1 感知机是二分类的线性模型,输入空间是实例的特征向量,输出是实例的类别(+1,-1),属于判别模型。
2 假设数据线性可分,感知机的学习目标是求得一个能够将训练集数据正例和负例完全分开的分离超平面,如果训练数据线性不可分,那么就无法获得这个超平面(抑或问题),针对抑或问题,解决方法是多层感知机组合。
3 输入空间到输出空间:
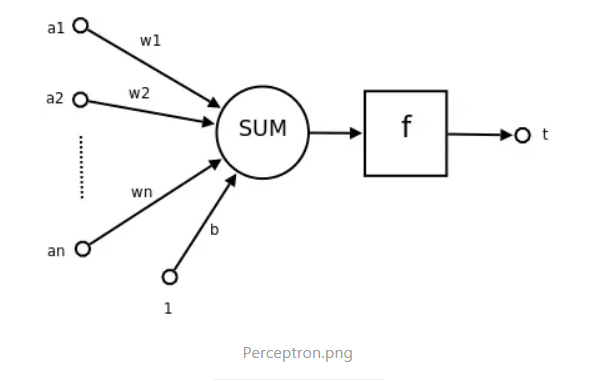
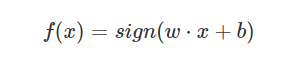
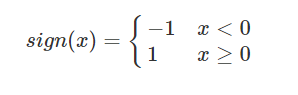
4 损失函数得优化目标:是所有误分类的样本点到分离超平面的距离和最小
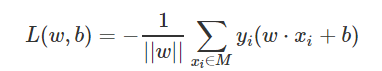
其中M是误分类样本的集合。
一般情况下会省略掉前面的常数项,所以损失函数为
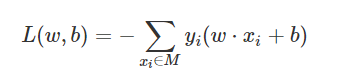
为什么能省略掉常数项系数
① 对中间计算过程和最终的分类结果都不会产生影响(误分类样本驱动,不影响正负值)
② 简化计算,提高算法执行效率
5 感知机算法是通过误分类的样本参与损失函数的优化,所以不能采用批量梯度下降(BGD),得采用随机梯度下降(SGD),目标函数:
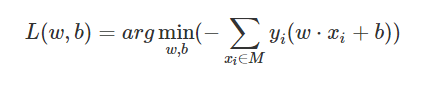
实际应用中采用对偶形式进行梯度更新。
参考资料: