并发操作带来的问题
数据库并发操作通常会带来三个问题:丢失更新问题、读脏数据问题、不可重复读问题。
丢失更新问题
即一个事务对数据库的更新操作没有保证对其他事务可见。
例如,数据库中A的初始值为100,事务T1对A减30,事务T2对A减50,那么最后结果肯定应该是20。但按照表中进行,最后结果却是50,即丢失了事务T1对数据库的更新。
| 时间 | 事务T1 | 数据库中的值 | 事务T2 |
| t0 | 100 | ||
| t1 | FIND A | ||
| t2 | FIND A | ||
| t3 | A=A-30 | ||
| t4 | A=A-50 | ||
| t5 | UPDATE A | ||
| t6 | 70 | UPDATE A | |
| t7 | 50 |
读脏数据问题
在数据库中,把为提交的随后被撤销的数据称为“脏数据”。
例如,事务T1把A的值修改为70,但尚未提交(没做COMMIT操作),事务T2紧随着读取了未提交的A值。随后事务T1做ROLLBACK操作将A恢复成100,但事务T2还在使用被撤销了的A值70.
| 时间 | 事务T1 | 数据库中的值 | 事务T2 |
| t0 | 100 | ||
| t1 | FIND A | ||
| t2 | A=A-30 | ||
| t3 | UPDATE A | ||
| t4 | 70 | FIND A | |
| t5 | ROLLBACK | ||
| t6 | 100 |
不可重复读问题
例如:T1需要两次读取同一数据项A,但在两次读取的间隔中,另一个事务修改了A的值。因此T1在两次读取同一数据项A时却得到了不同的值。
这些问题都需要并发控制子系统来解决。通常采用封锁的技术实现。
封锁技术
排他性锁(X锁、写锁)
即Java语言中的悲观锁。如果事务T对某个数据R(可以是数据项、记录、数据集甚至是数据库)实现了X锁,那么在T对数据R解除封锁之前,不允许其他事务对改数据加任何锁。
使用X锁的操作:申请锁:XFIND R;解除锁: XRELEASE R。
过早的解除X锁,可能使其他事务获取未提交的数据(且随后被回滚),这样会造成丢失更新问题。所以在系统中不需要写解除锁语句,该语句包含在COMMIT或ROLLBACK中。
共享性锁(S锁、读锁)
X锁并发度低,只允许一个事务独锁数据。S锁允许并发读。
如果事务T对某数据R加上S锁后,仍允许其他事务再对该数据加S锁,但对该数据的所有S锁被释放之前不允许对该数据加X锁。这种锁称为S锁。
S锁不必非要合并到事务的结束操作中,可以随时根据需要解除S锁。
锁的相容矩阵
表中事务T1表示对数据做出某种封锁或者不加锁,然后T2在对同一数据请求某种封锁或者不加锁。表中Y表示相同,N表示不相容。如果两个封锁是不相容的,那么后提出封锁的事务需要等待。
| T1\T2 | X | S | -- |
| X | N | N | Y |
| S | N | Y | Y |
| -- | Y | Y | Y |
封锁的粒度
封锁对象的大小称为封锁的粒度。封锁对象可以是属性值、属性值集合、元组、关系、索引项、整个索引、整个数据库等逻辑单元,也可以是页、块等物理单元。
三级封锁协议:
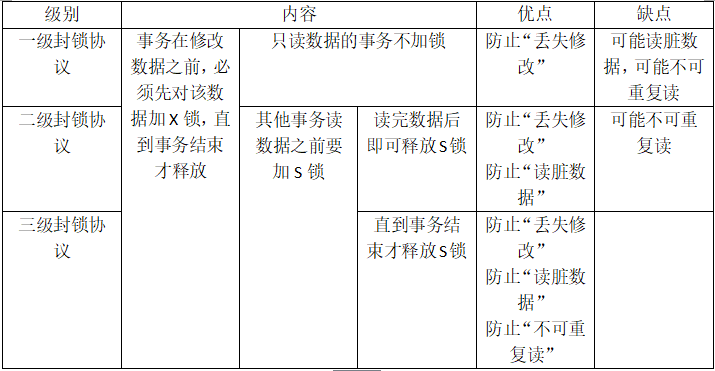
封锁带来的问题
活锁、饥饿、死锁
可以参照Java的活锁、饥饿和死锁来对比学习。
SQL对事务并发处理的支持
SQL2对事务的存取模式和隔离级别做了具体规定:
存取模式:
- READ ONLY:只读型
- READ WRITE:读写型,默认是读写型
这两种模式可以使用下列SQL语句定义:
SET TRANSACTION READ ONLY
SET TRANSACTION READ WRITE隔离级别:
SQL2提供4种隔离级别:
- SERIALIZABLE(可串行化):默认。
- REPEATABLE READ(可重复读)
- READ COMMITTED(读提交数据)
- READ UNCOMMITTED(可读取未提交数据)
SET TRANSACTION ISOLATION LEVEL 四选一