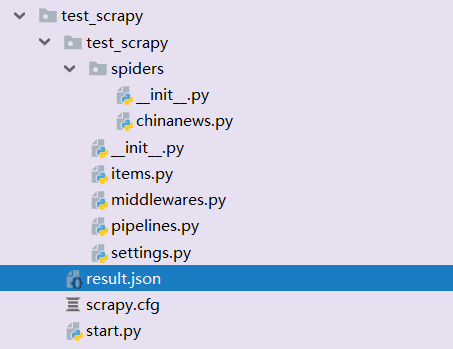
这是我创建的项目目录
spiders目录下可以根据业务需要定制不一样的爬虫。
items可以建立需要采集的数据格式
pipelines 数据的持久化处理
settings.py 配置文件 配置输出数据格式
第三步:项目实践
对于技术类型的学习,我比较崇尚实践,实践是检验真理的唯一标准。
对于初步学习的,先不要找难度高的来,先找简单的来实践一下。
目标:采集中国新闻网站,文章目录的数据,保存到json格式
项目已经生成了
第一步:我们先要定义管道Items
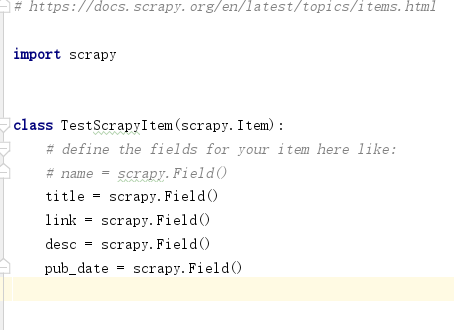
我们需要采集新闻标题、链接、描述、发布的时间,先在管道定义一下
第二步:编写爬虫,先创建一个爬虫

先要定义好采集的网络路径,切记要写对,必须加上HTTP或者HTTPS
这个链接请求出来是类目的列表,可以看看
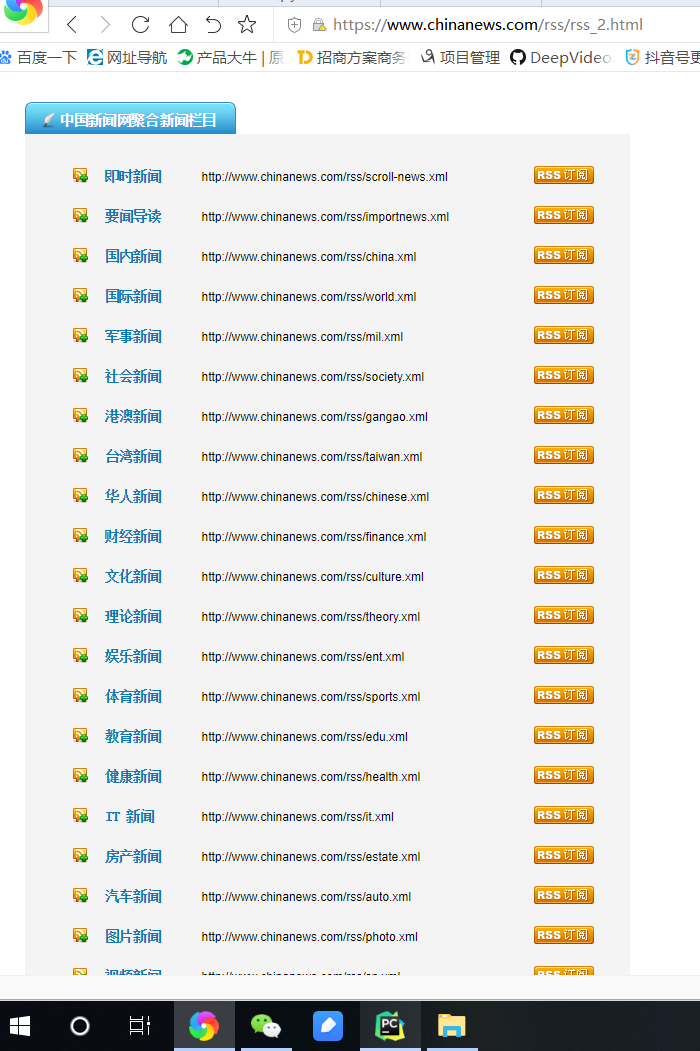
Parse方法是将类目链接找出来,通过二次访问,进入获取数据
parse_feed方式是将二次链接的访问,将需要的数据找出来
这样我们就算把爬虫写完了
我查了一下资料,将数据导出json格式也很简单,只需要配置一下就可以
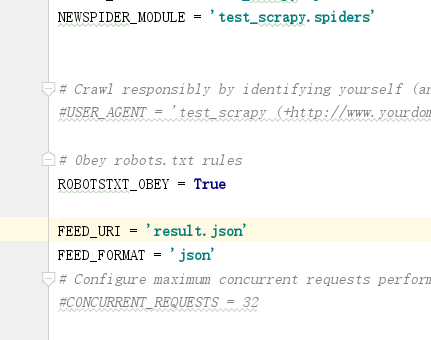
就会通过管道将JSON数据保存到本地文件

保存到遇到了一个问题,数据都乱码了,我找了一下资料,在我们通过命令的时候设置输出格式是UTF-8就可以了
'scheduler/dequeued': 33,
'scheduler/dequeued/memory': 33,
'scheduler/enqueued': 33,
'scheduler/enqueued/memory': 33,
'start_time': datetime.datetime(2019, 11, 25, 3, 19, 0, 393647)}
2019-11-25 11:19:03 [scrapy.core.engine] INFO: Spider closed (finished)
D:\Python\Study\test_scrapy>scrapy crawl chinanews -o result.json -s FEED_EXPORT_ENCODING=utf-8
正常的数据结果是:
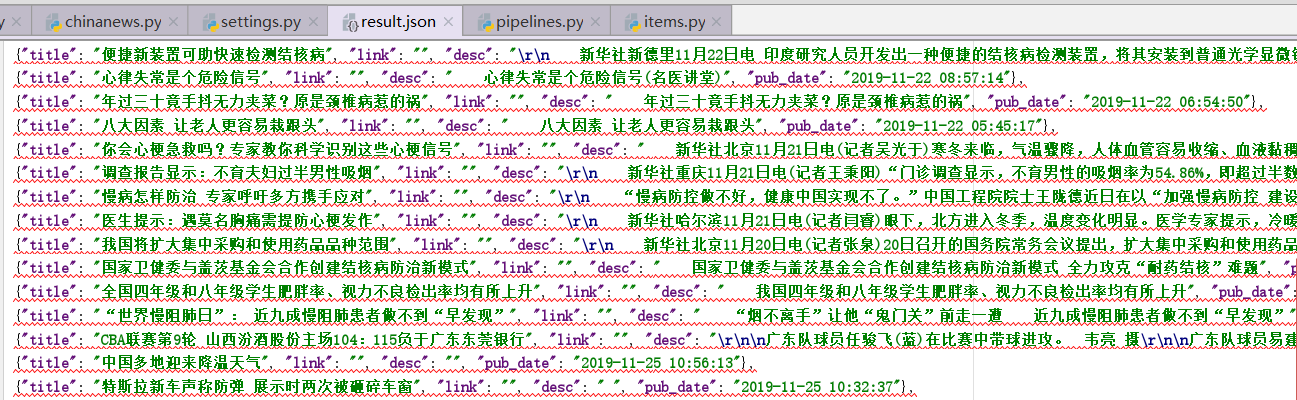
Scrapy爬虫就先学习到这到
我觉得学习任何东西都是一样,需要有一个老师,三人行必有我师,相互的学习交流,提升技术能力!
加油!