针对有些动态网站,需要用到自动化测试工具。为了避免封IP保证抓取到数据,使用了IP代理;为了提高效率,想要设置成无界面模式,但是不管是windows下还是Linux下,一旦两者结合时,直接报错。
报错代码如下:
selenium.common.exceptions.WebDriverException: Message: unknown error: failed to wait for extension background page to load: chrome-extension://kmfmlecicfolmocapbbhilogaebehllm/_generated_background_page.html
from unknown error: page could not be found: chrome-extension://kmfmlecicfolmocapbbhilogaebehllm/_generated_background_page.html网上说报这个错的原因是因为浏览器无头模式 和 代理插件不兼容的原因,目前还没有很好的解决方法,但是可以走其他方式,下面是个人的一些实际经验。
说明:方案一在windows系统下还是无效的,方案二理论上所有系统通用,需要的可以直接看方案二
方案一:Linux下伪无界面模式
1.selenium+chromedriver 使用代理插件+无界面时报错:
错误代码如上就是上面给出的
差点翻遍谷歌和百度都没有找到解决办法.快绝望的时候看到篇博客,完美解决,博客原文后面再找时没找到了....
2.安装Xvfb虚拟界面工具和xdpyinfo
yum install Xvfb -y
yum install xdpyinfo3. 安装Python虚拟桌面 pyvirtualdisplay
pip3 install pyvirtualdisplay4. 在chromedriver启动前启动一个显示器
from selenium import webdriver
from pyvirtualdisplay import Display
display = Display(visible=0, size=(800, 800))
display.start()5. 浏览器属性设置
chrome_options = Options()
proxy_auth_plugin_path = self.set_id_proxy()
chrome_options.add_extension(proxy_auth_plugin_path)
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('blink-settings=imagesEnabled=false')
prefs = {'profile.managed_default_content_settings.images': 2}
chrome_options.add_experimental_option('prefs', prefs)
#chrome_options.add_argument('--headless') #不设置,其实是有界面
self.driver = webdriver.Chrome(options=chrome_options)
self.wait = WebDriverWait(self.driver, 20) # 设置等待时间20秒6. 测试
self.driver.get(url)
print(self.driver.page_source)成功获取到页面数据
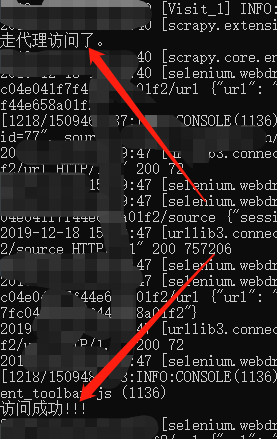
方案二:借助scrapy框架,windows,linux系统下均完美运行
1.新建scrapy项目,新建spider,items.py中添加好相关字段
2.setting.py中将下载中间件DOWNLOADER_MIDDLEWARES 和管道ITEM_PIPELINES打开
DOWNLOADER_MIDDLEWARES = {
'wbScrapy.middlewares.wbscrapyDownloaderMiddleware': 543,
}ITEM_PIPELINES = {
'wbScrapy.pipelines.wbscrapyPipeline': 300,
}3.修改middlewares.py,在process_request(self, request, spider)函数中添加代理信息
#具体代理信息自行配置,这里是阿布云
def process_request(self, request, spider):
request.meta["proxy"] = proxyServer
request.headers["Proxy-Authorization"] = proxyAuth4. spider爬虫文件中:
# -*- coding: UTF-8 -*-
import scrapy
from wbScrapy.items import WbscrapyItem
from scrapy import Request
import time
import re
from selenium import webdriver
from time import sleep
import random
import json
from lxml import etree
import requests
class WbSpider(scrapy.Spider):
name = 'spiderNames'
allowed_domains = ['']
start_urls = ['']
bash_url = ''
def __init__(self):
'''
浏览器配置初始化
'''
self.chromedriverPath = r"./chromedriver.exe" #windows下驱动位置,linux下不需要
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--headless')
chrome_options.add_argument('blink-settings=imagesEnabled=false')
chrome_options.add_argument('--disable-gpu')
prefs = {'profile.managed_default_content_settings.images': 2}
chrome_options.add_experimental_option('prefs', prefs)
self.driver = webdriver.Chrome(executable_path=self.chromedriverPath, options=chrome_options)
self.driver.set_page_load_timeout(60)
self.flag = True
# 当爬虫退出的时候关闭Chrome
def spider_closed(self, spider):
self.driver.quit()
def start_requests(self):#调起爬虫中间件,让脚本走代理
full_url = "https://www.baidu.com/" #随便写个接口进来,转走
yield scrapy.Request(full_url,callback=self.parse, dont_filter=True)
def parse(self,reponse):
item = WbscrapyItem()
#......根据需求直接编写抓取数据代码最终效果:通过终端打印+本地抓取到的数据,说明无界面+代理插件生效