Aggregated Residual Transformations for Deep Neural Networks----2017ResNext
Abstract
我们提出了一种用于图像分类的简单,高度模块化的网络体系结构。我们的网络是通过重复构建模块来构建的,该模块聚合具有相同拓扑的一组转换。我们的简单设计导致了同类的多分支架构,仅需设置几个超参数。此策略提供了一个新维度,我们将其称为“基数”(转换集的大小),它是深度和宽度维度之外的一个重要因素。在ImageNet-1K数据集上,我们根据经验表明,即使在保持复杂性的限制条件下,增加基数也可以提高分类精度。此外,当我们增加容量时,增加基数比深入或更广泛更有效。我们的模型名为ResNeXt,是我们进入2016年ILSVRC分类任务的基础,我们获得了第二名。我们进一步在ImageNet-5K集和COCO检测集上对ResNeXt进行了研究,其结果也比ResNet同类要好。该代码和模型可以在线公开获得1。
1.Introduction

视觉识别的研究正在经历从“功能工程”到“网络工程”的转变[25、24、44、34、36、38、14]。与传统的手工设计特征(例如,SIFT [29]和HOG [5])相反,神经网络从大规模数据中学习的特征[33]在训练过程中所需的人力最少,并且可以转移到各种识别任务中[7,10,28]。尽管如此,人类的努力已经转移到设计用于学习表示的更好的网络体系结构上。
随着超参数(宽度2,滤波器大小,步幅等)数量的增加,设计体系结构变得越来越困难,尤其是当层数很多时。 **VGG网络[36]展示了一种构建非常深的网络的简单而有效的策略:堆叠相同形状的构建块。**该策略由ResNets [14]继承,后者堆叠相同拓扑的模块。这个简单的规则减少了对超参数的自由选择,并且深度被暴露为神经网络的基本维度。此外,我们认为,此规则的简单性可以降低将超参数过度适应特定数据集的风险。 VGGnet和ResNets的健壮性已通过各种视觉识别任务[7、10、9、28、31、14]和涉及语音[42、30]和语言[4、41、20]的非视觉任务得到了证明。
与VGG网络不同,Inception模型系列[38,17,39,37]已经证明,精心设计的拓扑能够以较低的理论复杂性实现令人信服的准确性。**初始模型随着时间的推移而发展[38,39],但是一个重要的共同属性是拆分转换合并策略。**在Inception模块中,将输入分为几个低维嵌入(按1×1卷积),由一组专用过滤器(3×3、5×5等)转换,并通过级联合并。可以看出,该体系结构的解空间是在高维嵌入下运行的单个大层(例如5×5)的解空间的严格子空间。Inception模块的拆分变换合并行为是期望接近大型和密集层的表示能力,但计算复杂度要低得多。
尽管精度很高,但是Inception模型的实现伴随着一系列复杂的因素-过滤器的数量和大小是为每个单独的转换量身定制的,并且模块是逐步定制的。尽管这些组件的精心组合产生了出色的神经网络配方,但是通常不清楚如何使Inception架构适应新的数据集/任务,尤其是在要设计许多因素和超参数时。
在本文中,**我们提出了一种简单的体系结构,该体系结构采用VGG / ResNets的重复层策略,同时以简单,可扩展的方式利用拆分转换合并策略。**我们网络中的一个模块执行一组转换,每个转换都在低维嵌入中进行,其输出通过求和来聚合。我们追求这种想法的简单实现-要聚合的转换都具有相同的拓扑(例如,图1(右))。这种设计使我们可以扩展到任意数量的转换而无需专门的设计。
有趣的是,在这种简化的情况下,我们表明模型具有其他两种等效形式(图3)。图3(b)中的重构与Inception-ResNet模块[37]相似,因为它连接了多个路径;但是我们的模块与所有现有的Inception模块不同,因为我们所有的路径共享相同的拓扑,因此,路径可以很容易地隔离为要研究的因素。通过更简洁的表述,可以通过Krizhevsky等人的分组卷积[24](图3(c))来重塑我们的模块,但是这些卷积是作为工程折衷而开发的。
我们凭经验证明,即使在保持计算复杂度和模型大小的限制条件下,我们的聚合变换也优于原始ResNet模块-例如,图1(右)旨在保持FLOP的复杂度和图1中的参数数量剩下)。我们强调,虽然通过增加容量(更深或更宽)来提高精度相对容易,但是在文献中很少有在保持(或降低)复杂性的同时提高精度的方法。
我们的方法表明,基数(转换集的大小)是一个具体的,可测量的维度,除了宽度和深度的维度外,它也是至关重要的。实验表明,增加基数是获得精度的一种更有效的方法,而不是更深或更宽,尤其是当深度和宽度开始为现有模型提供递减的收益时。
我们的神经网络名为ResNeXt(建议下一维),在ImageNet分类上的表现优于ResNet-101 / 152 [14],ResNet-200 [15],Inception-v3 [39]和Inception-ResNet-v2 [37]。 数据集。 特别是,101层ResNeXt可以比ResNet-200 [15]获得更好的精度,但复杂度仅为50%。 此外,ResNeXt的设计比所有Inception模型都简单得多。 ResNeXt是我们提交给ILSVRC 2016分类任务的基础,在该任务中我们获得了第二名。 本文进一步评估了ResNeXtona较大的ImageNet-5Kset和COCOobject检测数据集[27],显示出始终如一的精度优于ResNet。 我们希望ResNeXt还将很好地推广到其他视觉(和非视觉)识别任务。
2.Related Work
多分支卷积网络。 Inception模型[38、17、39、37]是成功的多分支体系结构,其中每个分支都是经过精心定制的。ResNets[14]可以看作是两个分支的网络,其中一个分支是身份映射。深度神经决策森林[22]是具有学习的分裂功能的树状多分支网络。
分组卷积。如果不是更早的话,分组卷积的使用可以追溯到AlexNet论文[24]。 Krizhevsky等人给出的动机。 [24]用于在两个GPU上分配模型。 Caffe [19],Torch [3]和其他库支持分组卷积,主要是为了与AlexNet兼容。据我们所知,很少有证据表明利用分组卷积来提高准确性。分组卷积的一种特殊情况是通道级卷积,其中组数等于通道数。通道级卷积是[35]中可分离卷积的一部分。
压缩卷积网络。分解(在空间[6,18]和/或通道[6,21,16]级别)是一种广泛采用的技术,用于减少深度卷积网络的冗余并加速/压缩它们。 Ioannou等 [16]提出了一种“根”模式的网络以减少计算,并且根中的分支是通过分组卷积实现的。这些方法[6、18、21、16]已显示出精确的折衷方案,具有较低的复杂度和较小的模型尺寸。我们的方法不是压缩,而是一种凭经验显示更强大的表示能力的体系结构。
集合。平均一组独立训练的网络是提高准确性的有效解决方案[24],在识别竞赛中被广泛采用[33]。 Veit等人[40]将单个ResNet解释为浅层网络的集合,这是由ResNet的累加行为导致的[15]。我们的方法利用加法来汇总一组转换。但是我们认为将我们的方法视为集合是不精确的,因为要聚合的成员是联合训练的,而不是独立训练的。
3.Method
3.1. Template模板

我们遵循VGG / ResNets采用高度模块化的设计。 我们的网络由一堆残差块组成。 这些块具有相同的拓扑,并且受VGG / ResNets启发遵循两个简单的规则:(i)如果生成相同大小的空间图,则这些块共享相同的超参数(宽度和过滤器大小),以及(ii )每次将空间图下采样2倍时,块的宽度就乘以2倍。第二条规则可确保计算复杂性,以FLOPs(浮点运算,以#为单位) 乘法-加法),对于所有块而言大致相同。
使用这两个规则,我们只需要设计一个模板模块,就可以相应地确定网络中的所有模块。 因此,这两个规则极大地缩小了设计空间,使我们可以专注于一些关键因素,这些规则构建的网络如表1所示。
3.2. Revisiting Simple Neurons
人工神经网络中最简单的神经元执行内积(加权和),这是由完全连接的卷积层完成的基本转换。 内部产品可以被认为是聚合转化的一种形式:

其中x = [x 1,x 2,…,x D]是神经元的D通道输入向量,而w i是第i个通道的过滤器权重。 该操作(通常包括一些输出非线性)被称为“神经元”。 参见图2。
可以将上述操作重组为拆分,转换和聚合的组合。 (i)分割:将向量x切片为低维嵌入,在上面,它是一维子空间x i。 (ii)变换:对低维表示进行变换,并且在上面,仅对其进行了缩放:wixi。 (iii)汇总:所有嵌入中的转换均由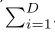 汇总。
汇总。
3.3. Aggregated Transformations汇总转换
鉴于以上对简单神经元的分析,我们考虑用更通用的函数代替基本变换(wi xi),该函数本身也可以是网络。 与事实证明增加网络深度的“网络中网络” [26]相反,我们证明了“神经元网络”沿新的维度扩展。
正式地,我们将汇总的转换表示为: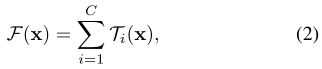
其中T i(x)可以是任意函数。 类似于简单的神经元,T i应将x投射到(可选为低维)嵌入中,然后对其进行转换。
**在等式(2)中,C是要聚合的转换集的大小。我们将C称为基数[2]。**在等式(2)中,C处于与等式(1)中的D相似的位置,但是C不必等于D,并且可以是任意数。虽然宽度的尺寸与简单转换的数量(内部乘积)有关,但我们认为基数的尺寸控制着更复杂的转换的数量。我们通过实验表明,基数是一个基本维度,并且比宽度和深度的维度更有效。
在本文中,我们考虑了一种设计转换函数的简单方法:所有T i都具有相同的拓扑结构,这扩展了重复相同形状的层的VGG样式策略,这有助于隔离一些因素并扩展进行任何大量的转换。如图1(右)所示,我们将单个变换T i设置为 bottleneck形体系结构[14]。在这种情况下,每个Ti中的第一个1×1层都会产生低维嵌入。

等式(2)中的聚合变换充当残差函数[14](右图1):
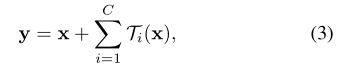
其中y是输出。
与Inception-ResNet的关系。一些张量操纵显示图1(右)中的模块(也在图3(a)中显示)等效于图3(b)。 图3(b)与Inception-ResNet [37]块相似,因为它涉及到残差函数中的分支和级联。但是与所有Inception或Inception-ResNet模块不同,我们在多个路径之间共享相同的拓扑。我们的模块需要最少的额外精力来设计每个路径。
与分组卷积的关系。使用分组卷积的符号,上述模块变得更加简洁[24]。 图3(c)表示了这种重新构造。所有低维嵌入(第一个1×1层)都可以由单个更宽的层(例如,图3中的1×1、128-d)代替C))。当分组卷积层将其输入通道分为几组时,它实质上是由分组卷积层完成的。图3(c)中的分组卷积层执行32组卷积,其输入和输出通道为4维。分组的卷积层将它们连接起来作为该层的输出。除了图3(c)是一个较宽但稀疏连接的模块,图3(c)中的块看起来像图1(左)中的原始瓶颈残留块。

我们注意到,仅当块的深度≥3时,重新构造才会产生非平凡的拓扑。 如果该块的深度= 2(例如[14]中的基本块),则重新形成将导致一个很小的,密集的模块。 参见图4中的插图。
讨论。 我们注意到,尽管我们提出了表现出级联(图3(b))或成组卷积(图3(c))的公式,但这种公式并不总是适用于等式(3)的一般形式,例如 变换T i具有任意形式并且是异构的。在本文中,我们选择使用同质形式,因为它们更简单且可扩展。 在这种简化情况下,图3(c)形式的分组卷积有助于简化实现。
3.4. Model Capacity

下一部分的实验将表明,在保持模型的复杂性和参数数量的情况下,我们的模型可以提高准确性。 这不仅在实践中令人感兴趣,而且更重要的是,参数的复杂性和数量代表了模型的固有能力,因此经常被作为深度网络的基本属性进行研究[8]。
当我们在保留复杂性的同时评估不同的基数C时,我们希望最小化其他超参数的修改。 我们选择调整瓶颈的宽度(例如,图1(右)中的4-d),因为它可以与块的输入和输出隔离。 该策略不会对其他超参数(块的深度或输入/输出宽度)产生任何影响,因此有助于我们关注基数的影响。
在图1(左)中,原始的ResNet瓶颈块[14]具有256·64 + 3·3·64·64 + 64·256≈70k参数和成比例的FLOP(在相同的特征图尺寸上)。 瓶颈宽度为d时,图1(右)中的模板具有:
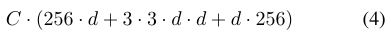
参数和比例FLOP。 当C = 32且d = 4时,等式(4)≈70k。 表2显示了基数C和瓶颈宽度d之间的关系。
因为在3.1节中采用了这两个规则。上述近似相等在ResNet瓶颈块和我们的ResNeXt之间的所有阶段都是有效的(特征映射大小变化的子采样层除外)。 表1比较了原始ResNet-50和具有类似容量的ResNeXt-50。 我们注意到,复杂度只能近似保留,但是复杂度的差异很小,不会使我们的结果产生偏差。
4.Implementation details
我们的实现遵循[14]和fb.resnet.torch [11]的公开代码。在ImageNet数据集上,使用[11]实现的[38]的比例和长宽比增强,从调整大小后的图像中随机裁剪输入图像224×224。快捷方式是身份连接,除了那些不断扩大的尺寸(投影[14]中的B型)以外。如[11]中所建议的,conv3、4和5的下采样是通过每个阶段的第一个块的3×3层中的步幅2卷积完成的,如[11]中所述。我们在8个GPU上使用最小批大小为256的SGD (每个GPU 32个)。权重衰减为0.0001,动量为0.9。我们从0.1的学习率开始,然后使用[11]中的进度表将其除以10三次。我们采用[13]的权重初始化。在比较比较中,我们从短边为256的图像中评估单个224×224中心作物的误差。
我们的模型是通过图3(c)的形式实现的。我们在图3(c)中的卷积之后立即执行批归一化(BN)[17]。 ReLU是在每个BN之后立即执行的,期望添加到快捷方式之后执行ReLU的块的输出,如下[14]。
我们注意到,当如上所述适当地解决了BN和ReLU时,图3中的三种形式是严格等效的。我们已经训练了所有三种形式并获得了相同的结果。我们选择通过图3(c)来实现,因为它比其他两种形式更简洁,更快。
5.Experiments
5.1. Experiments on ImageNet-1K



我们对1000级ImageNet分类任务进行了消融实验[33]。我们按照[14]构建50层和101层残差网络。我们只需用我们的块替换ResNet50 / 101中的所有块。
记号。因为我们在3.1节中采用了这两个规则。对于我们来说通过模板引用体系结构就足够了。例如,表1显示了由基数= 32,瓶颈宽度= 4d的模板构建的ResNeXt-50。(图3)。为了简单起见,将该网络表示为ResNeXt-50(32×4d)。我们注意到,模板的输入/输出宽度固定为256-d(图3),并且每次对特征图进行二次采样时,所有宽度都会加倍(参见表1)。
基数与宽度。首先,我们在保留表2所列复杂性的情况下,评估了基数C和瓶颈宽度之间的权衡。表3显示了结果,图5显示了误差与历元的关系曲线。与ResNet-50(表3顶部和图5左)相比,32×4d ResNeXt-50的验证误差为22.2%,比ResNet基线的23.9%低1.7%。随着基数C从1增加到32,同时保持复杂度,错误率不断降低。此外,32×4d ResNeXt的训练误差也比ResNet对应物低得多,这表明增益不是来自正则化而是来自更强的表示。
在ResNet-101的情况下观察到类似的趋势(右图5,表3底部),其中32×4d ResNeXt-101比ResNet-101的性能高出0.8%。尽管验证误差的这种改进小于50层情况,但训练误差的改进仍然很大(ResNet-101为20%,32×4d ResNeXt-101为16%,右图5)。实际上,更多的训练数据将扩大验证错误的范围,正如我们在下一部分中设置的ImageNet-5K上所示。
表3还表明,**在保留复杂性的情况下,当瓶颈宽度较小时,以减小宽度为代价增加基数会开始显示饱和精度。我们认为,在这种折衷方案中保持宽度减小是不值得的。**因此,下面我们采用不小于4d的瓶颈宽度。
增加基数与更深/更广。接下来,我们通过增加基数C或增加深度或宽度来研究增加的复杂性。以下比较也可以视为参考ResNet-101基线的2个FLOP。我们比较了具有〜150亿FLOP的以下变体。 (i)深入到200层。我们采用[11]中实现的ResNet-200 [15]。(ii)通过增加瓶颈宽度来扩大范围。 (iii)通过将C加倍来增加基数。
表4显示,与ResNet-101基准相比(22.0%),复杂度提高2倍可减少错误,但是当深度更大(ResNet200,降低0.3%)或更广泛(ResNet-101,更宽0.7%)时,改进很小)。
相反,增加基数C显示出比深入或更广泛更好的结果。 2×64d ResNeXt-101(即将1×64dResNet-101基线加倍并保持宽度)可使top-1误差降低1.3%至20.7%。 64×4d ResNeXt-101(即在32×4d ResNeXt-101上加倍C并保持宽度)会将top-1误差降低到20.4%。
我们也注意到32×4d ResNet-101(21.2%)的性能要比更深的ResNet-200和更宽的ResNet-101更好,尽管它的复杂度仅为50%左右。这再次表明,基数比深度和宽度的维度更有效。
残差连接。 下表显示了剩差(快捷)连接的影响:



从ResNeXt-50删除快捷方式会使错误增加3.9点,达到26.1%。从其ResNet-50同类产品中删除快捷方式的情况要差得多(31.2%)。这些比较表明,残差连接有助于优化,而汇总转换则更能代表这些事实,这一事实表明,它们始终比带有或不带有残差连接的同行表现更好。
性能。为简单起见,我们使用Torch的内置分组卷积实现,而无需进行特殊优化。我们注意到该实现是蛮力的,而不是并行化友好的。在NVIDIA M40的8个GPU上,表3中训练32×4d ResNeXt-101每个微型批处理花费0.95s,而具有相似FLOP的ResNet-101基线为0.70s。我们认为这是一个合理的开销。我们希望精心设计的较低层实现(例如,在CUDA中)将减少这种开销。我们还期望CPU的推理时间会减少开销。训练2x复杂度模型(64×4d ResNeXt-101)每个微型批处理需要1.7s,在8个GPU上总共需要10天。
与最新结果进行比较。表5显示了对ImageNet验证集进行的单作物测试的更多结果。除了测试224×224作物外,我们还按照[15]评估320×320作物。我们的结果与ResNet,Inception-v3 / v4和Inception-ResNet-v2相比具有优势,单次裁剪的top-5错误率达到4.4%。此外,我们的体系结构设计比所有Inception模型都简单得多,并且需要手动设置的超参数要少得多。
ResNeXt是我们参加ILSVRC 2016分类任务的基础,在该研究中我们获得了第二名。我们注意到许多模型(包括我们的模型)在使用多尺度和/或多作物测试后开始在该数据集上变得饱和。使用[14]中的多尺度密集测试,单模型的top-1 / top-5错误率为17.7%/ 3.7%,与Inception-ResNet-v2的单模型结果为17.8%/ 3.7相当%采用多尺度,多作物测试。我们在测试集上获得前三名错误的整体结果为3.03%,与获胜者的2.99%和Inception-v4 / Inception-ResNet-v2的3.08%相提并论[37]。
5.2. Experiments on ImageNet-5K
ImageNet-1K的性能似乎已经达到饱和,但是我们认为这不是因为模型的功能,而是因为数据集的复杂性。接下来,我们在具有5000个类别的较大ImageNet子集中评估模型。
我们的5K数据集是完整ImageNet-22K集的子集[33]。 5000个类别包括原始ImageNet-1K类别和另外4000个类别,这些类别在整个ImageNet集中的图像数量最多。 5K集拥有680万张图像,约为1K集的5倍。目前尚无正式的训练/验证划分信息,因此我们选择对原始ImageNet-1K验证集进行评估。在此1K级值集上,可以将模型评估为5K方式分类任务(所有标签均为其他4K类别的标签都会自动错误)或1K方式分类任务(softmax仅适用于1K课程)。
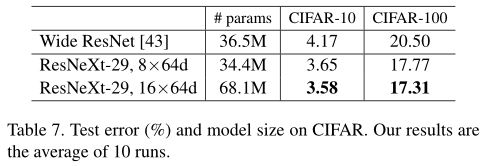
实现细节与第四节中的相同。 5K训练模型都是从头开始训练的,并且与1K训练模型训练的小批数量相同(因此为1/5×历元)。表6和图6显示了保留的复杂度下的比较。与ResNet-50相比,ResNeXt-50降低了5K-way top-1错误3.2%,与ResNet-101相比,ResNetXt-101降低了5K-way top-1错误2.3%。在1K方向误差上观察到类似的差距。这些证明了ResNeXt具有更强的代表性。
此外,我们发现,在5K集上训练的模型(表6中的1K方向误差为22.2%/ 5.7%)与在1K集上训练的模型(表3中的21.2%/ 5.6%)相比具有竞争优势,验证集上执行相同的1K方式分类任务。无需增加训练时间(由于相同的迷你批次数量)并且无需进行微调即可获得此结果。我们认为这是一个有希望的结果,因为对5K类别进行分类的培训任务更具挑战性。
