前边分析了qemu对内存的建模, 整个过程有三种内存地址 gpa, hva, gva, 在qemu中
如何表现这三种内存呢,
首先qemu把所有的ram片段(由MemoryRegion生成的RamBlock)平坦的铺开,串联起来, 放在
ram_list 链表里面, 用于寻址ram, 这个平坦的ram地址用ram_addr_t表示(这里的ram不光指ram还有rom地址), hva呢用unit8_t类型标示
gpa用hwaddr, 而target_ulong 表示gva
好了下面来看下qemu x86的cpu的mmu实现
864 /* NOTE: this function can trigger an exception */
865 /* NOTE2: the returned address is not exactly the physical address: it
866 * is actually a ram_addr_t (in system mode; the user mode emulation
867 * version of this function returns a guest virtual address).
868 */
869 tb_page_addr_t get_page_addr_code(CPUArchState *env, target_ulong addr)
870 {
871 int mmu_idx, index, pd;
872 void *p;
873 MemoryRegion *mr;
874 CPUState *cpu = ENV_GET_CPU(env);
875 CPUIOTLBEntry *iotlbentry;
876 hwaddr physaddr;
877
878 index = (addr >> TARGET_PAGE_BITS) & (CPU_TLB_SIZE - 1);
879 mmu_idx = cpu_mmu_index(env, true);
880 if (unlikely(env->tlb_table[mmu_idx][index].addr_code !=
881 (addr & (TARGET_PAGE_MASK | TLB_INVALID_MASK)))) {
882 if (!VICTIM_TLB_HIT(addr_read, addr)) {
883 tlb_fill(ENV_GET_CPU(env), addr, 0, MMU_INST_FETCH, mmu_idx, 0);
884 }
885 }
886 iotlbentry = &env->iotlb[mmu_idx][index];
887 pd = iotlbentry->addr & ~TARGET_PAGE_MASK;
888 mr = iotlb_to_region(cpu, pd, iotlbentry->attrs);
889 if (memory_region_is_unassigned(mr)) {
890 qemu_mutex_lock_iothread();
891 if (memory_region_request_mmio_ptr(mr, addr)) {
892 qemu_mutex_unlock_iothread();
893 /* A MemoryRegion is potentially added so re-run the
894 * get_page_addr_code.
895 */
896 return get_page_addr_code(env, addr);
897 }
898 qemu_mutex_unlock_iothread();
899
900 /* Give the new-style cpu_transaction_failed() hook first chance
901 * to handle this.
902 * This is not the ideal place to detect and generate CPU
903 * exceptions for instruction fetch failure (for instance
904 * we don't know the length of the access that the CPU would
905 * use, and it would be better to go ahead and try the access
906 * and use the MemTXResult it produced). However it is the
907 * simplest place we have currently available for the check.
908 */
909 physaddr = (iotlbentry->addr & TARGET_PAGE_MASK) + addr;
910 cpu_transaction_failed(cpu, physaddr, addr, 0, MMU_INST_FETCH, mmu_idx,
911 iotlbentry->attrs, MEMTX_DECODE_ERROR, 0);
912
913 cpu_unassigned_access(cpu, addr, false, true, 0, 4);
914 /* The CPU's unassigned access hook might have longjumped out
915 * with an exception. If it didn't (or there was no hook) then
916 * we can't proceed further.
917 */
918 report_bad_exec(cpu, addr);
919 exit(1);
920 }
921 p = (void *)((uintptr_t)addr + env->tlb_table[mmu_idx][index].addend);
922 return qemu_ram_addr_from_host_nofail(p);
923 }
对于虚拟地址到物理地址的转换, 其实有两种模式, 一种是实地址模式,一种是虚地址模式, 虚地址模式需要进行虚拟地址到物理地址的转换,实地址模式则gpa=gva, 虚地址转换需要使用内存中的页表来辅助转换,为了加快转换过程,使用tlb进行缓存.
对于模拟的x86 cpu对于实地址模式也使用tlb进行地址查询(具体真是的硬件是这样的还是qemu做了简化,这里不去考证).
tlb相关的知识参考https://blog.csdn.net/leishangwen/article/details/27190959 tlb的工作过程, 这里模拟的是直接映射方式时的TLB, 应为这里不需要对操作系统透明,所以我们模拟的cpu只需要实现tlb的硬件接口支持就好了.
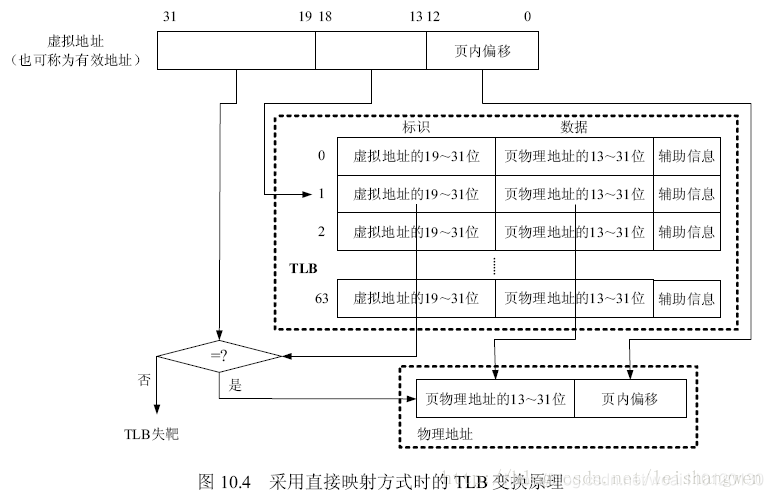
整个寻址过程就是拿虚拟地址的13-18位(6位 64项) 作为索引在tlb表中找到对应的项目. 另外根据19-31位比对地址是否命中, 另外辅助信息中也有一位表示tlb项是否有效,如果无效也未命中,则需要进行转换填充tlb
另外由于内存使用的局部性原理, tlb的大小是有限的,tlb表象可能会被换出去,但是换出去后马上又被访问了,为了解决这种问题,qemu增加了另外一张表叫tlb_v_table, 里面缓存一些被换出去的表象.这个部分不使用虚拟地址进行索引, 通过遍历该表找到地址转换的缓存. v是victim这个单词.
所以tlb的过程只是为了加快地址转换,mmu真正的目的还是要找到gva对应的gpa.
再来说下qemu相关的数据结构
CPUArchState 标示当前cpu的状态信息, 比如寄存器信息,tlb信息等cpu的状态,对于分析mmu比较重要的有如下这些项
/* use a fully associative victim tlb of 8 entries */
#define CPU_VTLB_SIZE 8
#if HOST_LONG_BITS == 32 && TARGET_LONG_BITS == 32
#define CPU_TLB_ENTRY_BITS 4
#else
#define CPU_TLB_ENTRY_BITS 5
#endif
/* TCG_TARGET_TLB_DISPLACEMENT_BITS is used in CPU_TLB_BITS to ensure that
* the TLB is not unnecessarily small, but still small enough for the
* TLB lookup instruction sequence used by the TCG target.
*
* TCG will have to generate an operand as large as the distance between
* env and the tlb_table[NB_MMU_MODES - 1][0].addend. For simplicity,
* the TCG targets just round everything up to the next power of two, and
* count bits. This works because: 1) the size of each TLB is a largish
* power of two, 2) and because the limit of the displacement is really close
* to a power of two, 3) the offset of tlb_table[0][0] inside env is smaller
* than the size of a TLB.
*
* For example, the maximum displacement 0xFFF0 on PPC and MIPS, but TCG
* just says "the displacement is 16 bits". TCG_TARGET_TLB_DISPLACEMENT_BITS
* then ensures that tlb_table at least 0x8000 bytes large ("not unnecessarily
* small": 2^15). The operand then will come up smaller than 0xFFF0 without
* any particular care, because the TLB for a single MMU mode is larger than
* 0x10000-0xFFF0=16 bytes. In the end, the maximum value of the operand
* could be something like 0xC000 (the offset of the last TLB table) plus
* 0x18 (the offset of the addend field in each TLB entry) plus the offset
* of tlb_table inside env (which is non-trivial but not huge).
*/
#define CPU_TLB_BITS \
MIN(8, \
TCG_TARGET_TLB_DISPLACEMENT_BITS - CPU_TLB_ENTRY_BITS - \
(NB_MMU_MODES <= 1 ? 0 : \
NB_MMU_MODES <= 2 ? 1 : \
NB_MMU_MODES <= 4 ? 2 : \
NB_MMU_MODES <= 8 ? 3 : 4))
#define CPU_TLB_SIZE (1 << CPU_TLB_BITS)
typedef struct CPUTLBEntry {
/* bit TARGET_LONG_BITS to TARGET_PAGE_BITS : virtual address
bit TARGET_PAGE_BITS-1..4 : Nonzero for accesses that should not
go directly to ram.
bit 3 : indicates that the entry is invalid
bit 2..0 : zero
*/
union {
struct {
target_ulong addr_read;
target_ulong addr_write;
target_ulong addr_code;
/* Addend to virtual address to get host address. IO accesses
use the corresponding iotlb value. */
uintptr_t addend;
};
/* padding to get a power of two size */
uint8_t dummy[1 << CPU_TLB_ENTRY_BITS];
};
} CPUTLBEntry;
QEMU_BUILD_BUG_ON(sizeof(CPUTLBEntry) != (1 << CPU_TLB_ENTRY_BITS));
/* The IOTLB is not accessed directly inline by generated TCG code,
* so the CPUIOTLBEntry layout is not as critical as that of the
* CPUTLBEntry. (This is also why we don't want to combine the two
* structs into one.)
*/
typedef struct CPUIOTLBEntry {
hwaddr addr;
MemTxAttrs attrs;
} CPUIOTLBEntry;
#define CPU_COMMON_TLB \
/* The meaning of the MMU modes is defined in the target code. */ \
CPUTLBEntry tlb_table[NB_MMU_MODES][CPU_TLB_SIZE]; \
CPUTLBEntry tlb_v_table[NB_MMU_MODES][CPU_VTLB_SIZE]; \
CPUIOTLBEntry iotlb[NB_MMU_MODES][CPU_TLB_SIZE]; \
CPUIOTLBEntry iotlb_v[NB_MMU_MODES][CPU_VTLB_SIZE]; \
size_t tlb_flush_count; \
target_ulong tlb_flush_addr; \
target_ulong tlb_flush_mask; \
target_ulong vtlb_index;
tlb_table 标示tlb表
tlb_v_table 就是tlb_table的victim表
iotlb 这个其实是和tlb_table一起使用的
iotlb_v 同理是iotlb的victim表
tlb_table的主要作用的进行地址翻译, iotlb的主要作用是帮转qemu进行gpa→hva的转换 (这里的hva不光包括ram模拟还包括rom和mmio)
另外tlb_table和 io_tlb 都是二唯数组, 第一个唯独取决于cpu的工作模式,我们不去分析不同模式,这分析标准模式
有了上面的背景知识再来分析mmu其实是比较简单的.
880行从tlb_table里面查虚拟地址, 去过没有 则882行从tlb_v_table 表里面查询, 最终如果没有命中, 怎么办呢, 883行调用
tlb_fill填充tlb
886-896行处理需要mmio的情况
900-919行为异常情况, 不去分析
最后922 行使用qemu_ram_addr_from_host_nofail 来获取对应的ram_addr_t .
mmu的具体地址转换过程其实是在tlb_fill函数中实现,我们今天只分析实模式。
void tlb_fill(CPUState *cs, target_ulong addr, int size,
MMUAccessType access_type, int mmu_idx, uintptr_t retaddr)
{
int ret;
ret = x86_cpu_handle_mmu_fault(cs, addr, size, access_type, mmu_idx);
if (ret) {
X86CPU *cpu = X86_CPU(cs);
CPUX86State *env = &cpu->env;
raise_exception_err_ra(env, cs->exception_index, env->error_code, retaddr);
}
}
这里是通过x86_cpu_handle_mmu_fault函数进行的地址转换,如果转换失败则发生异常, 这里转换完成之后会直接填充tlb,后面再从tlb中查询,所以tlb_fill函数并无返回值。
这里x86_cpu_handle_mmu_fault的参数cs为cpu状态,addr为要转换的虚拟地址, size为要翻译的地址大小(可能是多个页面), access_type为触发mm的操作类型,mmu_idx用于索引当前mmu的模式。
60 /* return value:
161 * -1 = cannot handle fault
162 * 0 = nothing more to do
163 * 1 = generate PF fault
164 */
165 int x86_cpu_handle_mmu_fault(CPUState *cs, vaddr addr, int size,
166 int is_write1, int mmu_idx)
167 {
168 X86CPU *cpu = X86_CPU(cs);
169 CPUX86State *env = &cpu->env;
170 uint64_t ptep, pte;
171 int32_t a20_mask;
172 target_ulong pde_addr, pte_addr;
173 int error_code = 0;
174 int is_dirty, prot, page_size, is_write, is_user;
175 hwaddr paddr;
176 uint64_t rsvd_mask = PG_HI_RSVD_MASK;
177 uint32_t page_offset;
178 target_ulong vaddr;
179
180 is_user = mmu_idx == MMU_USER_IDX;
......
185 is_write = is_write1 & 1;
186
187 a20_mask = x86_get_a20_mask(env);
188 if (!(env->cr[0] & CR0_PG_MASK)) {
189 pte = addr;
190 #ifdef TARGET_X86_64
191 if (!(env->hflags & HF_LMA_MASK)) {
192 /* Without long mode we can only address 32bits in real mode */
193 pte = (uint32_t)pte;
194 }
195 #endif
196 prot = PAGE_READ | PAGE_WRITE | PAGE_EXEC;
197 page_size = 4096;
198 goto do_mapping;
199 }
200
......
440 do_mapping:
441 pte = pte & a20_mask;
442
443 /* align to page_size */
444 pte &= PG_ADDRESS_MASK & ~(page_size - 1);
445
446 /* Even if 4MB pages, we map only one 4KB page in the cache to
447 avoid filling it too fast */
448 vaddr = addr & TARGET_PAGE_MASK;
449 page_offset = vaddr & (page_size - 1);
450 paddr = pte + page_offset;
451
452 assert(prot & (1 << is_write1));
453 tlb_set_page_with_attrs(cs, vaddr, paddr, cpu_get_mem_attrs(env),
454 prot, mmu_idx, page_size);
455 return 0;
456 do_fault_rsvd:
457 error_code |= PG_ERROR_RSVD_MASK;
458 do_fault_protect:
459 error_code |= PG_ERROR_P_MASK;
460 do_fault:
461 error_code |= (is_write << PG_ERROR_W_BIT);
462 if (is_user)
463 error_code |= PG_ERROR_U_MASK;
464 if (is_write1 == 2 &&
465 (((env->efer & MSR_EFER_NXE) &&
466 (env->cr[4] & CR4_PAE_MASK)) ||
467 (env->cr[4] & CR4_SMEP_MASK)))
468 error_code |= PG_ERROR_I_D_MASK;
469 if (env->intercept_exceptions & (1 << EXCP0E_PAGE)) {
470 /* cr2 is not modified in case of exceptions */
471 x86_stq_phys(cs,
472 env->vm_vmcb + offsetof(struct vmcb, control.exit_info_2),
473 addr);
474 } else {
475 env->cr[2] = addr;
476 }
477 env->error_code = error_code;
478 cs->exception_index = EXCP0E_PAGE;
479 return 1;
480 }
187-198行获取地址的总线的宽度,一般在i386cpu上,a20地址先开了之后处于保护模式,地址宽度为32位, 否则为20位,如果没有开cr0的CR0_PG_MASK位则是实模式, 直接进行映射,也就是do_mapping后的操作。
调用tlb_set_page_with_attrs 填充tlb。
606 /* Add a new TLB entry. At most one entry for a given virtual address
607 * is permitted. Only a single TARGET_PAGE_SIZE region is mapped, the
608 * supplied size is only used by tlb_flush_page.
609 *
610 * Called from TCG-generated code, which is under an RCU read-side
611 * critical section.
612 */
613 void tlb_set_page_with_attrs(CPUState *cpu, target_ulong vaddr,
614 hwaddr paddr, MemTxAttrs attrs, int prot,
615 int mmu_idx, target_ulong size)
616 {
617 CPUArchState *env = cpu->env_ptr;
618 MemoryRegionSection *section;
619 unsigned int index;
620 target_ulong address;
621 target_ulong code_address;
622 uintptr_t addend;
623 CPUTLBEntry *te, *tv, tn;
624 hwaddr iotlb, xlat, sz;
625 unsigned vidx = env->vtlb_index++ % CPU_VTLB_SIZE;
626 int asidx = cpu_asidx_from_attrs(cpu, attrs);
627
628 assert_cpu_is_self(cpu);
629 assert(size >= TARGET_PAGE_SIZE);
630 if (size != TARGET_PAGE_SIZE) {
631 tlb_add_large_page(env, vaddr, size);
632 }
633
634 sz = size;
635 section = address_space_translate_for_iotlb(cpu, asidx, paddr, &xlat, &sz);
636 assert(sz >= TARGET_PAGE_SIZE);
637
638 tlb_debug("vaddr=" TARGET_FMT_lx " paddr=0x" TARGET_FMT_plx
639 " prot=%x idx=%d\n",
640 vaddr, paddr, prot, mmu_idx);
641
642 address = vaddr;
643 if (!memory_region_is_ram(section->mr) && !memory_region_is_romd(section->mr)) {
644 /* IO memory case */
645 address |= TLB_MMIO;
646 addend = 0;
647 } else {
648 /* TLB_MMIO for rom/romd handled below */
649 addend = (uintptr_t)memory_region_get_ram_ptr(section->mr) + xlat;
650 }
651
652 code_address = address;
653 iotlb = memory_region_section_get_iotlb(cpu, section, vaddr, paddr, xlat,
654 prot, &address);
655
656 index = (vaddr >> TARGET_PAGE_BITS) & (CPU_TLB_SIZE - 1);
657 te = &env->tlb_table[mmu_idx][index];
658 /* do not discard the translation in te, evict it into a victim tlb */
659 tv = &env->tlb_v_table[mmu_idx][vidx];
660
661 /* addr_write can race with tlb_reset_dirty_range */
662 copy_tlb_helper(tv, te, true);
663
664 env->iotlb_v[mmu_idx][vidx] = env->iotlb[mmu_idx][index];
665
666 /* refill the tlb */
667 env->iotlb[mmu_idx][index].addr = iotlb - vaddr;
668 env->iotlb[mmu_idx][index].attrs = attrs;
669
670 /* Now calculate the new entry */
671 tn.addend = addend - vaddr;
672 if (prot & PAGE_READ) {
673 tn.addr_read = address;
674 } else {
675 tn.addr_read = -1;
676 }
677
678 if (prot & PAGE_EXEC) {
679 tn.addr_code = code_address;
680 } else {
681 tn.addr_code = -1;
682 }
683
684 tn.addr_write = -1;
685 if (prot & PAGE_WRITE) {
686 if ((memory_region_is_ram(section->mr) && section->readonly)
687 || memory_region_is_romd(section->mr)) {
688 /* Write access calls the I/O callback. */
689 tn.addr_write = address | TLB_MMIO;
690 } else if (memory_region_is_ram(section->mr)
691 && cpu_physical_memory_is_clean(
692 memory_region_get_ram_addr(section->mr) + xlat)) {
693 tn.addr_write = address | TLB_NOTDIRTY;
694 } else {
695 tn.addr_write = address;
696 }
697 if (prot & PAGE_WRITE_INV) {
698 tn.addr_write |= TLB_INVALID_MASK;
699 }
700 }
701
702 /* Pairs with flag setting in tlb_reset_dirty_range */
703 copy_tlb_helper(te, &tn, true);
704 /* atomic_mb_set(&te->addr_write, write_address); */
705 }
要弄懂这个函数必须要说下tlb_table 和io_tlb, 从名字也可以看出来tlb_table用于tlb转换和ram类型的内存读写(直接访问hva),mmio类型的读访问,所以CPUTLBEntry里面包含addr_read, addr_write和addr_code,分别验证读写执行是否可以直接访问hva。 io_tlb则不负责rom,mmio类型内存的读写访存。
CPUTLBEntry中的addend用于计算hva, (CPUTLBEntry->addend&PAGE_MASK) + gva = hva
CPUIOTLBEntry的addr用于addr有两部分 , ( CPUIOTLBEntry->addr & (PAGE_MASK)) 用于指向MemoryRegionSection。
当内存地址为为定义的ram或者rom的时候, (CPUIOTLBEntry->addr & PAGE_MASK) + gva = ram_addr_t
当CPUIOTLBEntry为mmio的时候CPUIOTLBEntry->addr其实没有什么用, 只需要找到MemoryRegionSection即可完成访存操作
另外说下CPUTLBEntry->addr_read 当读内存的时候会比对tlb_table该属性,如果不可读该值为-1, 如果TLB_MMIO被设置则使用io_tlb进行访存
如果不是MMIO地址,如果可读则该值可以用于定位hva。
CPUTLBEntry->addr_code 用于tlb缓存对比,和定位hva
CPUTLBEntry->addr_write 当写内存的时候会比对tlb_table该属性,如果不可写该值为-1, 如果TLB_MMIO被设置则使用io_tlb进行访存
如果不是MMIO地址,如果可写则该值可以用于定位hva。
知道这些之后上面的代码就一目了然了
