0.概述
低功耗智能语音信号处理业务开发流程首先通过在学术领域中的理论算法结合具体场景选取适当的方法,通过matlab/python先实现算法对音频进行处理,如果结果达到理想效果,再编写C语言工程。编写C工程的过程需要先实现浮点工程,然后可以通过matlab或者Python去改变相关变量的浮点精度去验证变量定标的误差和精度是否在可接受范围。定标将会在后面的文章中补充介绍,定标过后再去实现C工程的定点版本。也就是说这个过程我们一共有四个版本的工程需要实现。matlab/python(1浮点、2定点)版本,C工程(3浮点、4定点),由于目前多数低功耗的平台都是要定点C工程的版本,所以这个版本是我们最终需要的版本,而实现这个版本需要经历上述1版本验证算法、2版本定标、3版本辅助定点版本实现这一系列环节,当然如果你要是高手请忽略上述正常人的路子。
而从《低功耗智能语音信号处理》这一标题上看,业务涉及面比较广,需要数学理论、工程经验、还有最近很火的AI相关方法。大体涉及下面几个大块。
1.信号处理环节(降噪、增强语言)—原始信号的预处理是影响训练模型好坏的重要原因
2.模型训练(唤醒、识别)
3.工程实现。(C工程、资源/性能)
习武通过最简单的套路练习基本功和入门是最好的方法。而今天我们就通过一种波束赋形方法,广义旁瓣相消器这一信号处理增强主瓣声音强度,降低旁瓣环境音的算法实现开始我们的入门基础套路练习。
1.背景和概念
单麦克风语音增强只需一路语音信号, 算法复杂度小, 硬件要求低,自1970年代以来已经得到了深入的研究, 提出了谱减法[1,2]、 最小均方误差方法[3,4], 维纳滤波法[5]和子空间方法[6]等等。 这些方法在通常情况下可以获得良好的噪声抑制性能, 然而在非理想条件下, 噪声总是来自于四面八方, 且其与语音信号在时间和频谱上常常是相互交叠的, 再加上回波和混响的影响(如图1.1), 利用单麦克风捕捉相对纯净的语音都是很困难的工作。 若在空间放置多个麦克风, 当语音和周围环境信息被多个麦克风聚集时, 麦克风阵列可以在期望方向上有效地形成一个波束去拾取波束内的信号, 并消除波束外的噪声, 从而达到同时提取声源和抑制噪声的目的, 所以利用阵列来取代单麦克风成为进一步提高语音增强效果的有效途径[7]。
阵列信号处理是信号处理的主要领域之一,一直以来都是
由于其在各个领域的广泛应用,过去对其进行了广泛的研究。
我们从工程中这一实际问题出发,慢慢的引出需要补充的课程,如信号与系统,甚至数学基础,以及所有工程中遇到的概念和问题,有时间和兴趣一个一个来梳理。
波束赋形(Beamforming),又称波束成型、空域滤波,是一种使用传感器阵列定向发送和接收信号的信号处理技术。波束赋形技术通过调整相位阵列的基本单元的参数,使得某些角度的信号获得相长干涉,而另一些角度的信号获得相消干涉。波束赋形既可用于信号发射端,又可用于信号接收端。该技术在雷达、无线通信、语音处理等领域应用广泛。本文所描述的广义旁瓣相消器(General sidelobe canceller,GSC)便是其中一种波束赋形算法。
2.算法原理与应用
2.1beamforming框架
首先以线麦阵列为例
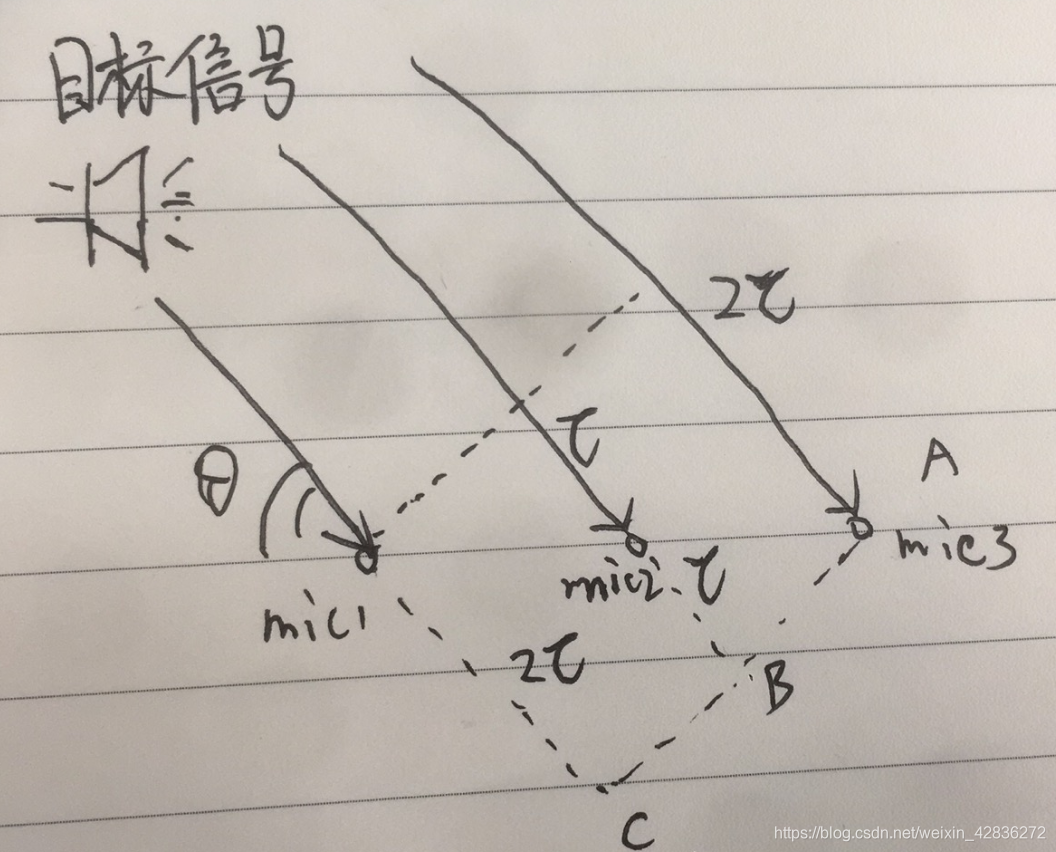
1)若目标信号垂直麦克风阵列入射,则通过简单的相加就可以获得想干信号;
2)如果目标信号以
入射时,由于相位上的偏差导致信号存在一定程度的相消现象。
针对上述现象采用适当的权重向量,补偿麦克风的时延,使
方向入射信号能够想干叠加。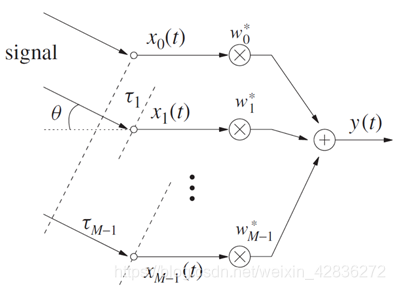
2.2beamforming最佳权向量
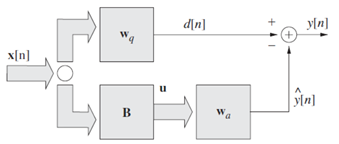
2.3GSC算法
3.MATLBA实现
4.C工程实现
5.总结
[1] Boll S F. Suppression of acoustic noise in speech using spectral subtraction. IEEE Transactions on Acoustics, Speech and Signal Processing, 1979, 27(2):113–120.
[2] Kamath S, Loizou P. A multi-band spectral subtraction method for enhancing speech corrupted by colored noise. Proceedings of IEEE International Conference on Acoustics,
Speech, and Signal Processing, Orlando, Florida, 2002, 675–678.
[3] Ephraim Y, Malah D. Speech enhancement using a minimum mean-square error shorttime spectral amplitude estimator. IEEE Transactions on Acoustics, Speech and Signal
Processing, 1984, 32(6):1109–1121.
[4] Ephraim Y, Malah D. Speech enhancement using a minimum mean-square error logspectral amplitude estimator. IEEE Transactions on Acoustics, Speech and Signal Processing, 1985, 33(2):443–445.
[5] Scalart P, Filho J V. Speech enhancement based on a priori signal to noise estimation. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing,
volume 2, Atlanta, GA, 1996, 2:629–632.
[6] Ephraim Y, Van Trees H. A signal subspace approach for speech enhancement. IEEE
Transactions on Speech and Audio Processing, 1995, 3(4):251–266.
[7] 崔玮玮. 基于麦克风阵列的声源定位与语音增强方法研究[D]. 北京: 清华大学, 2009.
未完待续…
