首先hashmap在多个线程同时对其操作的时候造成的脏读很统一理解,比如一个线程A对hashmap进行读操作,一个线程B对hashmap就行写操作。线程b先进入put方法中,此时还没有写数据的时候线程a轮转执行,并一直执行到结束,假设执行取到数据为条,这时线程b继续执行添加了一条数据。那么最后hashmap的数据是4条,但是线程a只读取了三条。
不论是读或者写,或者修改,在多线程环境下都会出现数据的不一致的问题。但是更为严重的是hashmap会在某些时候让程序直接陷入死循环。
我们都知道HashMap初始容量大小为16,一般来说,当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的元素都需要被重算一遍。这叫rehash,这个成本相当的大
首先是单线程环境下rehash过程如下所示
1、假设我们的hash算法是简单的key mod一下表的大小(即数组的长度)。
2、最上面是old hash表,其中HASH表的size=2,所以key=3,5,7在mod 2 以后都冲突在table[1]这个位置上了。
3、接下来HASH表扩容,resize=4,然后所有的<key,value>重新进行散列分布,过程如下:
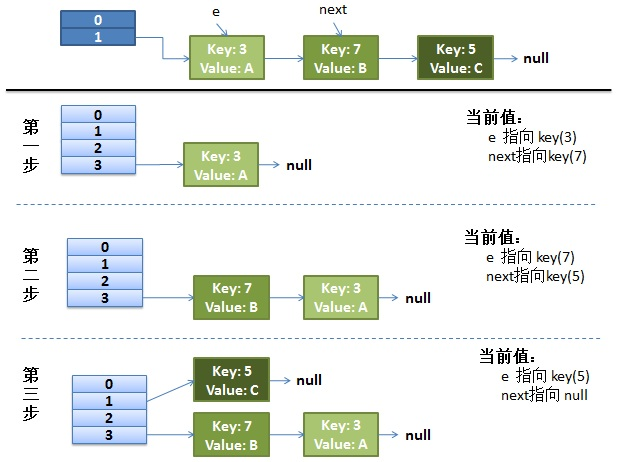
在单线程情况下,一切看起来都很美妙,扩容过程也相当顺利。接下来看下并发情况下的扩容。
并发情况下的扩容
1、首先假设我们有两个线程,分别用红色和蓝色标注了。
2、扩容部分的源代码:

1 void transfer(Entry[] newTable) { 2 Entry[] src = table; 3 int newCapacity = newTable.length; 4 for (int j = 0; j < src.length; j++) { 5 Entry<K,V> e = src[j]; 6 if (e != null) { 7 src[j] = null; 8 do { 9 Entry<K,V> next = e.next; 10 int i = indexFor(e.hash, newCapacity); 11 e.next = newTable[i]; 12 newTable[i] = e; 13 e = next; 14 } while (e != null); 15 } 16 } 17 }
3、如果在线程一执行到第9行代码就被CPU调度挂起,去执行线程2,且线程2把上面代码都执行完毕。我们来看看这个时候的状态:
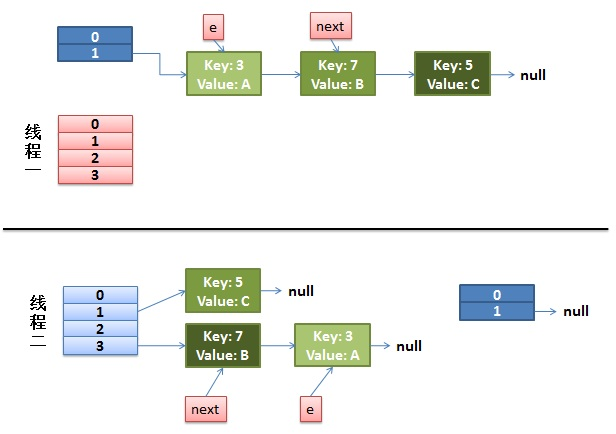
4、接着CPU切换到线程一上来,执行8-14行代码,首先安置3这个Entry:
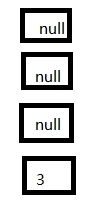
这里需要注意的是:线程二已经完成执行完成,现在table里面所有的Entry都是最新的,就是说7的next是3,3的next是null;现在第一次循环已经结束,3已经安置妥当。看看接下来会发生什么事情:
1、e=next=7;
2、e!=null,循环继续
3、next=e.next=3
4、e.next 7的next指向3
5、放置7这个Entry,现在如图所示:

放置7之后,接着运行代码:
1、e=next=3;
2、判断不为空,继续循环
3、next= e.next 这里也就是3的next 为null
4、e.next=7,就3的next指向7.
5、放置3这个Entry,此时的状态如图:
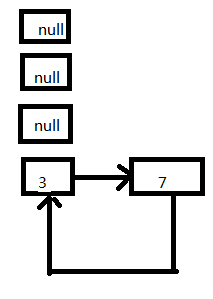
这个时候其实就出现了死循环了,3移动节点头的位置,指向7这个Entry;在这之前7的next同时也指向了3这个Entry。
代码接着往下执行,e=next=null,此时条件判断会终止循环。这次扩容结束了。但是后续如果有查询(无论是查询的迭代还是扩容),都会hang死在table【3】这个位置上。现在回过来看文章开头的那个Demo,就是挂死在扩容阶段的transfer这个方法上面。