信息是有单位的?
信息到底是如何计算的?信息为什么还会有单位?
如果你对这些已经了如指掌,那么这篇文章就不是为你准备的。如果你还不清楚,那就希望你可以慢慢看完这篇文章。
1.单位
回想一下,什么东西有单位?质量,温度,长度等物理量。
没错,信息也是一个物理量。 要测量这个物理量,不妨回想一下我们是怎么测量质量的,“千克”最初又是怎么被定义出来的?
其实最初我们并不知道千克的质量,而是选择了一个参照物,把这个物体的质量就称为千克。当想要测量其他物体的质量时,就看这个物体的质量相当于多少个参照物体的质量。这里的”多少个“便是千克。如果换另一个参照物体,那么单位就会变化,比如斤。
例如:
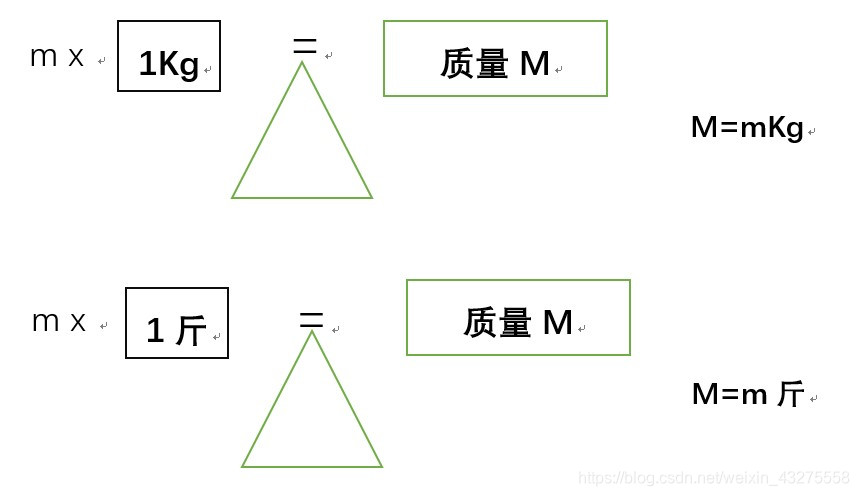
仔细看看上面这幅图,理解了没有?类似的,m(米)、℃也是这么定义来的。虽然每天都在接触单位这玩意,现在终于知道是怎么来的了。如果你有了好奇心,那就接着往下看~~
2.信息是如何测量的
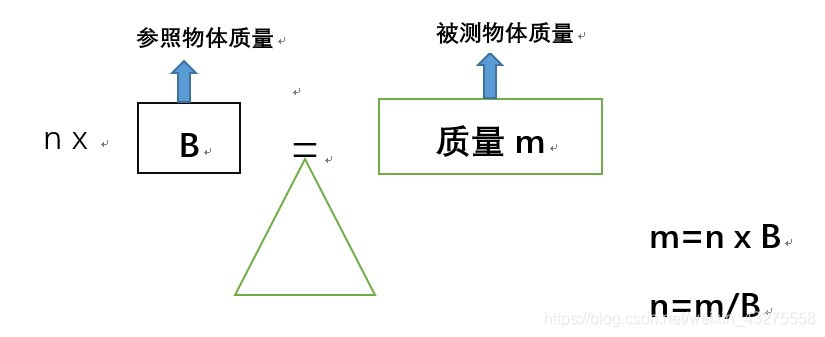
测量信息时也是一样,既然信息消除的是不确定性,那么就选择另一个事件的不确定性作为参照事件。 当想要测量其他事件的信息时,就看看待测事件的不确定性相当于多少个参照事件的不确定性。这里的多少个便是信息量。
规定(敲黑板,敲黑板!):当选择的参照事物是像抛硬币这样,只有 2 种等概率情况的事件时,测得的信息量的单位就被称为比特(bit)。
PS:什么?没听懂?那我给你翻译翻译:抛掷一个硬币产生的信息=1bit,至于为什么是抛掷硬币,这个就是规定,没为什么 ~~~ >ω<
其实到这里,好多人已经明白了吧?测量一件事情的信息量,就看他的不确定性=抛掷几枚硬币 不就行了?如果还不明白,再往下看
回想一下,我们测量质量时,我们是用 待测物体的质量除以参照物体的质量。 因为待测物体的质量 m 等于 参照物体的质量 B 和 乘以 参照物体个数 n ,所以当知道 m 要求 n 时,我们用乘法的反函数,即除法来计算。
可是测量信息量时,却不能用除法。为什么呢?因为 抛掷 3 个硬币能够产生的等可能结果并非 3*2=6,而是 2^3=8 种(如果这点不明白,你可以往下看)。也就是说 待测物体不确定情况的个数 m 是由 参照物个数 n(硬币个数) 的指数关系进行累积的。 即 m
n
2 , m=2n ,即 n=
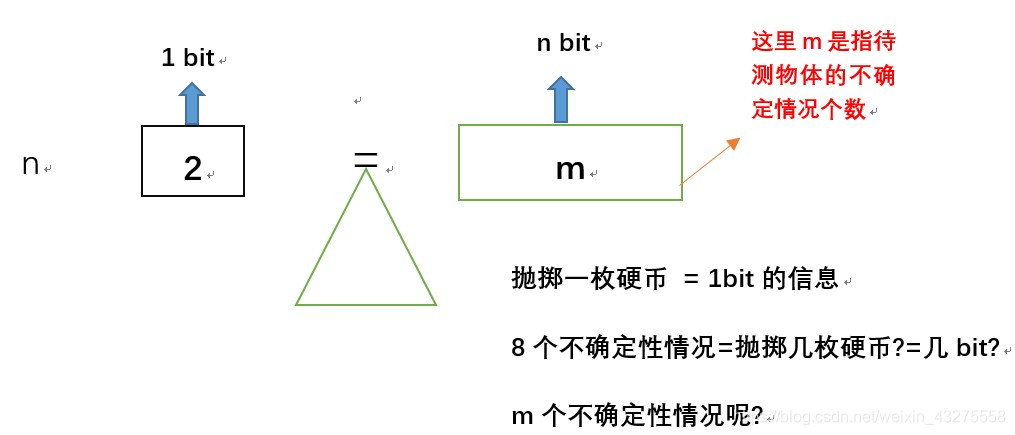
究其根源,我们实际上就想求n的值,如果一个事件有m个不确定性情况,那么这个事件就有n bit的信息。而 n=
。
PS:其实说白了,只要你给我一件事情的不确定情况个数m,我就可以算出这件事所包含信息量n是多少。
那么,比如说,当小明面对一个选择题时,他不知道ABCD那个选项是对的,这个事件的信息量是多少呢?如果你直接告诉我,是
= 2 bits,是2bit的信息。嗯~~恭喜你,答对了,说明上边的东西你理解了。你可以接着往下看了。
记住,一定要把上边的逻辑理清了,再往下看
3.更普遍性
上边求信息量,有个前提,那就是被测事件的所有可能情况都必须是等概率才行,因为参照事件本身的两种情况就是等概率。
例如:ABCD四个选项:
| A | 1/4 |
|---|---|
| B | 1/4 |
| C | 1/4 |
| D | 1/4 |
想象这样一个问题:
当小明不知道选择题是 ABCD 哪个选项时:突然有人告诉小明 “有一半可能性是 C 选项” 时,那么ABCD各个情况的概率就不一样了,这时该如何计算信息量呢?
| 选项 | 概率 |
|---|---|
| A | 1/6 |
| B | 1/6 |
| C | 1/2 |
| D | 1/6 |
答案是分别测量待测事件每种可能情况的信息量后,乘以它们各自的发生概率再相加即可。
不过,怎么测量每种情况的信息量呢? 怎么知道概率为 1/6 的情况的不确定性相当于抛掷多少次硬币所产生的不确定性呢? m到底是多少呢?
我们知道概率 p=1/100会发生的情况,相当于从100个等概率情况中确定1个情况, 即不确定性情况有100种,概率的倒数等于等概率情况的个数,m = 1/p。 所以,可以用1/p来代替m。
PS:这个地方也很迷~~大家可以再仔细想想对不对。比如说,概率为3/10。那么等概率情况的个数就是10/3,又因为每个情况的概率又是3/10,10/3*3/10=1,是不是这么个道理?
所以信息量H(x)就可以这么计算:H(X) =
p(x)
4.香农定理
敲黑板,敲黑板!!香农来了,香农来了!
下面的公式就是著名的香农定理,有没有感觉他很熟悉? H(X)就是信息量,P(X)就是概率。为什么多了一个负号呢?你把负号拿掉,式子就变成H(X) =
p(x)
。这不就是就是我们上面说的信息量的公式么?
对,就是如此,著名的香农定理,也不过如此。
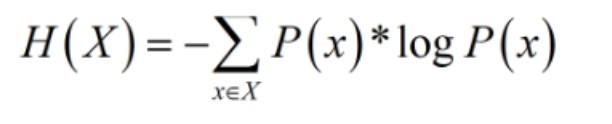
回到例子中,
小明做一个选择题,他不知道ABCD哪个选项是对的(此时是等概率),所以答案的不确定性(信息量)是
=2bit。当小红告诉小明 C 有 50%概率是正确答案时,各个选项概率是:
| 选项 | 概率 |
|---|---|
| A | 1/6 |
| B | 1/6 |
| C | 1/2 |
| D | 1/6 |
信息量就可以这么求:1/6 ⅹ
+1/6ⅹ
+ 1/2ⅹ
+ 1/6ⅹ
= 1.79 bits
2-1.79=0.21 bits, 当小红告诉小明C 有一半概率是对的,所提供的信息就是0.21bits
文章的最后,再来看看一个很简单的题目:加深你对信息量的理解
当小明不知道选择题是 ABCD 哪个选项时:(这时信息量时是 =2 bits)
- 小红告小明 “D 选项是错的”,提供了 0.415 bits 的信息
H(x)=1/3 +1/3 +1/3 =1.585 bits
2-1.585=0.415 bit - 再告诉小明 “A选项是错的”,提供了 0.585 bits 的信息
H(x)=1/2 +1/2 = 1 bit
1.585-1=0.585 bit - 再告诉小明 “B选项是错的”,提供了 1 bit 的信息
H(x)=1 =0 bit
1-0=1 bit
5.总结:
香农信息论,简单的叙述就是,事件发生的可能性用来描述不确定性,信息通过不确定性的测量来定义。事情的不确定性越大,包含的信息就越多。其实文章中所提到的信息量就是信息熵。因为熵这个概念需要单独一篇文章来解释,所以这里就没替换。
后面我会再讲讲关于信息熵、条件熵、以及联合熵的概念,包括机器学习里面最常用的交叉熵损失函数,以及MDL准则(原理也是熵)。千万不要觉得熵是学信息论的人学的,如果一个学计算的人不知道熵,不知道会不会被嘲笑~~
参考资料:可以关注微信公众号:超智能体,他里面有很多有意思的东西,每个视频也就几分钟,但是真的很有意思!非常推荐大家可以去看看!本文章就是根据里面的视频所写~
文章如有不当之处,请多多指教! 评论区见 ~ ∩ω∩
