文章目录
paddle使用笔记
对paddleseg的使用做一些记录,github地址 https://github.com/PaddlePaddle/PaddleSeg/
本文主要按照github上的说明文档操作,如有疑问还需参考源文档。
本文介绍windows系统下的安装配置训练。建议使用aistudio进行训练。
AIStudio链接
1 安装
1.1 cuda和cudnn安装
cuda安装可从官网下载 https://developer.nvidia.com/cuda-downloads。使用RTX2060显卡,cuda9不兼容这个显卡,选择cuda10版本的。
安装完cuda在默认目录 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0
下载cudnn,同样可从官网下载 https://developer.nvidia.com/cudnn
需要注册账号才能下载。
下载完成后解压,将各级目录下的文件复制或剪切到cuda相应的目录下。
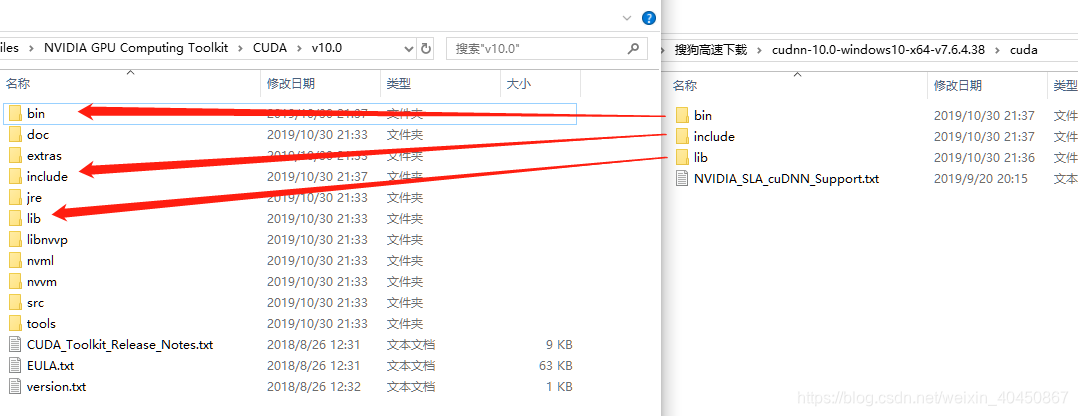
安装完成后,系统环境变量会有两个变量CUDA_PATH,CUDA_PATH_V_10指向了cuda的安装路径。
打开命令行,输入nvcc -V验证cuda是否安装成功。
> nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2018 NVIDIA Corporation
Built on Sat_Aug_25_21:08:04_Central_Daylight_Time_2018
Cuda compilation tools, release 10.0, V10.0.130
1.2 paddlepaddle安装
可通过pip或conda等多种方式安装,这里通过pip安装。可在https://pypi.org/查找相关的版本安装,选择1.5.2版本
安装命令为
pip install paddlepaddle-gpu==1.5.2.post107
安装完成后验证,进入python终端,输入
import paddle.fluid
paddle.fluid.install_check.run_check()
结果显示
Running Verify Fluid Program ...
W1031 20:03:27.734861 20372 device_context.cc:259] Please NOTE: device: 0, CUDA Capability: 75, Driver API Version: 10.0, Runtime API Version: 10.0
W1031 20:03:27.908926 20372 device_context.cc:267] device: 0, cuDNN Version: 7.6.
Your Paddle Fluid works well on SINGLE GPU or CPU.
I1031 20:03:28.048846 20372 parallel_executor.cc:334] The number of CUDAPlace, which is used in ParallelExecutor, is 1. And the Program will be copied 1 copies
I1031 20:03:28.058840 20372 build_strategy.cc:340] SeqOnlyAllReduceOps:0, num_trainers:1
Your Paddle Fluid works well on MUTIPLE GPU or CPU.
Your Paddle Fluid is installed successfully! Let's start deep Learning with Paddle Fluid now
1.3 paddleseg安装
直接从github下载到本地解压即可
https://codeload.github.com/PaddlePaddle/PaddleSeg/zip/release/v0.1.0
这里放到D盘根目录下,解压后的目录为D:\PaddleSeg
其次安装相关的依赖,在系统命令行下,Win+R,输入powershell
cd D:\PaddleSeg
pip install -r requirements.txt --ignore-installed
2 训练评估和可视化
2.1 训练
参考官方文档
直接操作
打开powershell,下载预训练模型
cd D:\PaddleSeg
python pretrained_model/download_model.py unet_bn_coco
python dataset/download_pet.py
由于我们设置的训练EPOCH数量为100,保存间隔为10,因此一共会产生10个定期保存的模型,加上最终保存的final模型,一共有11个模型。
官方文档说export CUDA_VISIBLE_DEVICES=0,但是Windows下没有找到export这个命令,直接在计算机属性,高级系统设置中,修改环境变量即可,新建一个环境变量CUDA_VISIBLE_DEVICES的值为0。
运行下面的命令进行训练。运行之前请先移步下面的黄色背景的字。
如果出现某些显存的问题可以尝试修改BATCH_SIZE的大小。
python pdseg/train.py --use_gpu --do_eval --use_tb --tb_log_dir train_log --cfg configs/unet_pet.yaml BATCH_SIZE 2 TRAIN.PRETRAINED_MODEL_DIR pretrained_model/unet_bn_coco SOLVER.LR 5e-5
如果还有显存不够的提示,可以运行下面的命令,换个网络,不过收敛速度没有上面的快,效果也不佳。下面的命令对显存要求比较低,但是效果也差。
python pdseg/train.py --use_gpu --do_eval --use_tb --tb_log_dir train_log --cfg configs/deeplabv3p_mobilenet-1-0_pet.yaml BATCH_SIZE 2 TRAIN.PRETRAINED_MODEL_DIR pretrained_model/unet_bn_coco SOLVER.LR 5e-5
当epoch=10的时候,会保存检查点,出现了错误:

其原因是对路径 './saved_model/unet_pet/10'进行split的时候使用的os.path.sep,没有将10分开,根据提示,修改一下\padseg\vis.py中的第229行,将os.path.sep替换为 ‘/’.修改完成后即可正常训练。
#第229行
epoch = int(ckpt_dir.split(os.path.sep)[-1])
#改为
epoch = int(ckpt_dir.split('/')[-1])
开始训练
经过五十分钟的训练,完成训练。
2.2 训练过程的可视化
另外开启一个powershell
127.0.0.1为本地ip地址,12345为没有正在使用的端口后,可视化界面将会使用这个端口。
一定要先进入paddleseg的目录,否则会提示找不到相关的数据。
cd D:\PaddleSeg
tensorboard --logdir train_log --host 127.0.0.1 --port 12345
结果显示TensorBoard 1.15.0a20190818 at http://127.0.0.1:12345/ (Press CTRL+C to quit)
在浏览器中打开结果中的链接。
训练了几步的结果:
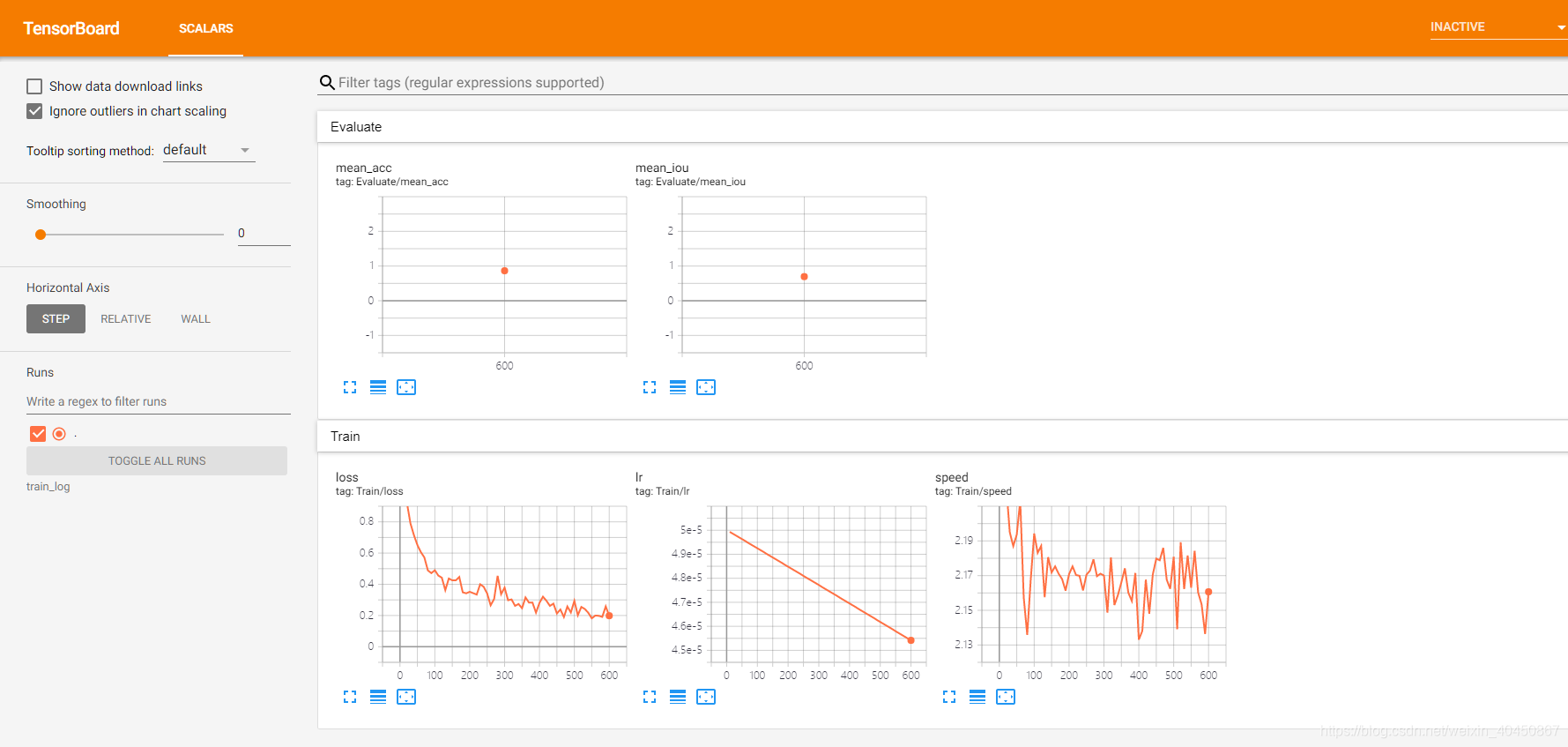
训练完成后的结果:
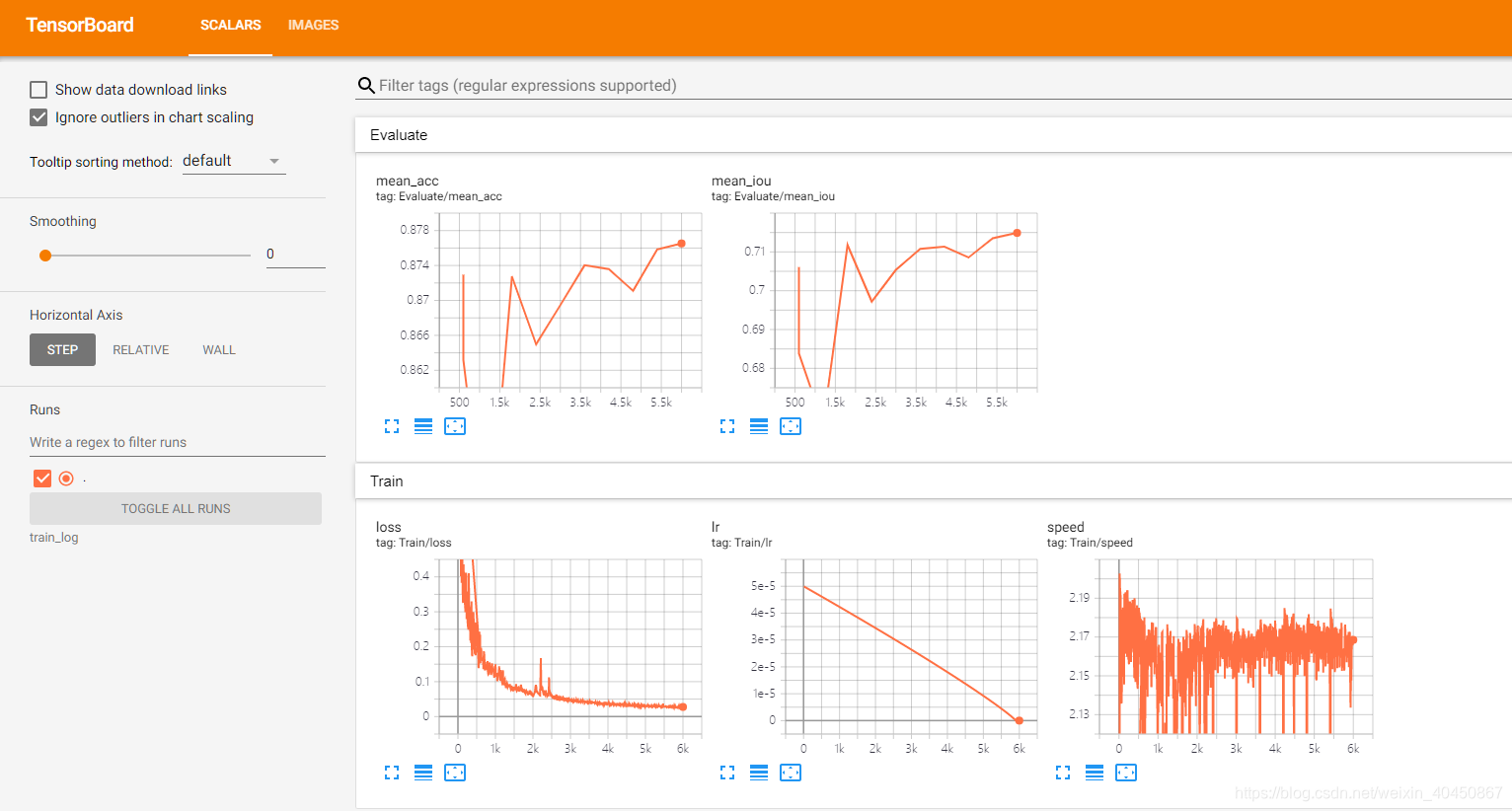
2.3 模型评估
训练完成后,我们可以通过eval.py来评估模型效果。由于我们设置的训练EPOCH数量为100,保存间隔为10,因此一共会产生10个定期保存的模型,加上最终保存的final模型,一共有11个模型。我们选择最后保存的模型进行效果的评估:
cd D:\PaddleSeg
python pdseg/eval.py --use_gpu --cfg configs/unet_pet.yaml TEST.TEST_MODEL saved_model/unet_pet/final
结果为
#Device count: 1
W1031 22:11:20.293750 7824 device_context.cc:259] Please NOTE: device: 0, CUDA Capability: 75, Driver API Version: 10.0, Runtime API Version: 10.0
W1031 22:11:20.303740 7824 device_context.cc:267] device: 0, cuDNN Version: 7.6.
load test model: saved_model/unet_pet/final
[EVAL]step=1 loss=0.75190 acc=0.8295 IoU=0.6546 step/sec=0.51 | ETA 00:00:19
[EVAL]step=2 loss=0.78430 acc=0.8324 IoU=0.6443 step/sec=2.93 | ETA 00:00:03
[EVAL]step=3 loss=0.50994 acc=0.8519 IoU=0.6730 step/sec=2.92 | ETA 00:00:02
[EVAL]step=4 loss=0.27157 acc=0.8727 IoU=0.6969 step/sec=2.85 | ETA 00:00:02
[EVAL]step=5 loss=0.40953 acc=0.8790 IoU=0.7041 step/sec=3.03 | ETA 00:00:01
[EVAL]step=6 loss=0.76555 acc=0.8724 IoU=0.6986 step/sec=2.91 | ETA 00:00:01
[EVAL]step=7 loss=0.76442 acc=0.8702 IoU=0.6987 step/sec=2.95 | ETA 00:00:01
[EVAL]step=8 loss=0.38000 acc=0.8760 IoU=0.7118 step/sec=3.00 | ETA 00:00:01
[EVAL]step=9 loss=0.26133 acc=0.8822 IoU=0.7231 step/sec=2.85 | ETA 00:00:00
[EVAL]step=10 loss=0.98898 acc=0.8765 IoU=0.7149 step/sec=3.00 | ETA 00:00:00
[EVAL]#image=40 acc=0.8765 IoU=0.7149
[EVAL]Category IoU: [0.7754 0.8608 0.5085]
[EVAL]Category Acc: [0.8662 0.9249 0.6896]
[EVAL]Kappa:0.7854
2.4模型可视化
通过vis.py来评估模型效果,我们选择最后保存的模型进行效果的评估:
python pdseg/vis.py --use_gpu --cfg configs/unet_pet.yaml TEST.TEST_MODEL saved_model/unet_pet/final
执行上述脚本后,会在主目录下产生一个visual/visual_results文件夹,里面存放着测试集图片的预测结果,我们选择其中几张图片进行查看,可以看到,在测试集中的图片上的预测效果:
NOTE
可视化的图片会默认保存在visual/visual_results目录下,可以通过–vis_dir来指定输出目录
训练过程中会使用DATASET.VIS_FILE_LIST中的图片进行可视化显示,而vis.py则会使用DATASET.TEST_FILE_LIST
将测试的数据复制到一个文件夹中
import os
import shutil
images=[i.replace(".png",".jpg") for i in os.listdir(r"D:\PaddleSeg\visual\visual_results")]
if not os.path.exists(r"D:\PaddleSeg\visual\raw"):os.makedirs(r"D:\PaddleSeg\visual\raw")
for i in images: shutil.copyfile(r"D:\PaddleSeg\dataset\mini_pet\images"+"\\"+i,r"D:\PaddleSeg\visual\raw"+"\\"+i)
结果对比


3 使用自定义的数据集
包括修改配置文件,运行,运行时也可以指定各种参数,优先于yaml的参数。
配置文件为yaml格式的文件。
一个示例如下
TRAIN_CROP_SIZE: (500, 500) # (width, height), for unpadding rangescaling and stepscaling
EVAL_CROP_SIZE: (500, 500) # (width, height), for unpadding rangescaling and stepscaling
MEAN: [0.5,0.5,0.5]
STD: [0.5,0.5,0.5] #预处理用到的三个数,如果是rgba模式,则MEAN和STD需要改成4个元素
AUG:
AUG_METHOD: "unpadding" # choice unpadding rangescaling and stepscaling
FIX_RESIZE_SIZE: (500, 500) # (width, height), for unpadding
INF_RESIZE_VALUE: 500 # for rangescaling
MAX_RESIZE_VALUE: 600 # for rangescaling
MIN_RESIZE_VALUE: 400 # for rangescaling
MAX_SCALE_FACTOR: 1.25 # for stepscaling
MIN_SCALE_FACTOR: 0.75 # for stepscaling
SCALE_STEP_SIZE: 0.25 # for stepscaling
MIRROR: True
BATCH_SIZE: 4
DATASET:
DATA_DIR: "../cropdataset/" #数据集的文件夹
IMAGE_TYPE: "rgb" # choice rgb or rgba,三个波段或者四个波段
NUM_CLASSES: 2 #类别的数量
TEST_FILE_LIST: "../cropdataset/file_listRGB/test_list.txt" #测试集的txt记录,每一行空格分隔,第一个元素是原始图片路径,第二个元素为标注图片路径
TRAIN_FILE_LIST: "../cropdataset/file_listRGB/train_list.txt" #训练集的txt
VAL_FILE_LIST: "../cropdataset/file_listRGB/val_list.txt" #验证集的txt
VIS_FILE_LIST: "../cropdataset/file_listRGB/test_list.txt" #可视化的txt,一般用测试集可视化
IGNORE_INDEX: 255
SEPARATOR: " " #上述txt每一行的分隔符
FREEZE:
MODEL_FILENAME: "__model__"
PARAMS_FILENAME: "__params__"
MODEL:
MODEL_NAME: "unet" #模型信息,如果更换模型,则这个MODEL下的条目都要修改
DEFAULT_NORM_TYPE: "bn"
TEST:
TEST_MODEL: "./saved_model/RGB_unet/final/" #测试用的模型,使用final最终保存的模型
TRAIN:
MODEL_SAVE_DIR: "./saved_model/RGB_unet/" #模型的保存路径
PRETRAINED_MODEL_DIR: "../PaddleSeg/pretrained_model/unet_bn_coco/" #预训练模型的路径,一般先使用预训练模型的参数,再训练,可以大大缩短训练时间
SNAPSHOT_EPOCH: 10 #多少轮进行模型备份,下次终端的时候可以使用已经保存的模型的基础上继续训练
SOLVER:
NUM_EPOCHS: 100 #总共训练的轮数,遍历数据集的次数
LR: 0.005 #学习率
LR_POLICY: "poly" #衰减方式
OPTIMIZER: "adam" #正则化
运行;
开训时需要修改配置文件的路径yaml,学习率5e-5
python ../PaddleSeg/pdseg/train.py --use_gpu \
--do_eval \
--use_tb \
--tb_log_dir train_log \
--cfg ./RGB_unet.yaml \
BATCH_SIZE 4 \
SOLVER.LR 5e-5
