每个输出节点与全部的输入节点相连接,这种网络层称为全连接层,本质上是矩阵的相乘和相加运算;
由神经元相互连接而成的网络叫做神经网络,每一层为全连接层的网络叫做全连接网络;
6.5解释了为什么预处理数据到0-1才合适的原因。
影响汽车的每加仑燃油英里数的有气缸数,排量,马力,重量,加速度,生产低和年份
其中有如下关系

与书上图6.16对应,但第四个图找不到是什么!
预测的神经网络如下:
# encoding: utf-8 import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers, Sequential import pandas as pd import matplotlib.pyplot as plt # input data dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/" "machine-learning-databases/auto-mpg/auto-mpg.data", cache_dir='G:\2019\python\auto-mpg.data') colum_names = ['MPG', 'Cylinder', 'Displacement', 'Horsepower', 'Weight', 'Acceleration', 'Model Year', 'Origin'] # 398行数据,8列 raw_dataset = pd.read_csv(dataset_path, names=colum_names, na_values="?", comment='\t', sep=" ", skipinitialspace=True) # data process dataset = raw_dataset.copy() dataset.head() dataset.isna().sum() dataset = dataset.dropna() dataset.isna().sum() # dataset.shape = (392, 8) # 拓展dataset到10列 origin = dataset.pop('Origin') # (392, 1)得到产地 dataset['USA'] = (origin == 1) * 1.0 dataset['Europe'] = (origin == 2) * 1.0 dataset['Japan'] = (origin == 3) * 1.0 dataset.tail() # dataset.shape = (392, 10) 后三列换成三个产地,每列用0,1表示是否 # 获取训练集和测试集 train_dataset = dataset.sample(frac=0.8, random_state=0) # (314, 10) test_dataset = dataset.drop(train_dataset.index) # (78, 10) train_labels = train_dataset.pop('MPG') # (314, 1) 取出带标签“MPG”的第一列 test_labels = test_dataset.pop('MPG') # (78, 1) # 做统计 train_stats = train_dataset.describe() # (8, 9)获取一列数据的均值、标准差、最大值、最小值等 train_stats = train_stats.transpose() # (9, 8) 转置功能 # 标准化函数 def norm(x): return (x - train_stats['mean']) / train_stats['std'] # 训练集、测试集标准化 normed_train_data = norm(train_dataset) # (314, 9)数据-1:1之间 normed_test_data = norm(test_dataset) # (78, 9) print(normed_train_data.shape, train_labels.shape) # 展示最终输入的模型 print(normed_test_data.shape, test_labels.shape) #切分训练集、测试集 train_db = tf.data.Dataset.from_tensor_slices((normed_train_data.values, train_labels.values)) train_db = train_db.shuffle(314).batch(32) test_db = tf.data.Dataset.from_tensor_slices((normed_test_data.values, test_labels.values)) test_db = test_db.shuffle(78).batch(13) # 观察原始数据之间的关系 def Draw(): MPG = dataset.pop('MPG') Cylinder = dataset.pop('Cylinder') Displacement = dataset.pop('Displacement') Weight = dataset.pop('Weight') Horsepower = dataset.pop('Horsepower') Acceleration = dataset.pop('Acceleration') ModelYear = dataset.pop('Model Year') plt.figure() plt.subplot(131) plt.plot(Cylinder, MPG, 'bo') plt.xlabel('Cylinders') plt.ylabel('MPG') plt.subplot(132) plt.plot(Displacement, MPG, 'bo') plt.xlabel('Displacement') plt.ylabel('MPG') plt.subplot(133) plt.plot(Weight, MPG, 'bo') plt.xlabel('Weight') plt.ylabel('MPG') plt.savefig('three_fig_auto-MPG.png') plt.show() # 特征之间两两分布 Draw() # 创建网络 class Network(keras.Model): def __init__(self): # 回归网络模型 super(Network, self).__init__() self.fc1 = layers.Dense(64, activation='relu') # 输出64个节点 self.fc2 = layers.Dense(64, activation='relu') self.fc3 = layers.Dense(1) def call(self, inputs, training=None, mask=None): # 创建3个全连接层 x = self.fc1(inputs) x = self.fc2(x) x = self.fc3(x) return x model = Network() # 创建网络实例 model.build(input_shape = (4, 9)) # 完成内部张量的创建,4为任意设置的batch数,9为输入特征长度 model.summary() # 打印网络信息 optimizer = tf.keras.optimizers.RMSprop(0.001) # 创建优化器,指定学习率 # 保存训练和测试过程中的误差情况 train_tot_loss = [] train_tot_mae = [] test_tot_loss = [] test_tot_mae = [] for epoch in range(200): for step, (x, y) in enumerate(train_db): with tf.GradientTape() as tape: # 梯度记录器 out = model(x) # 通过网络获取输入 loss = tf.reduce_mean(tf.losses.MSE(y, out)) # 计算MSE mae_loss= tf.reduce_mean(tf.losses.MAE(y, out)) # 计算MAE if step % 10 == 0: print(epoch, step, float(loss)) train_tot_loss.append(float(loss)) train_tot_mae.append(float(mae_loss)) # 更新梯度 grads = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(grads, model.trainable_variables)) # 测试 if step % 10 == 0: test_loss, test_mae_loss = 0, 0 for x, y in test_db: test_out = model(x) test_loss = tf.reduce_mean(tf.losses.MSE(y, test_out)) test_mae_loss = tf.reduce_mean(tf.losses.MAE(y, test_out)) print(epoch, step, float(test_loss)) test_tot_loss.append(float(test_loss)) test_tot_mae.append(float(test_mae_loss)) plt.figure() plt.plot(train_tot_mae, 'b', label = 'train') plt.plot(test_tot_mae, 'r', label = 'test') plt.xlabel('Step') plt.ylabel('MAE') plt.legend() plt.savefig('train_test_auto-MPG.png') plt.show()
训练和测试误差如下:
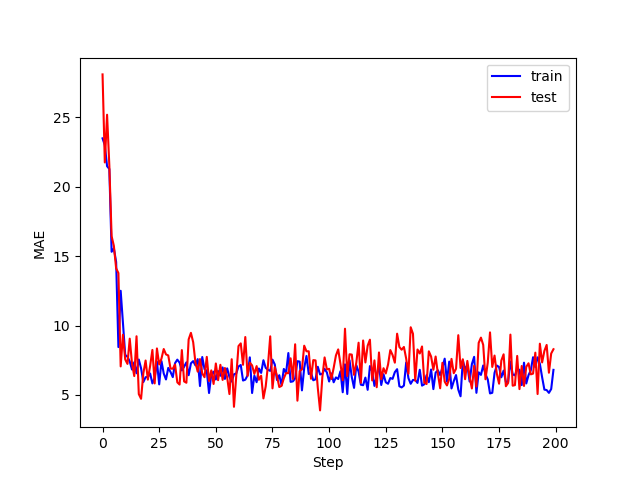
有波动与书上很光滑不太一致,总体趋势是一致的!
注意:(1)警告:tensorflow:Layer network正在将输入张量从dtype float64转换为该层的dtype float32,这是tensorflow 2中的新行为。
未解决这个警告!
下次更新反转传播算法,Himmelbla函数优化与二分类全连接网络