最近在学习数据结构,从书上的代码示例中学习到了一种抽象的思考方式,记录一些学习二叉树的感悟
先序遍历
先序遍历相对简单,我一开实现的时候考虑了四种情况
- 左孩子为空 && 右孩子为空
访问根节点,然后出栈 - 左孩子不为空 && 右孩子为空
访问根节点,然后继续访问左孩子 - 左孩子为空 && 右孩子不为空
访问根节点,入栈右孩子,出栈 - 左孩子不为空 && 右孩子不为空
访问根节点,入栈右孩子,继续访问左孩子
template<typename Elemtype>
template<typename Fun>
bool BiTree<Elemtype>::PreOrderTraverse(Fun &visit){
Stack<BiTNode<Elemtype>*> S;
InitStack<bool,BiTNode<Elemtype>*>(S);
BiTNode<Elemtype> *p = root;
while (p != nullptr)
{
visit(p);
if(p->rChrilde != nullptr)
Push<bool,BiTNode<Elemtype>*>(S,p->rChrilde);
if(p->lChrilde != nullptr)
p = p->lChrilde;
else
//如果栈空Pop()返回false,用于判断栈空结束循环
if(!Pop<bool,BiTNode<Elemtype>*>(S,p))
p = nullptr;
}
return true;
}这种常规的做法,相信大家都有不同的实现,但是书上的示例(清华大学出版社的 数据结构(c语言版))非常简洁
template<typename Elemtype>
template<typename Fun>
bool BiTree<Elemtype>::PreOrderTraverse(Fun &visit){
Stack<BiTNode<Elemtype>*> S;
InitStack<bool,BiTNode<Elemtype>*>(S);
BiTNode<Elemtype> *p = root;
while (p || !StackEmpty<bool,BiTNode<Elemtype>*>(S)){
if (p != nullptr){
//存入栈中
Push<bool,BiTNode<Elemtype>*>(S,p);
//访问节点
visit(p);
//遍历左子树
p = p->lChrilde;
}
else{
//退栈
Pop<bool,BiTNode<Elemtype>*>(S,p);
//访问右子树
p = p->rChrilde;
}
}
return true;
}思路很简单,总结来说就是,往左走,走不通就往右走
这样一来,这个问题就被抽象成了两种情况
- 当前节点不为空
往左走 - 当前节点为空
往当前节点的根节点的右孩子走
这样整个判断情况的简单了非常多,将一个具有四种情况的问题抽象成立两种情况
这其实也是递归思想变成循环实现
中序遍历
中序遍历跟先序遍历思路几乎一样,只是访问的时间不同而已
template<typename Elemtype>
template<typename Fun>
bool BiTree<Elemtype>::PreOrderTraverse(Fun &visit){
Stack<BiTNode<Elemtype>*> S;
InitStack<bool,BiTNode<Elemtype>*>(S);
BiTNode<Elemtype> *p = root;
while (p || !StackEmpty<bool,BiTNode<Elemtype>*>(S)){
if (p != nullptr){
//存入栈中
Push<bool,BiTNode<Elemtype>*>(S,p);
//遍历左子树
p = p->lChrilde;
}
else{
//退栈
Pop<bool,BiTNode<Elemtype>*>(S,p);
//访问节点
visit(p);
//访问右子树
p = p->rChrilde;
}
}
return true;
}后序遍历
后序遍历相比之下复杂很多,因为顺序是 左 -> 右 -> 根
因为你在访问左孩子的时候,无法知道右孩子有没有,以及右孩子有没有子节点
我稍微查了一些百度上的实现方式大多如下
第一种思路:对于任一结点P,将其入栈,然后沿其左子树一直往下搜索,直到搜索到没有左孩子的结点,此时该结点出现在栈顶,但是此时不能将其出栈并访问, 因此其右孩子还为被访问。所以接下来按照相同的规则对其右子树进行相同的处理,当访问完其右孩子时,该结点又出现在栈顶,此时可以将其出栈并访问。这样就 保证了正确的访问顺序。可以看出,在这个过程中,每个结点都两次出现在栈顶,只有在第二次出现在栈顶时,才能访问它。因此需要多设置一个变量标识该结点是 否是第一次出现在栈顶。
第二种思路:要保证根结点在左孩子和右孩子访问之后才能访问,因此对于任一结点P,先将其入栈。如果P不存在左孩子和右孩子,则可以直接访问它;或者P存 在左孩子或者右孩子,但是其左孩子和右孩子都已被访问过了,则同样可以直接访问该结点。若非上述两种情况,则将P的右孩子和左孩子依次入栈,这样就保证了 每次取栈顶元素的时候,左孩子在右孩子前面被访问,左孩子和右孩子都在根结点前面被访问。(注意看他的入栈顺序,和上一种方法不一样,不是将左子树全部入栈后再转向右子树。)
转载自https://www.cnblogs.com/SHERO-Vae/p/5800363.html
但是我想到一种稍微不一样的实现方式
其实将顺序反过来看(因为栈是先进后出)根 -> 右 -> 左
有没有觉得非常眼熟?再换个方式 根 -> 左 -> 右
没错,其实是右孩子优先的 先序遍历,将访问左右孩子的的顺序调换,就可以得到这样的栈
打个比方(灵魂画图)
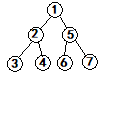
这样的右孩子优先的 先序遍历的结果为 1 5 7 6 2 4 3
反过来就是 3 4 2 6 7 5 1
这不就是后序遍历的结果了么
template<typename Elemtype>
template<typename Fun>
bool BiTree<Elemtype>::PostOrderTraverse(Fun &visit){
Stack<BiTNode<Elemtype>*> S,tmp;
InitStack<bool,BiTNode<Elemtype>*>(S);
InitStack<bool,BiTNode<Elemtype>*>(tmp);
BiTNode<Elemtype> *p = root;
while (p || !StackEmpty<bool,BiTNode<Elemtype>*>(S)){
if (p != nullptr){
//存入栈中
Push<bool,BiTNode<Elemtype>*>(S,p);
Push<bool,BiTNode<Elemtype>*>(tmp,p);
//遍历右子树
p = p->rChrilde;
}
else{
//退栈
Pop<bool,BiTNode<Elemtype>*>(S,p);
//访问左子树
p = p->lChrilde;
}
}
while (!StackEmpty<bool,BiTNode<Elemtype>*>(tmp))
{
Pop<bool,BiTNode<Elemtype>*>(tmp,p);
visit(p);
}
return true;
}
这样就可以相对简单的实现非递归的后序遍历
总结
感觉所谓算法只是思想的体现,或者说对抽象场景的判断,如果能将问题很好的抽象,那么解决的难度就会降低很多很多
btw:我还在学习c++当中,模板可能学的不是特别好,如果觉得实现复杂了求轻喷。。。