目录
1.orm表关系如何建立
1.主键
唯一字段,用于跟表中的数据形成对应关系,不能重复,不能为空
2.外键
一张表的外键是另一张表的主键,能确定另一张表记录的字段,用于保持数据的一致性,外键可以重复,
3.一对一
一种数据关系对应一种数据关系,比如:一个人只有一张身份证,一个身份证只能对应一个人
4.一对多
一种数据关系对应多种数据关系,比如:一本书只能被一个出版社出版,一个出版社可以出版多本书籍
5.多对多
多种数据关系对应多种数据关系,需要建立第三张表,比如:一个人可以写多本书,一本书也可以被多个人写
6.如何在django中创建主键外键
主键
可以自己创建,如果自己没有创建,系统会自动帮你创建
bid = models.AutoField(primary_key=True)外键
一对多:
publish_id = models.ForeignKey(to='Publish') 注意事项:

1.to 用来指代跟那张表有关系,默认关联的就是表的主键字段
2.创建的外键一般写在使用多的一方,
一对一
author_detail = models.OneToOneField(to='Author_detail')注意事项:
1.一对一外键字段,在创建的时候,同步到数据中,表字段会自动加_id后缀
2.建议写在使用多的一方
多对多:
author = models.ManyToManyField(to='Author')注意事项:
1.django会自动帮你创建第三张表,
2.多对多的时候,无论在哪一张表中写都可以,但是建议在查询频率高的一方写
3.author这个字典是一个虚拟字段,不能在表中展示出来,起到的作用仅仅是告诉orm,我需要建立第三章表
注意:使用pymysql创建数据表之后,默认的格式是latin,这个时候是不支持中文输入的,需要进行编码转换,转换方式是如下:
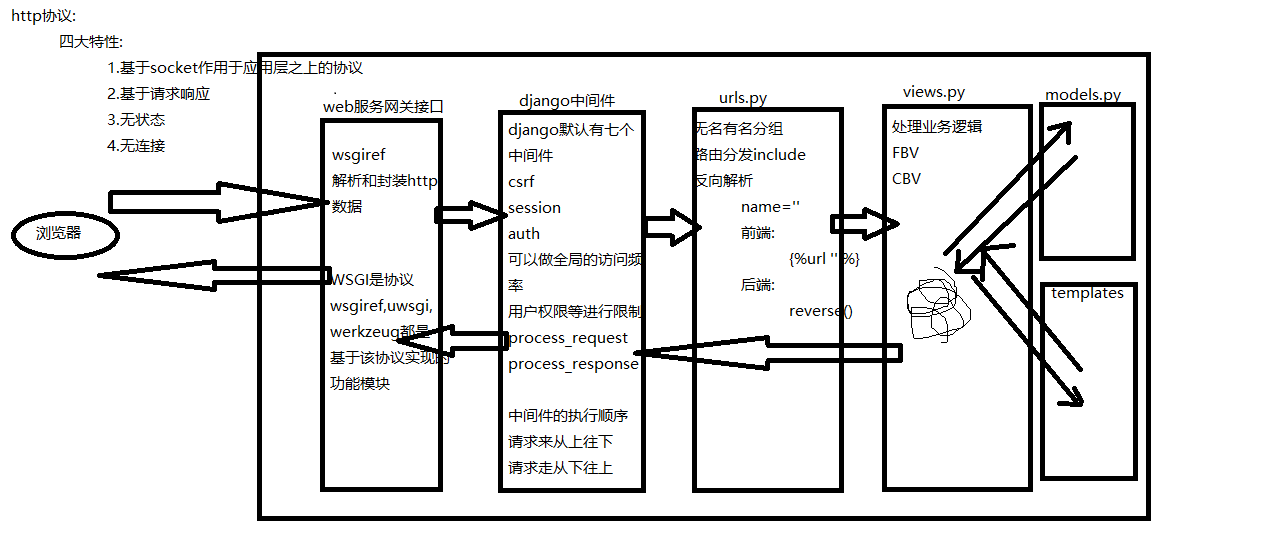
alter table `tablename` convert to charset utf8; 2.django请求生命周期流程图
可以详细的看到django的运行过程
3.urls.py路由层
1.路由层的配置
将浏览器发送过来的url请求与后端中相对应的视图函数进行对应,来调用views中的视图函数进行逻辑处理
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 登录
url(r'^test/',views.login)1.url中的第一个参数是一个正则表达式,只要这个正则表达式可以匹配到内容,就可以执行后边的视图函数
2.如果匹配到上边的有,但实际上应该匹配到的是下边的,这样就会出现匹配混乱的问题
2.正则表达式的一些基础使用
# ^ 以.....开头
# $ 以.....结尾4.路由匹配
路由匹配指的是在浏览器向服务端发送请求的时候,会将IP后面的url一起发送过来,与urls.py中的信息进行正则匹配,如果能匹配到信息,就调用views.py中的视图函数,进行处理。
APPEND_SLASH = True # 该参数默认是True,加False自动取消浏览器加斜杠功能 5.无名分组
无名分组简单的说就是没有名字的分组,正则表达式加括号表示分组,浏览器给服务端发送请求,会将浏览器中/url/后边的信息也一起发送给,如果有,就需要使用一个位置参数来进行接收。
# urls.py中 url(r'^index/(\d+)/', views.index),
# views: def index(request,args)
6.有名分组
有名分组指的是使用正则匹配到的值是以关键字的行式传进视图函数中的,需要使用一个键值对来进行接收
# urls.py中 url(r'^index/(?P<year>\d+)/', views.index),
# views: def index(request,kargs)
注意:又名分组与无名分组不能混合在一起使用,可以单独连续多个使用。
7.反向解析
反向解析是为了在使用使用路径的次数多的时候,如果更改了urls.py中的路径时,之前写的app中的路径会全部失效,为了我防止这种情况发生,可以使用反向解析来进行处理,反向解析相当于动态的提供路径,不管urls.py中的路径如何变化,html,views.py中的路径会随着urls.py中路径的改变而改变。
1.如何使用
固定路径
# 在urls.py中,设置反向解析
url(r'^login/$', views.login,name='login_page'), # 路径login/的别名为login_page
# 在views.py中,反向解析的使用:
url = reverse('login_page')
# 在模版login.html文件中,反向解析的使用
{% url 'login_page' %}
无名分组
# 针对无名分组,比如我们要反向解析出:/aritcle/1/ 这种路径,写法如下
# 在urls.py中设置反向解析
url(r'^aritcle/(\d+)/$',views.article,name='article_page'), # 无名分组
# 在views.py中,反向解析的使用:
url = reverse('article_page',args=(1,))
# 在模版login.html文件中,反向解析的使用
{% url 'article_page' 1 %}
有名分组
# 针对有名分组,比如我们要反向解析出:/user/1/ 这种路径,写法如下
# 在urls.py中设置反向解析
url(r'^user/(?P<uid>\d+)/$',views.article,name='user_page'),
# 在views.py中,反向解析的使用
url = reverse('user_page',kwargs={'uid':1})
# 在模版login.html文件中,反向解析的使用
{% url 'user_page' uid=1 %}
8.路由分发
路由分发是为了将多个app连接在一起整体使用,解决项目的总路由匹配关系过多的情况,但是存在的一个问题是如果有两个人的视图函数写的一样,这样在进行路径匹配的时候会出现匹配错误的情况,为了必满这种情况的发生,所以需要使用路由分发
2.使用方法
from app01 import urls as app01_urls
from app02 import urls as app02_urls
url(r'^app01/',include('app01.urls')),
url(r'^app02/',include('app02.urls'))
inclued函数就是一个做分发操作的函数,当接收到路径的时候,会使用正则表达式在每个路由表中进行查找。
9.名称空间
因为name=‘ ’ 本身不会产生名称空间,所以在查找的时候会按照顺序来进行查找,当查找到的时候就不再向下查找了,这样会让查找的时候出现误差匹配,
解决方法:
# 1.不使用重名的别名
# 2.
url(r'^app01/',include('app01.urls')),
url(r'^app02/',include('app02.urls'))
10.伪静态
将一个动态网页伪装成一个静态网页,一次来提高搜索引擎SEO查询频率和搜索力度
11.虚拟环境
什么是虚拟环境:一个新建的虚拟环境相当于一个新的python解释器
使用虚拟环境的目的:在写app的时候,会将python解释器中所有的库都进行加载,会造成资源浪费,使用虚拟环境,只下载自己需要的模块,在启动的时候就只会启动需要的模块。
注意点:过多的虚拟环境也会造成系统资源占用的浪费
12.django版本区别
django 1.x:urls.py中使用的是url
django 2.x:urls.py中使用的是path件
form表单传文件需要注意的事项:
1.mothod必须改成post
2.enctype改成formdata格式
前期在使用post超后端发送请求的时候,需要去settings配置文件中注释掉一个中间件crf。
# 针对于文件的操作使用的是
file_obj = request.FILES # django会将文件数据放在request.FILES中
file_obj.name
with open(file_obj.name,'wb') as f:
for line in file_obj:
f.write(line)