此博客仅为我业余记录文章所用,发布到此,仅供网友阅读参考,如有侵权,请通知我,我会删掉。
注:因初接触python爬虫,代码和思路差劲的地方请见谅。
爬虫四个步骤:1.请求网页 2.获取网页响应 3.解析网页 4.保存数据
1.解析网页
1.首先我们来看一下猫眼电影top100的 url
https://maoyan.com/board/4?offset=0 #第一页
https://maoyan.com/board/4?offset=10 #第二页
https://maoyan.com/board/4?offset=20 #第三页
...
...
https://maoyan.com/board/4?offset=90 #第十页
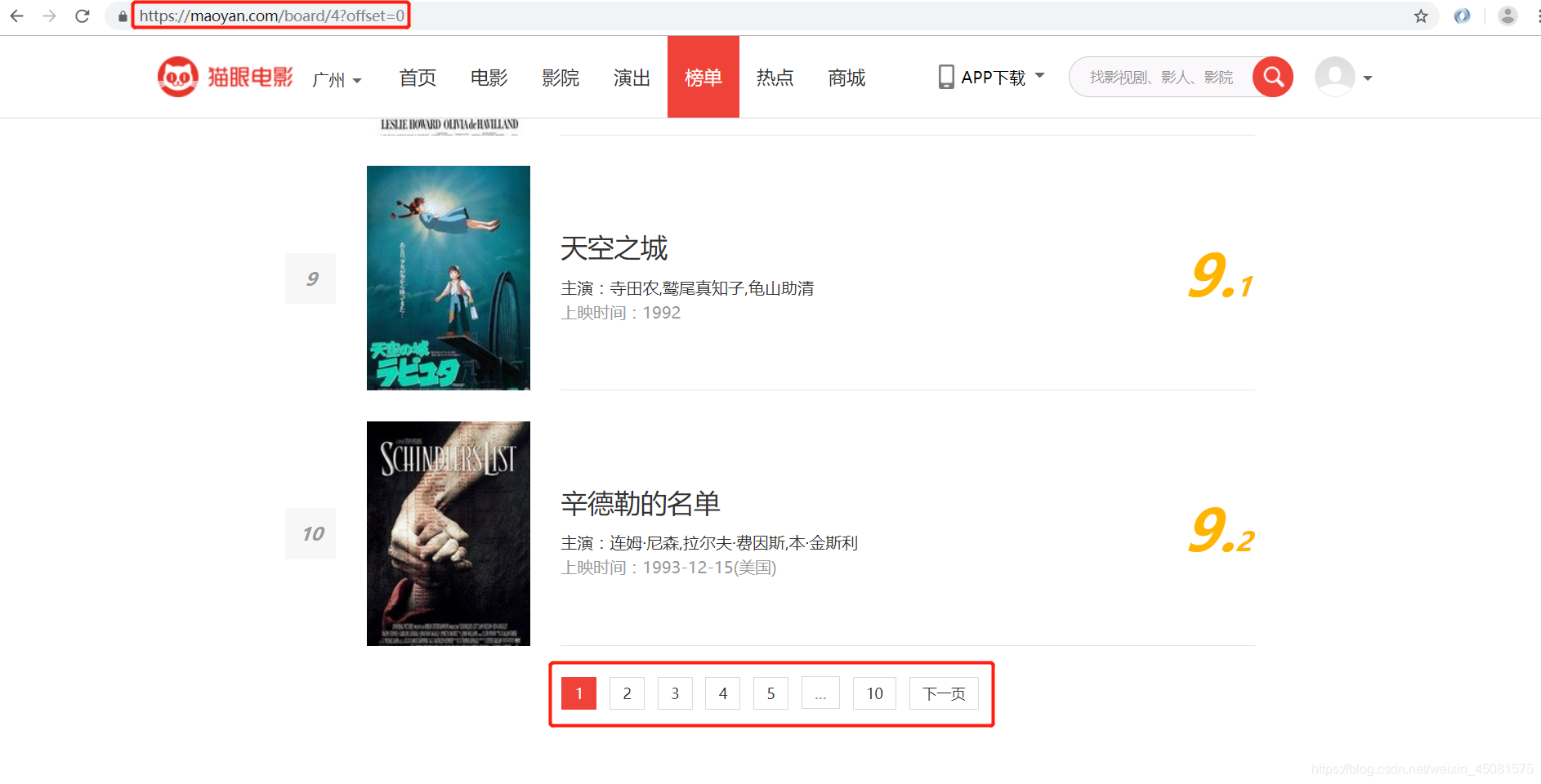
2.通过观察url可以发现,url的变化点就在 offset=这里,每个页面有10个电影,每一页递增10,清楚url的规则后,接下来我们就可以请求网页进行分析了。
# 请求url,因为一页有10个电影,共10页。这里用一个for函数取10个数字
for i in range(10):
url = 'https://maoyan.com/board/4?offset=%s' % (i*10)
# 网页响应,requests.get表示请求获取网页,text一般用于返回的文本
response = requests.get(url).text
查看获取到response,也就是网页源代码,这里我们主要爬取画圈圈的五个点。主要用到正则表达式提取所需的内容
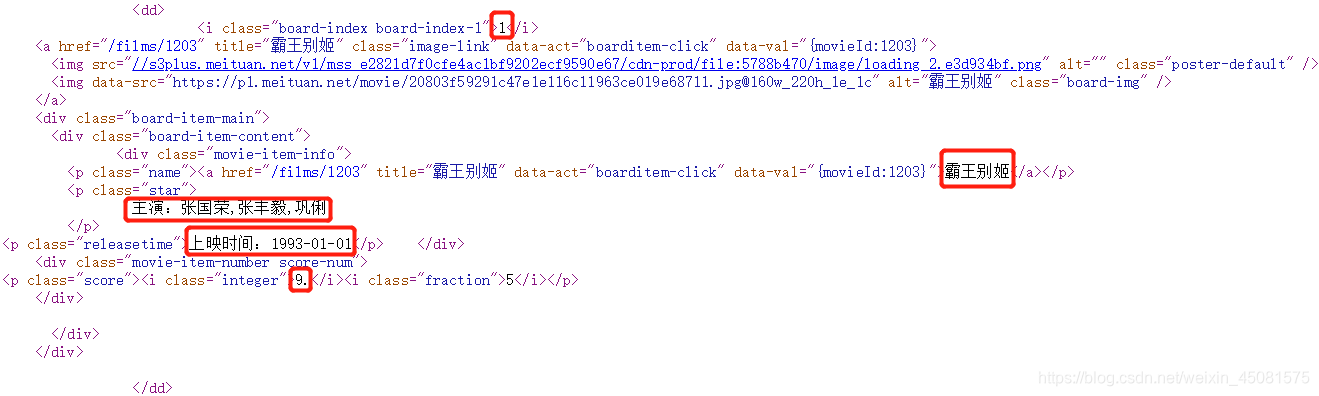
2.完整代码
# 导入模块
import re
import requests
# 请求url,因为一页有10个电影,共10页。这里用一个for函数取10个数字
for i in range(10):
url = 'https://maoyan.com/board/4?offset=%s' % (i*10)
# 网页响应,requests.get表示请求获取网页,text一般用于返回的文本
response = requests.get(url).text
# 解析网页,在请求网页成功后,就需要解析网页了。
# 这里用到了正则表达式,有不清楚的欢迎在下方留言或指正我的错误。
pattern = re.compile(
'<dd>.*?board-index.*?>(\d+)</i>.*?class="name">'
'<a+.*?>(.*?)</a>.*?class="star">(.*?)</p>.*?"releasetime">'
'(.*?)</p>.*?"integer">(.*?)</i>.*?</dd>',re.S)
# 给解析后的网页文本定义一个变量
items = re.findall(pattern, response)
# 遍历items,打印对应的内容,这里定义一个字典,可能会相对美观
for item in items:
d = {"ID": item[0],
"电影": item[1],
"演员": item[2].strip()[3:],
"上映时间": item[3][5:],
"评分:": item[4][0]}
print(d)
上图,爬取猫眼电影top100成功后的图片

3.多线程代码
import re
import csv
import time
import requests
from threading import Thread
class Maoyan_Spider(object):
def __init__(self):
self.headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
}
def get_page(self, url, headers):
response = requests.get(url, headers=self.headers, verify=False)
response.encoding = 'utf-8'
if response.status_code == 200:
return response.text
return None
def parse_page(self, url):
html = self.get_page(url, headers=self.headers)
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, html)
return items
def write_to_file(self, url):
items = self.parse_page(url)
for item in items:
with open('result.csv', 'a+', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['index', item[0],
'image', item[1],
'title', item[2],
'actor', item[3].strip()[3:],
'time', item[4].strip()[5:],
'score', item[5] + item[6]])
def main(self, start, end):
for i in range(start, end):
url = 'http://maoyan.com/board/4?offset=' + str(i * 10)
time.sleep(1)
self.write_to_file(url)
if __name__ == '__main__':
ms = Maoyan_Spider()
t1 = Thread(target=ms.main, args=(0, 5))
t2 = Thread(target=ms.main, args=(5, 10))
t1.start()
t2.start()
好了,本次的分享到这里结束。
有任何疑问欢迎在下方留言哦。
