本篇文章会详细讲解pyecharts制作图表以及pandas的基本使用。
相信看了文章后你定能够有以下收获:
1.熟练运用python可视化神器pyecharts绘制图表。
2.熟练运用pandas对excel表格文档的基本操作。
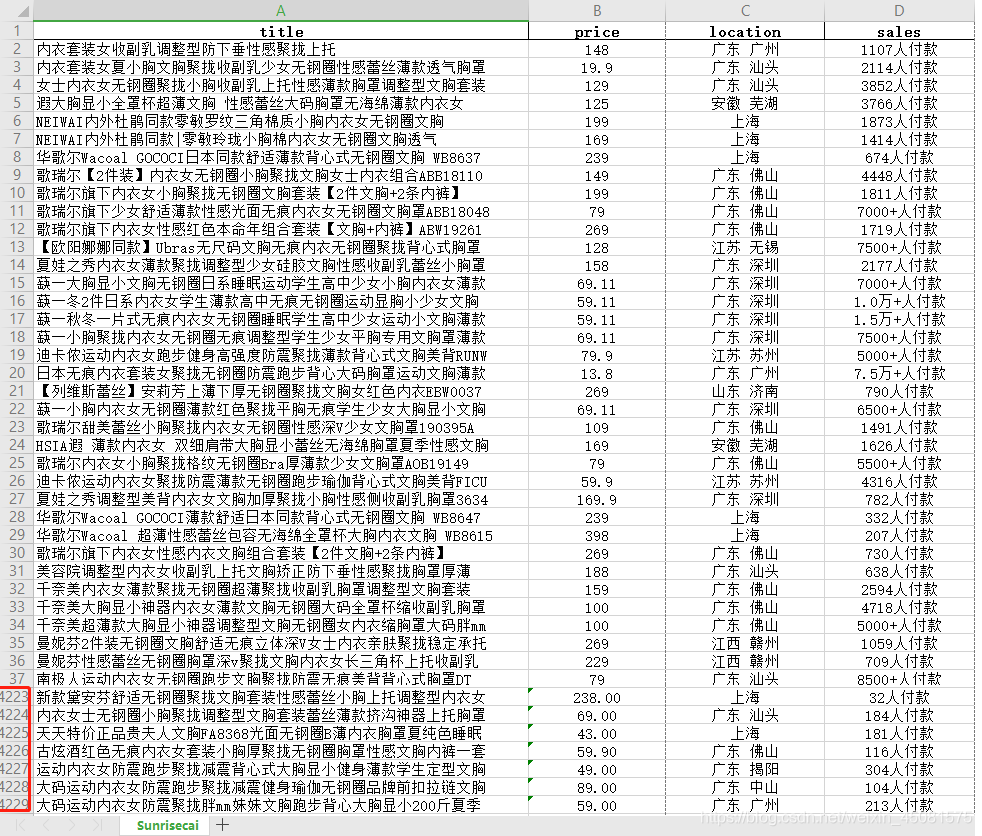
1.数据文档
本文章用以下保存在excel表格中的4200份商品数据做展示。(需要该数据的在下方留下你的邮箱)
2.项目环境
本文章主要用到胖大师–pandas 和 可视化神器–pyecharts 以及 结巴(jieba)分词这三个模块。
虽然excel表格可以实现上面的图表制作,但是在这里我们不用excel表格,别问为什么,问就是 Life is short, you need Python
| 模块名 | 在本文章中的作用 |
|---|---|
| jieba | 分词、提取关键词用 |
| pandas | 处理excel表格文档以及处理数据 |
| pyecharts | 制作图表(柱状图、饼图、地图热力图等) |
2.1模块安装
pip默认使用国外的源文件,下载超慢的,速率能达到50kb/s你就要偷笑了。所里这里更换为国内源。
pip install jieba -i https://pypi.douban.com/simple # '-i为指定下载的源'
pip install pandas -i https://pypi.douban.com/simple
pip install pyecharts -i https://pypi.douban.com/simple
| 模块 | 功能 |
|---|---|
| jieba | 关键词抽取 |
| pandas | 处理数据 |
| pyecharts | 绘制图表 |
2.2模块简介
jieba简介

基本使用:
- 基于 TextRank 算法的关键词抽取
主要传入需要过滤的 一个文本**(可不传)** 和 需要提取关键词的句子即可。
import jieba.analyse
def analyse_test():
"""
sentence为需要抽取关键字的句子, topK为权重最大的关键词,默认值为20
withWeight为返回权重值,默认为False,即后面的数值
:return:
"""
# 载入停用词,即过滤词
# jieba.analyse.set_stop_words('你需要过滤掉的词和符号的txt文本')
keyword = jieba.analyse.textrank("语文语文语文数学数学英语政治历史地理物理化学生物", topK=5, withWeight=True)
print(keyword)
analyse_test()
# [('数学', 1.0), ('语文', 0.9297002148232134), ('政治', 0.6325439509017233), ('历史', 0.5632028846426907), ('地理', 0.4924447844489272)]
pandas简介
胖大师是常会用到的一个模块。pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
- 基本使用:
代码部分下面会用到的pandas对excel表格文档的操作:
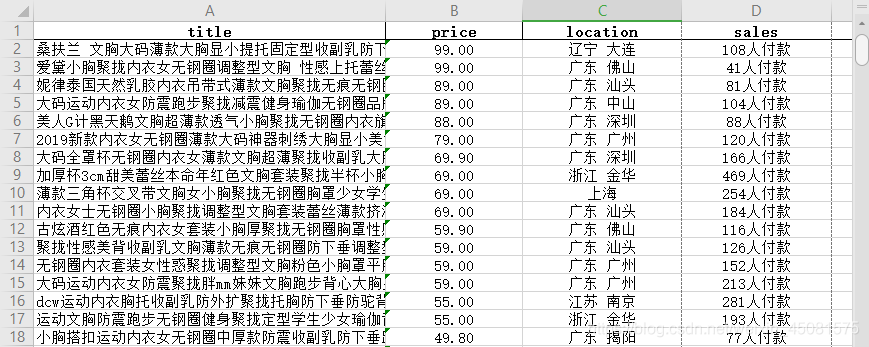
以以下文档为例:
- 当然了,这一份文件是需要经过处理才行的!但是这点小东西留给大家自己处理。
- location列只需要提取前面的省份,
- sales列只需要提取付款数量,不需要后面的人付款
import pandas as pd
df = pd.read_excel(excel文档)
df.title # df.title等同于df['title'] ,获取title列的所有内容
df['data'].values # 获取title列的值
df.title.value_counts() # 查看title列的每个不同值在该列有多少重复值
df.title.value_counts().items() # 查看title列的每个不同值在该列有多少重复值,以元组输出
df.title.reset_index() # 可以还原索引,重新变为默认的整型索引
df.iterrows() # 获取文档所有行,以元组形式输出
# x是传入数组,bins整数、序列尺度、或间隔索引,labels是切割后的标签,
df.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates='raise')
# x是传入数组,q为需要分割多少份
df.qcut(x,q,labels = None,retbins = False,precision = 3,重复项='raise' )
# 两者功能相似,都是将一个Series切割成若干个分组
# qcut 是等频切割,即基本保证每个组里的元素个数是相等的
# cut是按值切割,即根据数据值的大小范围等分成n组,落入这个范围的分别进入到该组。
-------------------------------------------------------------------------
df['group'] = pd.qcut(df.price, 10) # 将价格分割为10组,赋值给 group列
df.groupby('group').mean() # 按group列分组,获取其他列的均值
pyecharts简介

- 基本使用:
这个pyecharts使用起来相对简单,这里不做过多介绍,官方文档:https://pyecharts.org/#/zh-cn/intro。
值得一提的是 pyecharts制作图表的数据大部分都是以列表形式传入。
3.常用图表制作
这里主要讲解4个常见的图表制作,分别是词云、柱状图、饼图、地图热力图
导入模块与文件
import pandas as pd
import jieba.analyse
from pyecharts.faker import Faker
from pyecharts import options as opts
from pyecharts.globals import ThemeType
from pyecharts.globals import SymbolType
from pyecharts.charts import Pie, Bar, Map, WordCloud
# Pie为饼图接口、Bar为柱状图接口、Map为地图热力图接口、WordCloud为词云接口
stop_words_txt = '过滤词.txt' # 过滤词
df = pd.read_excel('Excel文档') # 读取标准数据
3.1 词云
高频词汇词云

词云代码
def wordcloud_() -> WordCloud:
jieba.analyse.set_stop_words(stop_words_txt) # 载入停用词,即过滤词
# 'topK为返回权重最大的关键词,默认值为20,withWeight为返回权重值,默认为False'
keyword_list = jieba.analyse.textrank(' '.join(df.title), topK=88, withWeight=True)
# 1. 高频词汇词云
word_cloud = (
WordCloud()
# '传入列表,word_size_range为字体大小,shape为词云的形状'
.add("", keyword_list, word_size_range=[15, 100], shape=SymbolType.TRIANGLE)
.set_global_opts(title_opts=opts.TitleOpts(title="Bra商品标题词云Top88"))
)
word_cloud.render() #'默认在当前目录生成一个render.html,也可以自定义文件名称'
3.2 柱状图
柱状图

柱状图代码
def bar_():
# 'df.location.value_counts().items()获取location列的每个不同值在该列有多少重复值'
store_location_num_tuple = df.location.value_counts().items()
store_location_num = (dict(store_location_num_tuple))
# {'广东': 2426, '上海': 560, '浙江': 435, '福建': 240......}
bar = (
Bar()
.add_xaxis(list(store_location_num.keys())) # 传入X轴的值(列表)
.add_yaxis('SunrisrCai', list(store_location_num.values())) # 传入Y轴的值(列表)
.set_global_opts(title_opts=opts.TitleOpts(title='商家分布柱状图'),
xaxis_opts=opts.AxisOpts(name='城市'),
yaxis_opts=opts.AxisOpts(name='数量'))
)
bar.render('SunriseCai.html') # '在当前页面生成文件SunriseCai.html'
XY轴翻转柱状图
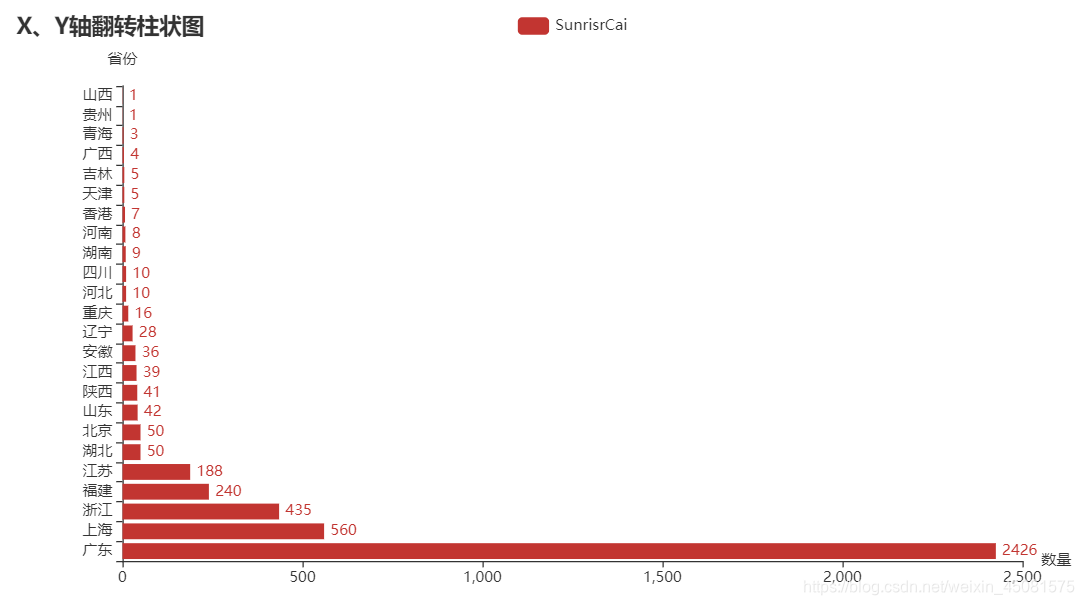
XY轴翻转柱状图代码
加入两行代码即可实现XY轴翻转
def bar_():
# 'df.location.value_counts().items()获取location列的每个不同值在该列有多少重复值'
store_location_num_tuple = df.location.value_counts().items()
store_location_num = (dict(store_location_num_tuple))
# {'广东': 2426, '上海': 560, '浙江': 435, '福建': 240......}
bar = (
Bar()
.add_xaxis(list(store_location_num.keys())) # 传入X轴的值(列表)
.add_yaxis('SunrisrCai', list(store_location_num.values())) # 传入Y轴的值(列表)
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title='商家分布柱状图'),
xaxis_opts=opts.AxisOpts(name='数量'),
yaxis_opts=opts.AxisOpts(name='省份'))
)
bar.render('SunriseCai.html') # '在当前页面生成文件SunriseCai.html'
3.3 区间 柱状图
区间柱状图一
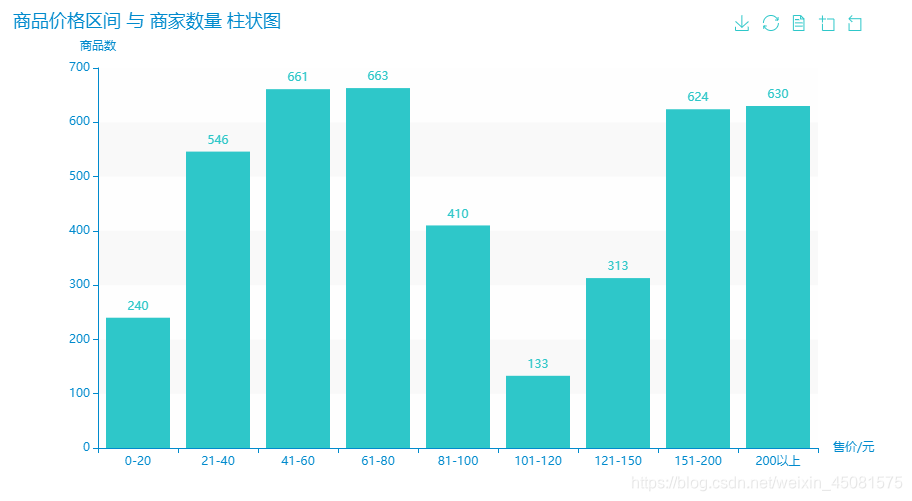
区间柱状图代码一
def bar_():
# 'bins是切割后的区间,labels是切割后的标签,include_lowest为第一个区间的左端点是否包含'
bin = [0, 20, 40, 60, 80, 100, 120, 150, 200, 1000]
labels = ['0-20', '21-40', '41-60', '61-80', '81-100', '101-120', '121-150', '151-200', '200以上']
data_lables_list = pd.cut(df.price, bins=bin, labels=labels, include_lowest=True)
print(data_lables_list) # ['121-150', '0-20', '121-150', '121-150', '151-200'......]
# '建立字典,键为返回的区间值,值为0,遍历,如果相等则 +1'
bin_data = {data: 0 for data in labels}
for data in data_lables_list:
for keyword in bin_data:
if data == keyword:
bin_data[keyword] += 1
print(bin_data) # {'0-20': 240, '21-40': 546, '41-60': 661, '61-80': 663......}
bar = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.MACARONS)) # 设置柱状图的格式,有多种格式可选
.add_xaxis(list(bin_data.keys())) # 传入X轴的值(列表)
.add_yaxis("", list(bin_data.values())) # 传入Y轴的值(列表)
.set_global_opts(
title_opts=opts.TitleOpts(title="商品价格区间 与 商家数量 柱状图"),
yaxis_opts=opts.AxisOpts(name="商品数"),
xaxis_opts=opts.AxisOpts(name="售价/元"))
)
bar.render('SunriseCai.html') # '在当前页面生成文件SunriseCai.html'
区间柱状图二
这种情况是出现在,图表需要的值都在excel表格文档里面。
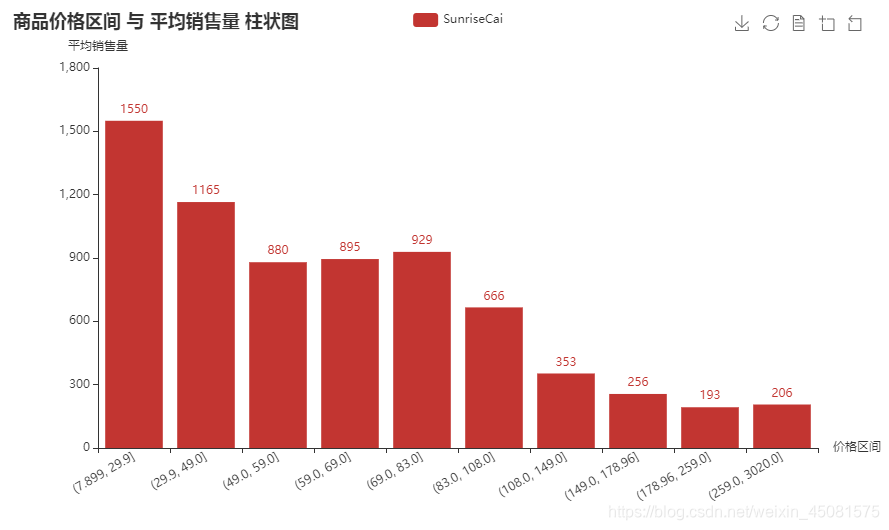
区间柱状图二代码
def bar_():
# 'df的price列分割为10组,赋值给 new_group列'
# 'df.groupby('new_group').mean()是以new_group列分组,获取其他列的均值'
df['new_group'] = pd.qcut(df.price, 10)
df_group_all = df.groupby('new_group').mean()
bar = (
Bar()
# 'df_group_all.new_group为new_group的数据,需要转换为字符串,否则不能识别'
.add_xaxis(list(str(price) for price in df_group_all.new_group))
.add_yaxis('SunriseCai', list(sale for sale in df_group_all.sales)) # 传入Y轴的值(列表)
.set_global_opts(title_opts=opts.TitleOpts(title="商品价格区间 与 平均销售量 柱状图"),
xaxis_opts=opts.AxisOpts(name='价格区间(单位/元)', axislabel_opts={"rotate": 30}),
yaxis_opts=opts.AxisOpts(name='平均销售量'))
)
bar.render('SunriseCai.html') # '在当前页面生成文件SunriseCai.html'
3.4 饼图
饼图
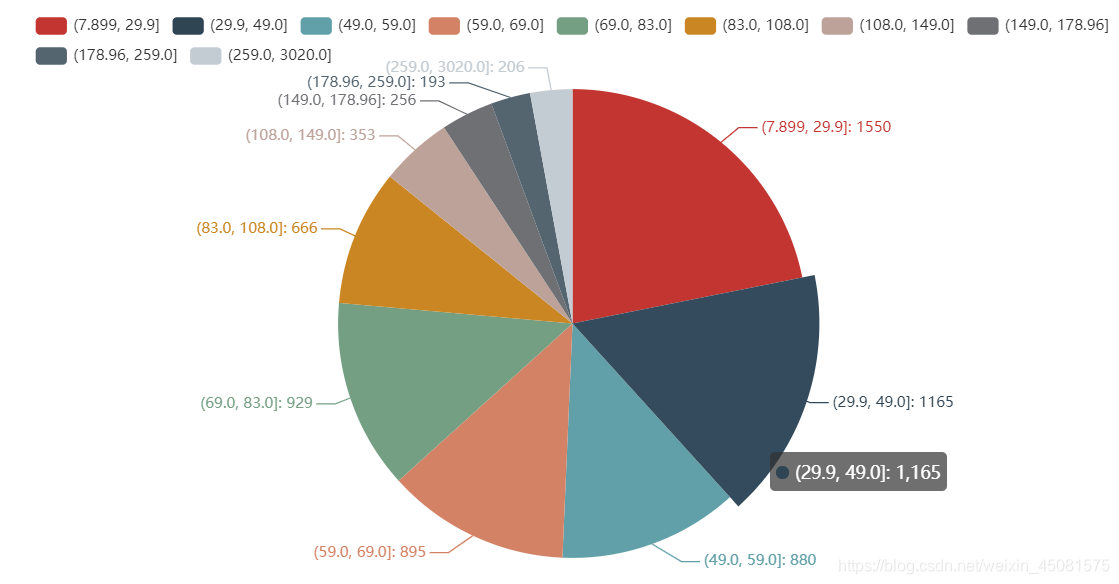
饼图代码
def price_bin_avg():
df = DF_STANDARD
df['new_group'] = pd.qcut(df.price, 10)
df_group_all = df.groupby('new_group').mean().reset_index()
lables = [str(data) for data in df_group_all.new_group]
values = [int(data) for data in df_group_all.sales]
pie = (
Pie()
# 以[(lable,value),(lable,value),(lable,value)......]形式传入数据。
.add("SunriseCai", list(z for z in zip(lables, values)))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render('SunriseCai.html') # '在当前页面生成文件SunriseCai.html'
3.5 地图热力图
地图热力图
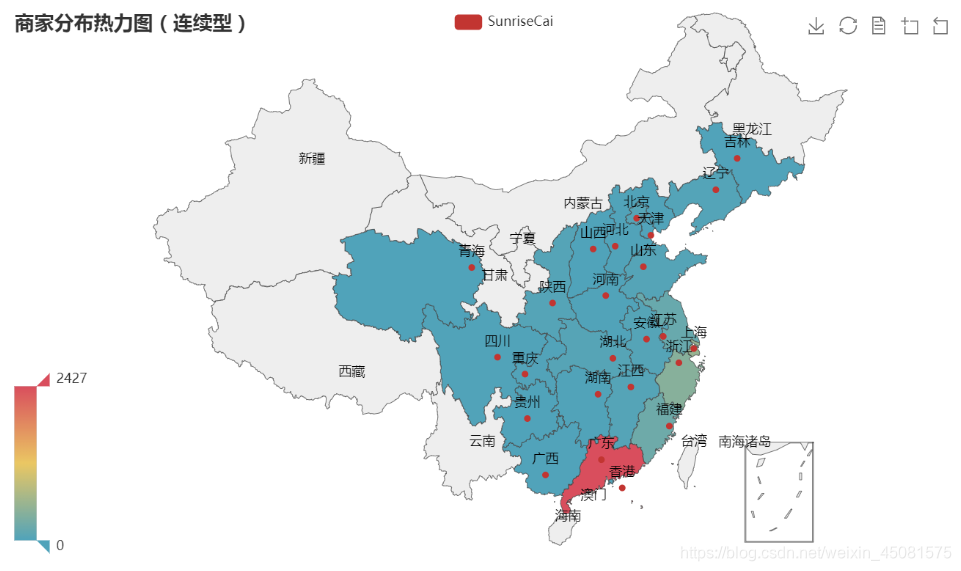
地图热力图代码
def map_():
# df.location.value_counts().items()获取location列的每个不同值在该列有多少重复值
store_location_num_tuple = df.location.value_counts().items()
store_location_num = (dict(store_location_num_tuple))
# {'广东': 2426, '上海': 560, '浙江': 435, '福建': 240......}
map_ = (
Map()
# 添加标题,传入列表数据[('广东', 2426), ('上海', 560), ('浙江', 435)...]
# 'china为中国地图,国外土地如何使用还请查看官方文档,这里不做展示'
.add("SunriseCai", [(data) for data in store_location_num.items()], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="商家分布热力图(连续型)"),
visualmap_opts=opts.VisualMapOpts(max_=2427)) #'这里设置最大值,如果超过则不显示'
)
map_.render('SunriseCai.html') # '在当前页面生成文件SunriseCai.html'
4.最后的话
更详细的图表制作尽在官方文档:https://pyecharts.org/#/zh-cn/intro
由上面可见,学好pandas是真的很有用,同时学习一些可视化的工具如pyecharts,因为他们可以将你的数据转变成图表变成可以看得到的数据给展示出来,在学习、工作中,是会为你加分的。
好了,本次文章的分享到此结束,有任何问题欢迎在下方留言。
有需要该文章中的4200多份商品数据的,在下方留言里留下你的邮箱即可。我会将代码以及商品数据打包发送给你。
