caffe自学-mnist示例程序详解
caffe中的mnist示例程序超详解,中间包含准备数据、网络模型解析、训练和测试全过程,以及遇到的error和解决方法
准备数据
下载数据
cd $CAFFE_ROOT
./data/mnist/get_mnist.sh 
文件内部: 
运行完成得到四个文件 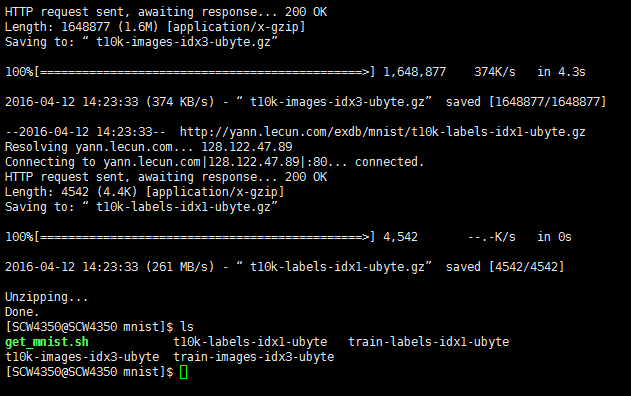
数据转化
./examples/mnist/create_mnist.sh 
该文件将数据转化为lmdb 
运行出错 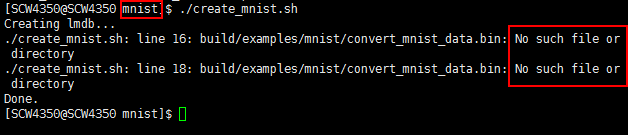
分析原因是在/examples/mnist文件夹内运行,不能访问build目录,因此转到caffe根目录下重新运行
依然出错,Permission denied没有权限 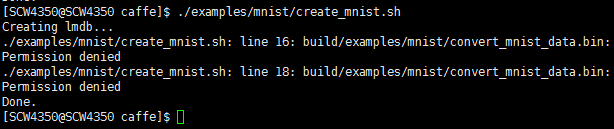
加权限后再执行 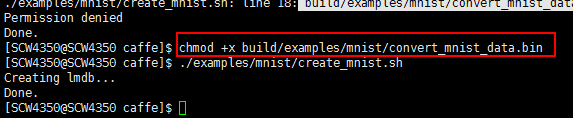
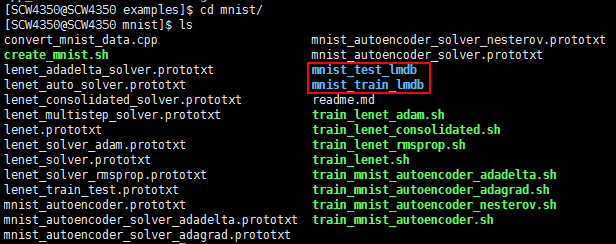
之后得到两个文件夹,就是caffe所需要的数据集了(lmdb格式)mnist_train_lmdb, and mnist_test_lmdb
定义网络结构
CNN的基本结构:
一个卷积层,后面连接一个pooling层,然后是另一个卷积层接pooling层,然后是两个全连接层,与多层感知器相似。
In general, it consists of a convolutional layer followed by a pooling layer, another convolution layer followed by a pooling layer, and then two fully connected layers similar to the conventional multilayer perceptrons.
以LeNet model为例具体解释网络结构,经典的LeNet模型使用Rectified Linear Unit (ReLU) 代替sigmoid函数来激活神经元。 $CAFFE_ROOT/examples/mnist/lenet_train_test.prototxt.
数据层
layer {
name: "mnist"//名字
type: "Data"//类型为:数据层
transform_param {
scale: 0.00390625//输入像素归一化到[0,1],0.00390625=1/256
}
data_param {
source: "mnist_train_lmdb"// lmdb源数据
backend: LMDB
batch_size: 64//分批处理,每批图像个数,过大会导致内存不够
}
top: "data"//生成two blobs,分别为data blob 和label blob
top: "label"
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
卷积层
layer {
name: "conv1"
type: "Convolution"
//参数调整的学习率
param { lr_mult: 1 }//权重的学习率与solver运行的学习率一致
param { lr_mult: 2 }//偏置的学习率是solver运行的学习率的2倍
convolution_param {
num_output: 20//输出20通道
kernel_size: 5//卷积核大小
stride: 1//步长跨度
weight_filler {
type: "xavier"//用 xavier算法初始化权重,根据输入和输出神经元的个数自动初始化weights
}
bias_filler {
type: "constant"//用常数初始化偏置
}
}
bottom: "data"//take the `data` blob
top: "conv1"// produces the `conv1` layer
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
Pooling层
layer {
name: "pool1"
type: "Pooling"
pooling_param {
kernel_size: 2//核大小2
stride: 2//步长2 (so no overlapping between neighboring pooling regions)
pool: MAX//取最大值
}
bottom: "conv1"
top: "pool1"
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
全连接层
// This defines a fully connected layer (known in Caffe as an `InnerProduct` layer) with 500 outputs.
layer {
name: "ip1"
type: "InnerProduct"
param { lr_mult: 1 }
param { lr_mult: 2 }
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
bottom: "pool2"
top: "ip1"
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
ReLU层
经典的LeNet模型使用Rectified Linear Unit (ReLU) 代替sigmoid函数来激活神经元。
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"//bottom和top blobs使用相同的名字,实现*in-place* operations to save some memory
}- 1
- 2
- 3
- 4
- 5
- 6
在ReLU层后面连接另一个全连接层ip2
layer {
name: "ip2"
type: "InnerProduct"
param { lr_mult: 1 }
param { lr_mult: 2 }
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
bottom: "ip1"
top: "ip2"
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Loss层
The softmax_loss layer implements both the softmax and the multinomial logistic loss (that saves time and improves numerical stability)
这一层同时实现了softmax和multinomial logistic loss,
layer {
name: "loss"
type: "SoftmaxWithLoss"
// It takes two blobs, It does not produce any outputs - all it does is to compute the loss function value, report it when backpropagation starts, and initiates the gradient with respect to `ip2`.
bottom: "ip2"// 连接the prediction
bottom: "label"//在data层中得到的label
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
Layer Rules
表示该层什么时候属于该网络
layer {
// ...layer definition...
include: { phase: TRAIN }//只在训练时包含
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include {
phase: TEST//只在测试时包含
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
训练参数配置
$CAFFE_ROOT/examples/mnist/lenet_solver.prototxt:
# The train/test net protocol buffer definition使用的网络结构
net: "examples/mnist/lenet_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100 //10,000除以test batch size 100
# Carry out testing every 500 training iterations. 每500次测试一次,输出score 0(准确率)和score 1(测试损失函数)
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations每100次迭代次数显示一次训练时lr(learningrate),和loss(训练损失函数)
display: 100
# The maximum number of iterations最大迭代次数
max_iter: 10000
# snapshot intermediate results每5000次迭代输出模型
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"//模型保存路径
# solver mode: CPU or GPU
solver_mode: GPU- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
训练模型
新建文件夹保存模型 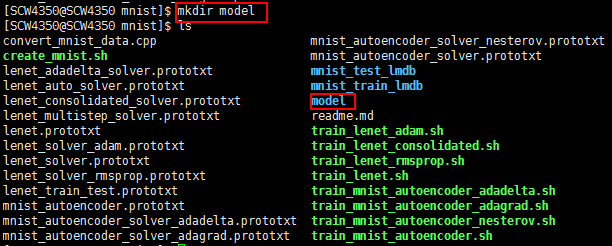
否则就会
建好文件夹后别忘记修改lenet_solver.prototxt 中的snapshot_prefix 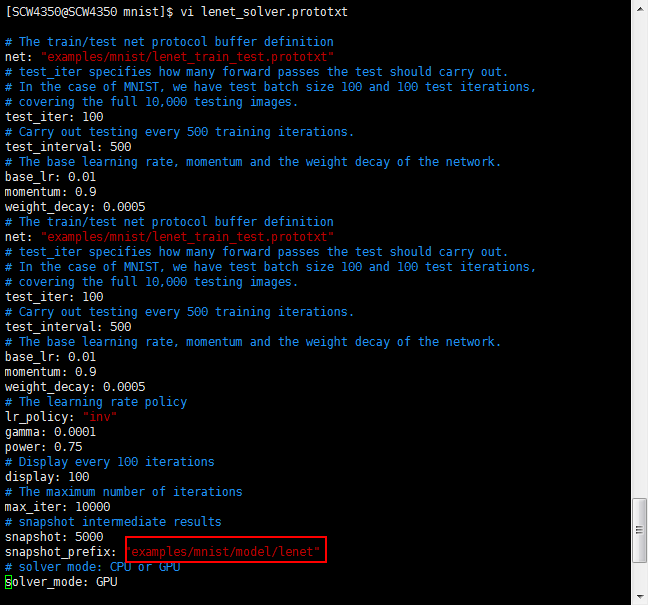
在配好训练网络输入路径,以及网络全局信息后,执行这个train_lenet.sh 脚本命令就可以开始训练网络了
cd $CAFFE_ROOT
./examples/mnist/train_lenet.sh
脚本.sh内容为训练指令
#!/usr/bin/env sh- 1
./build/tools/caffe train –solver=examples/mnist/lenet_solver.prototxt
脚本运行后会看见如下结果,显示各个层的细节和输出情形 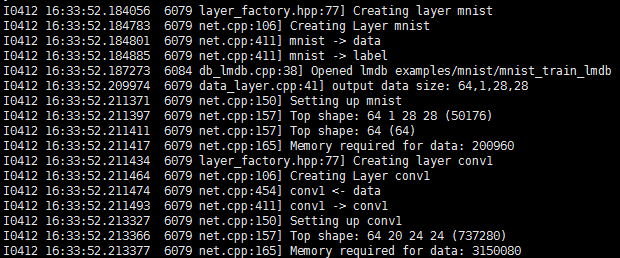
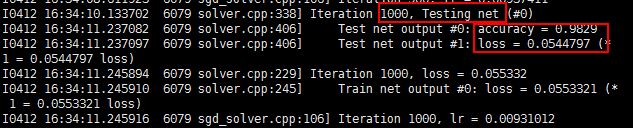
初始化后开始训练,每100次迭代输出loss,每1000次迭代进行一次测试(这里测试使用的是训练数据),
I1203 solver.cpp:204] Iteration 100, lr = 0.00992565//迭代的学习率
I1203 solver.cpp:66] Iteration 100, loss = 0.26044//训练函数
…
I1203 solver.cpp:84] Testing net
I1203 solver.cpp:111] Test score #0: 0.9785//测试准确率
I1203 solver.cpp:111] Test score #1: 0.0606671//测试损失函数 
每5000次迭代输出一个模型保存下来,模型存储成一个binary protobuf文件,名字是lenet_iter_5000,这个训练好的模型可以被用来做实际应用。 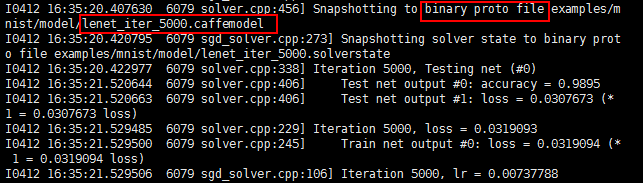
训练以到达迭代最大次数终止,训练结束 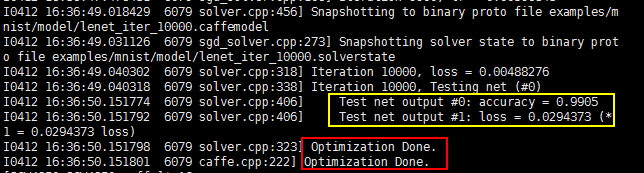
可以在指定输出的模型路径下看到相关模型(带有caffemodel的就是模型文件) 
另外:若想使用固定步长来降低学习率,可以使用文件lenet_multistep_solver.prototxt
# The train/test net protocol buffer definition
net: "examples/mnist/lenet_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "multistep"
gamma: 0.9
stepvalue: 5000
stepvalue: 7000
stepvalue: 8000
stepvalue: 9000
stepvalue: 9500
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 10000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet_multistep"
# solver mode: CPU or GPU
solver_mode: GPU- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
测试模型
调用训练好的模型测试
./build/tools/caffe.bin test -model=examples/mnist/lenet_train_test.prototxt -weights=examples/mnist/model/lenet_iter_10000.caffemodel -gpu=0
如果没有GPU则使用
./build/tools/caffe.bin test -model=examples/mnist/lenet_train_test.prototxt -weights=examples/mnist/model/lenet_iter_10000.caffemodel
解释:
1、先是test表明是要评价一个已经训练好的模型。
2、然后指定模型prototxt文件,这是一个文本文件,详细描述了网络结构和数据集信息。
在测试时数据层转到了测试集: 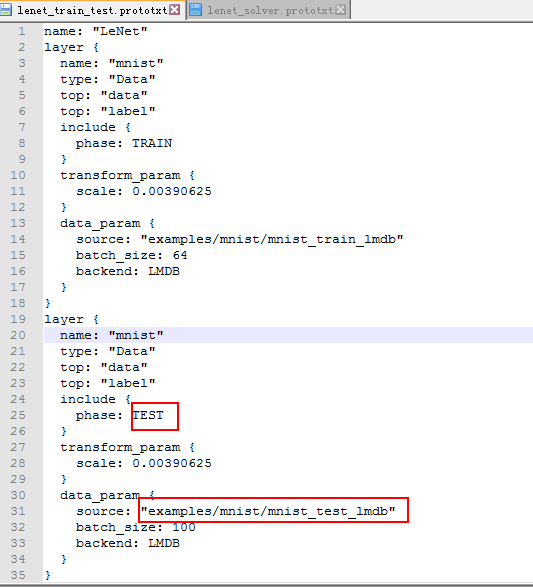
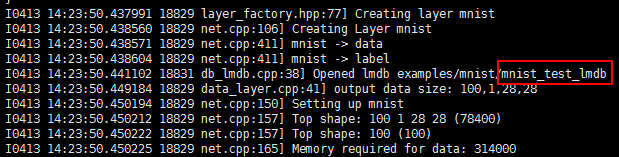
3、然后指定模型的具体的权重weights。权重为训练好的模型examples/mnist/model/lenet_iter_10000.caffemodel中的参数


测试完成,准确率为0.9868 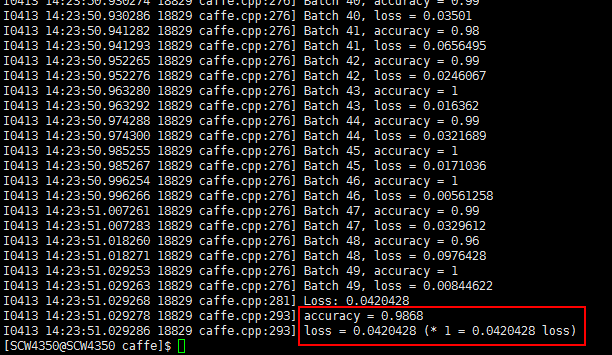
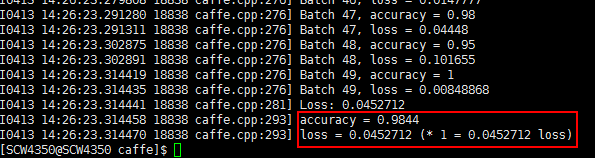
修改模型名称,换用5000次迭代时生成的模型

到这里就是对caffe最基础的使用了,更多的信息请参照caffe官网1,我也会继续在这里记录“end-to-end”的学习过程。第一篇博客,也是希望自己能在学术上坚持下去吧!