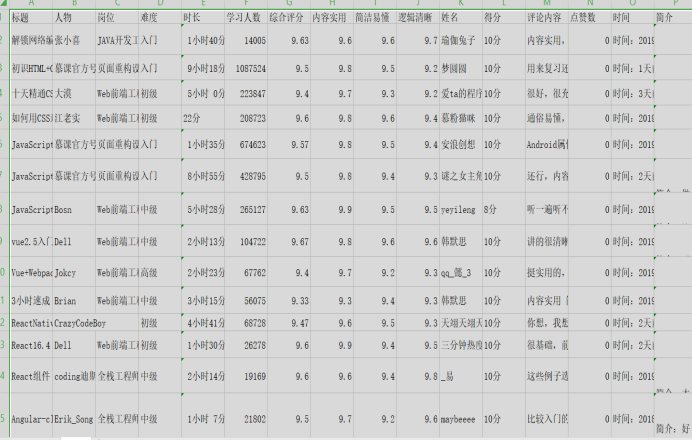
基本要求:
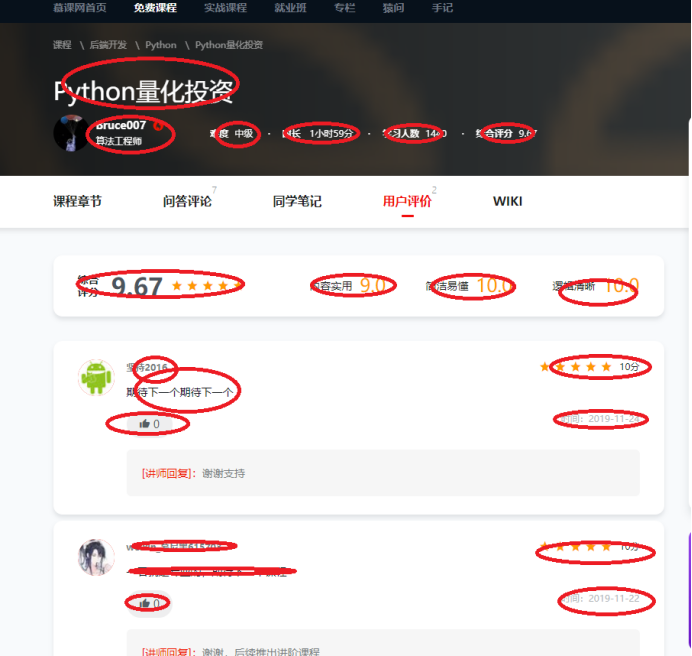
分析网页源码后:
import requests
from bs4 import BeautifulSoup
from bs4 import BeautifulSoup
import requests
import io
import sys
import csv
import re
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
f = open('abc.csv','w',encoding='gb18030',newline='')
csv_writer = csv.writer(f)
csv_writer.writerow(["标题","人物" , "岗位","难度","时长","学习人数" ,"综合评分" ,"内容实用" ,"简洁易懂" ,"逻辑清晰" ,"姓名","得分","评论内容","点赞数","时间" ,"简介"])
#open every page
def get_text(url):
res = requests.get(url)
res.encode = 'utf-8'
content = res.text
doc = BeautifulSoup(content ,'lxml')
#print(doc)
return doc
def get_page1(doc1):
pageinfo1 = doc1.find('div' ,{'class' : 'course-nav-row course-nav-skills clearfix'})
url1 = pageinfo1.findAll('a')
url2 = url1[1:]
longPage = []
for item in range(len(url2)):
attr1 = url2[item].attrs['href']
attr2 = 'https://www.imooc.com/course/list' + attr1[12:] + '&sort=pop'
#print(attr2)
longPage.append(get_text(attr2))
return longPage
#find avaliable message
def get_page(doc2):
pageinfo1=doc2.findAll('a',{'class':'course-card'});
shortTitleDoc = []
for item in range(len(pageinfo1)):
href1 = pageinfo1[item].attrs['href']
if href1[0:6] == '/learn':
href2 = 'https://www.imooc.com/coursescore' + href1[6:]
shortTitleDoc.append(get_text(href2))
if len(shortTitleDoc) == 3:
return shortTitleDoc
return shortTitleDoc
def get_introduceDoc(doc4):
pageinfo1=doc4.findAll('a',{'class':'course-card'});
shortTitleDoc2 = []
for item in range(len(pageinfo1)):
href1 = pageinfo1[item].attrs['href']
if href1[0:6] == '/learn':
href2 = 'https://www.imooc.com/learn' + href1[6:]
shortTitleDoc2.append(get_text(href2))
if len(shortTitleDoc2) == 3:
return shortTitleDoc2
return shortTitleDoc2
def get_AjaxSourceData(doc):
pageinfo1=doc.findAll('a',{'class':'course-card'});
AjaxData = []
for item in range(len(pageinfo1)):
href1 = pageinfo1[item].attrs['href']
if href1[0:6] == '/learn':
href2 = 'https://www.imooc.com/course/AjaxCourseMembers?ids=' + href1[7:]
#print(href2)
AjaxData.append(get_text(href2))
if len(AjaxData) == 3:
return AjaxData
return AjaxData
def get_page_text(shortTitleDoc ,doc5 ,AjaxData):
#顶部部分
h2 = shortTitleDoc.find('div' ,{'class':'hd clearfix'}).find('h2').text
#print(h2)
title = shortTitleDoc.find('div' ,{'class' : 'statics clearfix'})
name = shortTitleDoc.find('div' ,{'class' :'teacher-info l'})
details = shortTitleDoc.findAll('div' ,{'class' : 'static-item'})
name1 = name.find('span' ,{'class' : 'tit'}).find('a').text
job1 = name.find('span' ,{'class' :'job'}).text
metaValue = []
for item in range(4):
meta = details[item].find('span' ,{'class' : 'meta'}).text
metaValue.append(details[item].find('span' ,{'class' : 'meta-value'}).text)
#print(metaValue[0])
r = re.findall('numbers":"(.*?)"',str(AjaxData))
metaValue[2] = r[0]
#中间部分
content = shortTitleDoc.find('div' ,{'class' : 'evaluation-info'})
#a = content.find('div' ,{'class' : 'evaluation-title'}).text
score = content.find('div' ,{'class' : 'evaluation-score'}).text
li = content.findAll('li')
metaValue1 = []
for item in range(3):
metaValue1.append(li[item].find('span').text)
#评论区部分
comment = shortTitleDoc.find('div' ,{'class' : 'evaluation-list'})
commentLen = comment.findAll('div' ,{'class' : 'evaluation evaluate'})
#print(len(commentLen))
commentName = commentLen[0].find('a' ,{'class' : 'username'}).text
commentScore = commentLen[0].find('div' ,{'class' : 'star-box'}).find('span').text
commentContent = commentLen[0].find('p' ,{'class' : 'content'}).text
commentPraise = commentLen[0].find('div' ,{'class' : 'info clearfix'}).find('em').text
commentTime = commentLen[0].find('span' ,{'class' : 'time'}).text
content1 = doc5.find('div' ,{'class' :'course-description course-wrap'}).text
csv_writer.writerow([h2 ,name1 ,job1 ,metaValue[0] ,metaValue[1] ,metaValue[2] ,metaValue[3] ,metaValue1[0] ,metaValue1[1] ,metaValue1[2],commentName,commentScore,commentContent,commentPraise,commentTime ,content1])
doc3 = get_text('https://www.imooc.com/course/list')
longPage1 = get_page1(doc3)
for item in range(len(longPage1)):
shortTitleDoc1 = get_page(longPage1[item])
shortTitleDoc3 = get_introduceDoc(longPage1[item])
AjaxData = get_AjaxSourceData(longPage1[item])
for i in range(len(shortTitleDoc1)):
get_page_text(shortTitleDoc1[i] ,shortTitleDoc3[i] ,AjaxData[i])
#get_introduce(shortTitleDoc3[i])
#print(len(shortTitleDoc1))
f.close()
结果保存在CSV表格当中(部分数据)