简介
在大数据领域,用户画像的作用远不止于此。用户的行为数据无法直接用于数据分析和模型训练,我们也无法从用户的行为日志中直接获取有用的信息。而将用户的行为数据标签化以后,我们对用户就有了一个直观的认识。
概述
用户画像的核心工作就是给用户打标签,标签通常是人为规定的高度精炼的特征标识,如年龄、性别、地域、兴趣等。这些标签集合就能抽象出一个用户的信息全貌,每个标签分别描述了该用户的一个维度,各个维度之间相互联系,共同构成对用户的一个整体描述。
1 整理流程
我们对构建用户画像的方法进行总结归纳,发现用户画像的构建一般可以分为目标分析、体系构建、画像建立三步
常用到的技术有: 数据统计,机器学习, 自然语言处理,如下图所示.
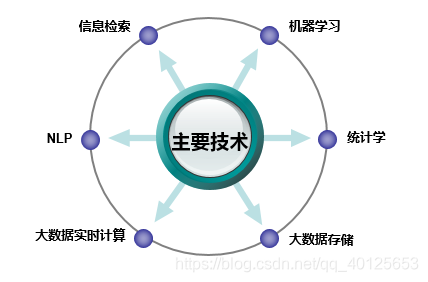
2 标签体系
目前主流的标签体系都是层次化的,首先标签分为几个大类,每个大类下进行逐层细分。在构建标签时,我们只需要构建最下层的标签,就能够映射到上面两级标签。
上层标签都是抽象的标签集合,一般没有实用意义,只有统计意义。例如我们可以统计有人口属性标签的用户比例,但用户有人口属性标签本身对广告投放没有任何意义。
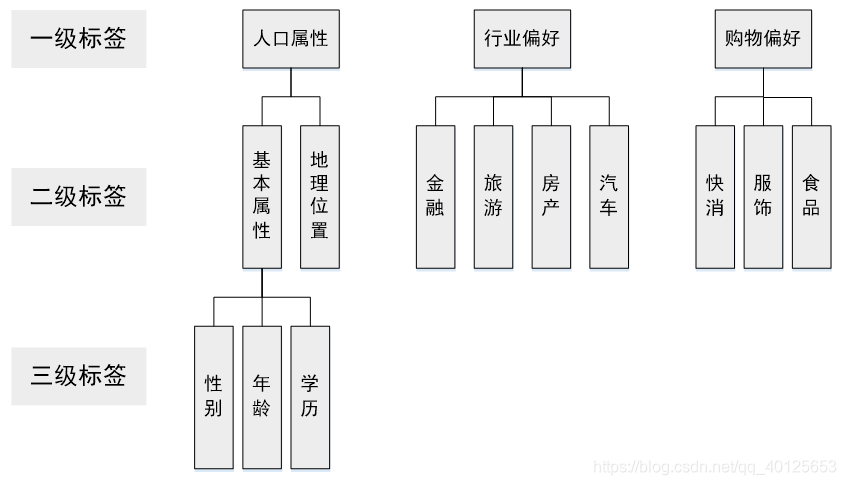
标签的两个基本要求: 一个是每个标签只能表示一种含义,避免标签之间的重复和冲突,便于计算机处理;另一个是标签必须有一定的语义,方便相关人员理解每个标签的含义。
此外,标签的粒度也是需要注意的,标签粒度太粗会没有区分度,粒度过细会导致标签体系太过复杂而不具有通用性。
最后介绍一下各类标签构建的优先级。构建的优先级需要综合考虑业务需求、构建难易程度等,业务需求各有不同,这里介绍的优先级排序方法主要依据构建的难易程度和各类标签的依存关系.

基于原始数据首先构建的是事实标签,事实标签可以从数据库直接获取(如注册信息),或通过简单的统计得到。这类标签构建难度低、实际含义明确,且部分标签可用作后续标签挖掘的基础特征(如产品购买次数可用来作为用户购物偏好的输入特征数据)。
事实标签的构造过程,也是对数据加深理解的过程。对数据进行统计的同时,不仅完成了数据的处理与加工,也对数据的分布有了一定的了解,为高级标签的构造做好了准备。
模型标签是标签体系的核心,也是用户画像工作量最大的部分,大多数用户标签的核心都是模型标签。模型标签的构造大多需要用到机器学习和自然语言处理技术,我们下文中介绍的标签构造方法主要指的是模型标签,具体的构造算法会在本文第03章详细介绍。
最后构造的是高级标签,高级标签是基于事实标签和模型标签进行统计建模得出的,它的构造多与实际的业务指标紧密联系。只有完成基础标签的构建,才能够构造高级标签。构建高级标签使用的模型,可以是简单的数据统计,也可以是复杂的机器学习模型。
3 构建用户画像
把用户画像分为三类, 第一类是: 人口属性, 这一类标签比较稳定,一旦建立很长一段时间基本不用更新,标签体系也比较固定
兴趣属性,这类标签随时间变化很快,标签有很强的时效性,标签体系也不固定
地理属性,这一类标签的时效性跨度很大
人口属性画像,
人口的基本特征,学历,工作,年龄,收入
兴趣画像,
兴趣画像是互联网领域使用最广泛的画像,互联网广告、个性化推荐、精准营销等各个领域最核心的标签都是兴趣标签。兴趣画像主要是从用户海量行为日志中进行核心信息的抽取、标签化和统计,因此在构建用户兴趣画像之前需要先对用户有行为的内容进行内容建模。
内容建模需要注意粒度,过细的粒度会导致标签没有泛化能力和使用价值,过粗的粒度会导致没有区分度。
为了保证兴趣画像既有一定的准确度又有较好的泛化性,我们会构建层次化的兴趣标签体系,使用中同时用几个粒度的标签去匹配,既保证了标签的准确性,又保证了标签的泛化性。下面我们用新闻的用户兴趣画像举例,介绍如何构建层次化的兴趣标签。
- 内容建模
我们希望有一个中间粒度的标签,既有一定的准确度,又有一定的泛化能力。于是我们尝试对关键词进行聚类,把一类关键词当成一个标签,或者把一个分类下的新闻进行拆分,生成像“足球”这种粒度介于关键词和分类之间的主题标签。我们可以使用文本主题聚类完成主题标签的构建。
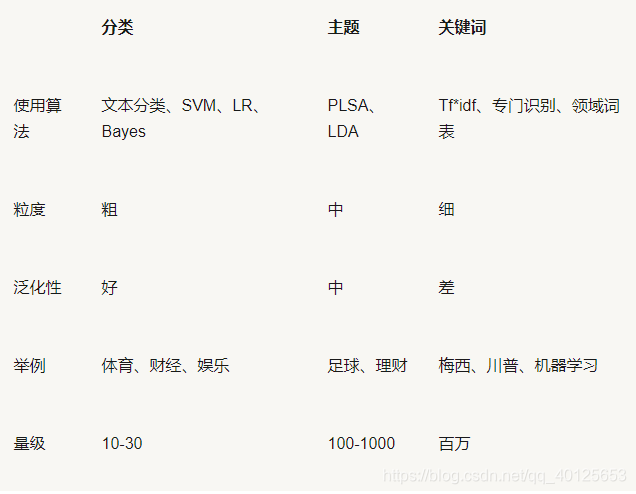
- 兴趣衰减
在完成内容建模以后,我们就可以根据用户点击,计算用户对分类、主题、关键词的兴趣,得到用户兴趣标签的权重。最简单的计数方法是用户点击一篇新闻,就把用户对该篇新闻的所有标签在用户兴趣上加一,用户对每个词的兴趣计算就使用如下的公式:
其中:词在这次浏览的新闻中出现C=1,否则C=0,weight表示词在这篇新闻中的权重。
这样做有两个问题:一个是用户的兴趣累加是线性的,数值会非常大,老的兴趣权重会特别高;另一个是用户的兴趣有很强的时效性,昨天的点击要比一个月之前的点击重要的多,线性叠加无法突出近期兴趣。
为了解决这个问题,需要要对用户兴趣得分进行衰减,我们使用如下的方法对兴趣得分进行次数衰减和时间衰减。
次数衰减的公式如下:
其中,α是衰减因子,每次都对上一次的分数做衰减,最终得分会收敛到一个稳定值 ,α取0.9时,得分会无限接近10。
时间衰减的公式如下:
它表示根据时间对兴趣进行衰减,这样做可以保证时间较早的兴趣会在一段时间以后变的非常弱,同时近期的兴趣会有更大的权重。根据用户兴趣变化的速度、用户活跃度等因素,也可以对兴趣进行周级别、月级别或小时级别的衰减。
地理位置画像
地理位置画像一般分为两部分:一部分是常驻地画像;一部分是GPS画像。两类画像的差别很大,常驻地画像比较容易构造,且标签比较稳定,GPS画像需要实时更新。
常驻地包括国家、省份、城市三级,一般只细化到城市粒度。常驻地的挖掘基于用户的IP地址信息,对用户的IP地址进行解析,对应到相应的城市,对用户IP出现的城市进行统计就可以得到常驻城市标签。
用户的常驻城市标签,不仅可以用来统计各个地域的用户分布,还可以根据用户在各个城市之间的出行轨迹识别出差人群、旅游人群等
4 用户画像评估使用
- 效果评估
准确率, 准确率是用户画像最核心的指标,
覆盖率, 标签的覆盖率指的是被打上标签的用户占全量用户的比例,我们希望标签的覆盖率尽可能的高。但覆盖率和准确率是一对矛盾的指标,需要对二者进行权衡,一般的做法是在准确率符合一定标准的情况下,尽可能的提升覆盖率。
时效性, 有些标签的时效性很强,如兴趣标签、出现轨迹标签等,一周之前的就没有意义了;有些标签基本没有时效性,如性别、年龄等,可以有一年到几年的有效期。对于不同的标签,需要建立合理的更新机制,以保证标签时间上的有效性。 - 画像使用
用户画像在构建和评估之后,就可以在业务中应用,一般需要一个可视化平台,对标签进行查看和检索。画像的可视化一般使用饼图、柱状图等对标签的覆盖人数、覆盖比例等指标做形象的展示,如下图10-12所示是用户画像的一个可视化界面。
此外,对于构建的画像,我们还可以使用不同维度的标签,进行高级的组合分析,产出高质量的分析报告
