面向对象编程之继承
继承的定义:是一种新建类的方式,新建的类称之为子类或派生类,被继承的父类称之为基类或超类
继承的作用:子类会“”遗传”父类的属性,从而解决代码重用问题。也就是减少代码的冗余
继承的实现
继承描述的是子类与父类之间的关系,是一种什么是什么的关系。要找出这种关系,得先抽象,再继承。抽象即抽取类似或者说比较像的部分。分为以下两个方面:
- 抽取对象之间相似的部分,总结出类
- 抽取类之间相似的部分,总结出父类
语法:子类名(父类名)
# 父类
class Animal:
name = "animal"
def __init__(self, hp, attack):
self.hp = hp
self.attack = attack
# 子类
class Dog(Animal):
name = "dog"
def running(self):
print("from Animal running……")注意:
1.程序的执行顺序由上到下,父类必修定义在子类上方
2.若子类的名字与父类的名字相同,则优先使用子类的名字。
# 按照上面的代码,输出Dog类的name属性
print(Dog.name) # 输出dog
print(Animal.name) # 输出animal派生:子类继承父类属性与方法,并衍生出自己独有的属性和方法
class Dog(Animal):
name = "dog"
# 自己的属性
dog_type = "哈士奇"
# 自己的方法
def run(self):
print("dog is running……")
dog_1 = Dog(1000, 300)
print(dog_1.name, dog_1.dog_type)
dog_1.run()输出结果
dog 哈士奇
dog is running……在子类衍生出自己的独有属性值时,父类有的话,是可以直接调用,不需要在子类中再次定义,这样会造成代码冗余。也就是说,子类可以重用父类的属性,并派出新的属性。
重用父类属性的两种方式:
1.直接引用父类的__init__(),向其传参,再增加子类属性
# 第一种方式
class Cat(Animal):
# 1.直接应用父类Animal的__init__()
def __init__(self, name, hp, attack):
Animal.__init__(self, hp, attack)
# 2.新增自己特有的属性
self.name = name2.通过super来指向类的属性。super是一个特殊的类,调用supper得到一个对象,这个对象指向父类的名称空间。
# 第二种方式
class Dog(Animal):
def __init__(self, name, hp, attack):
# 使用super()时,不用传self这个参数,会自动传
super().__init__(hp, attack)
self.name = name注意:这两种方法都可以使用,但是不建议混用
在python中,子类是可以继承多个父类的,这点是其他编程语言所没有的特性
class Sports():
print("from Sports……")
class Ball():
print("from Ball")
class Football(Ball, Sports):
print("from Football……")
f = Football()
print(f)输出结果
from Sports……
from Ball
from Football……
<__main__.Football object at 0x0000029E38E9F9C8>可以发现,多重继承的情况下,对象的属性在父类中的是从左到右的.
比如说,上述代码中的 supper,严格遵循mro继承顺序。
mro调用mro返回的是一个继承序列。
为什么说不一定呢,我们来了解下新式类和经典类
新式类:凡是继承object的类或子孙类都是新式类
经典类: 没有继承object的类就是经典类
但是,在python3 中,所有的类默认继承object类,因此,python3中只有新式类
在python2中,才有经典类和新式类之分
新式类的查找顺序
# 这是个新式类,在python 3.*和python 2.* 解释器上执行
class A(object):
def test(self):
print('from A')
class B(A):
def test(self):
print('from B')
class C(A):
def test(self):
print('from C')
class D(B):
def test(self):
print('from D')
class E(C):
def test(self):
print('from E')
class F(D, E):
def test(self):
print('from F')
pass查找顺序
"""
F --> D --> B --> E --> C --> A
也就是说,当属性在F中没有,会去父类D中查找;
D中没有,去父类B中查找;
B中没有,去父类E中查找;
E中没有,去父类C中查找;
C中没有,去父类A中查找。
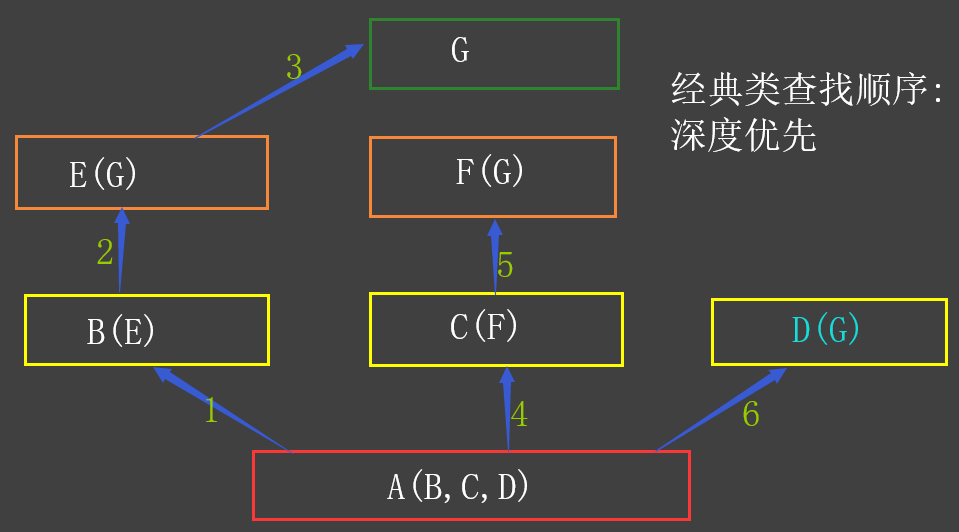
"""经典类的查找顺序
# 经典类,在python 2.* 解释器上执行
class A():
def test(self):
print('from A')
class B(A):
def test(self):
print('from B')
class C(A):
def test(self):
print('from C')
class D(B):
def test(self):
print('from D')
class E(C):
def test(self):
print('from E')
class F(D, E):
def test(self):
print('from F')
pass查找顺序
"""
F --> D --> B --> A --> E --> C
也就是说,当属性在F中没有,会去父类D中查找;
D中没有,去父类B中查找;
B中没有,去父类A中查找;
A中没有,去父类E中查找;
E中没有,去父类C中查找;
"""这是因为新式类的查找顺序是广度优先,经典类的查找顺序是深度优先
比如说,经典的钻石继承(又叫菱形继承)