关于scrapy-redis的代码大家自行下载学习即可。

![]()
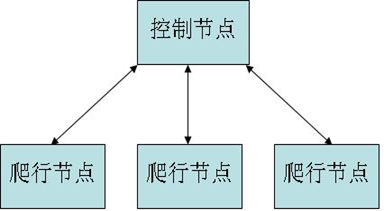
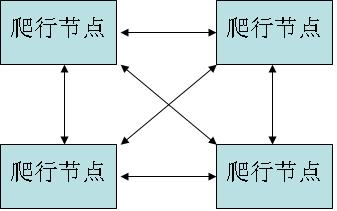












操作redis实例:
import redis
r = redis.Redis(host = 'localhost', port = 6379, db = 1)
r.set('k1', 'v1')
r.set('k2', 'v2')
print(r.get('k1'))
print(r.keys())
print(r.dbsize())
r.delete('k2')
print(r.keys())
print(r.dbsize())
print(dir(r))
#pipeline
p = r.pipeline()
p.set('k3', 'v3')
p.set('k4', 'v4')
p.incr('num')
p.incr('num')
p.execute()
print(r.get('num'))
import redis
class Task:
def __init__(self):
self.rcon = redis.Redis(host = 'localhost', db = 5)
self.queue = 'task:prodcons:queue'
def process_task(self):
while True:
task = self.rcon.blpop(self.queue, 0)[1]
print('Task: ', task)
Task().process_task()
import redis
class Task:
def __init__(self):
self.rcon = redis.Redis(host = 'localhost', db = 5)
self.ps = self.rcon.pubsub()
self.ps.subscribe('task:pubsub:channel')
def process_task(self):
for i in self.ps.listen():
if i['type'] == 'message':
print('Task: ', i['data'])
Task().process_task()