转自公众号-AI圈终身学习,一个致力于提供有情怀的集训互享开源平台,欢迎关注。
不用框架,代码手撸深度神经网络,系列文章。适合零基础入门,更适合进阶。系列文章,提前关注不迷路。适宜人群:
- 深度学者初学者
- 深度学习面试进阶者
- 有意向转行AI的IT从业者
- 对深度学习感兴趣的在校大学生
纸上得来终觉浅,文集所有代码地址:https://github.com/AIGroup-Z/deep-neural-network
写在前面
在上一节,我们已经用python实现了感知器,并且用其实现了与门(and)与或门(or)函数。读者肯定觉得不过瘾,因此本节将为您介绍人工智能领域中的一个基础任务-二分类,并将带您用我们实现的感知器完成它。
另外请小白读者注意,本节中的作图代码以及数据预处理不是重点,只是辅助理解的,所以代码看不懂也没关系。那就让我们开始吧。
一、什么是二分类任务?
这里我不想说太多术语,我直接用例子解释。做二分类的整个流程如下:
-
1.准备训练数据 假设我们有100张鸢尾花的图片,首先我们人为进行标记,标记出来其中50张是山鸢尾,另外50张是变色鸢尾。
-
2.模型训练 我们用这100张图片包含的数据来训练模型。
-
3.预测图片 给一张新的图片,机器能识别图片是山鸢尾还是变色鸢尾。

我们看到第一步里需要人为进行标记,这种需要人工标记数据的我们叫做监督学习。所有人工智能领域里,数据是非常重要的,没有数据我们的工作就没法开展。
幸运的是sklearn中已经有人工标注好的鸢尾花数据集,所以我们不用为了学习去人工标注100张鸢尾花的图片。

本文会带领你做一个鸢尾花感知器。接下来我们介绍下这个在AI圈被玩坏的鸢尾花数据集。
二、鸢尾花数据集
鸢尾花数据集中有三类数据,分别是山鸢尾,变色鸢尾和维吉尼亚鸢尾,各有50个,总共有150个。数据集的特征数据为:
- sepal length(萼片长度)
- sepal width(萼片宽度)
- petal length(花瓣长度)
- petal width(花瓣宽度)
不明白?我们查看一下前五条数据就知道了:
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
# iris.data包含一个(150, 4)的数据,设置列名为iris.feature_names
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# iris.target为类别标签(150, 1)
df['label'] = iris.target
df.head()
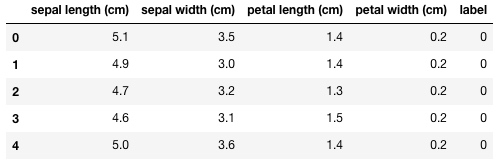
在这个数据集里,特征单位都是厘米(cm),label为0的是山鸢尾, label为1的是变色鸢尾,label为2的是维吉尼亚鸢尾。
由于感知机的线性局限性,他只能做二分类任务。
所以现在我们对数据集进行数据预处理,把label为2的维吉尼亚鸢尾的数据去掉,变成一个识别图片是山鸢尾还是变色鸢尾的二分类任务。
三、数据预处理与特征选择
数据预处理特别简单,因为数据集的数据是顺序存放的,前50条是label为0的山鸢尾,中间50条是label为1的变色鸢尾,所以我们直接取前100条就好了。
我们在选取之前先对特征进行选择,这里我们只选萼片组['sepal length', 'sepal width']作为特征,剩下两个花瓣组['petal lenght', 'petal width']我在我们的仓库代码里留了空,可以当成作业做一做,确保自己已经掌握牢固。先看下萼片组['sepal length', 'sepal width']和label的相关性:
# 萼片组['sepal length','sepal width']特征分布查看
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
可以看到sepal length大概分布在4~7之间,sepal width大概分布在2~5之间。

四、进入正题-用感知器完成二分类
1.准备训练数据
我们先把萼片组特征['sepal length', 'sepal width']和前100条只包含label=0和label=1的数据取出来:
# 取前100行,第0、1、-1列数据为训练集
data = np.array(df.iloc[:100, [0, 1, -1]])
X, y = data[:,:-1], data[:,-1]
2.手写模型训练
如果你忘了感知机,请看我们的上一篇文章,这里直接贴上代码:
class Perceptron(object):
def __init__(self, input_feature_num, activation=None):
self.activation = activation if activation else self.sign
self.w = [0.0] * input_feature_num
self.b = 0.0
def sign(self, z):
# 阶跃激活函数:
# sign(z) = 1 if z > 0
# sign(z) = 0 otherwise
return int(z>0)
def predict(self, x):
# 预测输出函数
# y_hat = f(wx + b)
return self.activation(
np.dot(self.w, x) + self.b)
def fit(self, x_train, y_train, iteration=10, learning_rate=0.1):
# 训练函数
for _ in range(iteration):
for x, y in zip(x_train, y_train):
y_hat = self.predict(x)
self._update_weights(x, y, y_hat, learning_rate)
print(self)
def _update_weights(self, x, y, y_hat, learning_rate):
# 权重更新, 对照公式查看
delta = y - y_hat
self.w = np.add(self.w,
np.multiply(learning_rate * delta, x))
self.b += learning_rate * delta
def __str__(self):
return 'weights: {}\tbias: {}'.format(self.w, self.b)
权重更新是一种叫梯度下降的方法,我们还没有介绍,现在您只需要知道规则是这样就行了:
KaTeX parse error: No such environment: equation at position 8: \begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲ \begin{aligned…
其中 ,y为正确的输出, 的结果。
我们先迭代训练100次看看:
perceptron = Perceptron(input_feature_num=X.shape[1])
perceptron.fit(X, y, iteration=100, learning_rate=0.1)
结果如下:
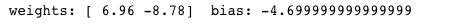
此时花萼长度的特征权重是0.069,花萼宽度特征权重是-8.78,以及一个偏置项-4.70。那么这个结果好不好呢?我们查看一下就知道。
3.结果查看
作图代码如下:
x_points = np.linspace(4, 7, 10)
y_ = -(perceptron.w[0]*x_points + perceptron.b)/perceptron.w[1]
plt.plot(x_points, y_)
plt.plot(data[:50, 0], data[:50, 1], 'bo', color='blue', label='0')
plt.plot(data[50:100, 0], data[50:100, 1], 'bo', color='orange', label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
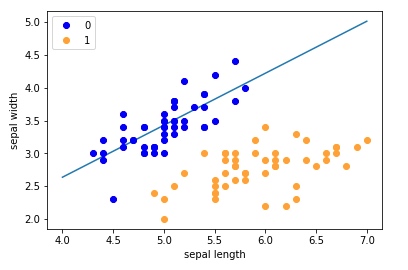
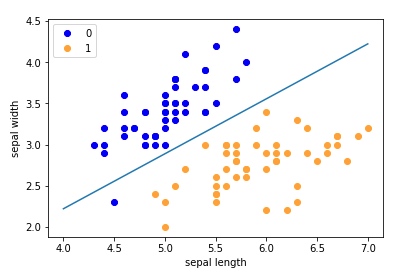
可以看到我们的感知器的效果特别差,有非常多的label=0的数据会被错分到label=1去,这种训练不充分的结果就叫欠拟合。现在让我们把迭代次数加到300去看看:
perceptron = Perceptron(input_feature_num=X.shape[1])
perceptron.fit(X, y, iteration=300, learning_rate=0.1)
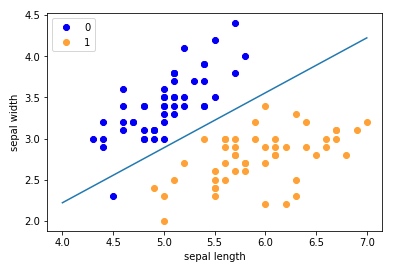
Nice,这差不多就是我们想要的结果了。到这本文差不多就结束了,可以去做作业确保自己掌握牢固了。可能有些同学对于调包有一定需求,sklearn也有封装感知机,我们额外进行个对比。
3.与sklearn结果对比
警告:本文不提倡做掉包侠,所以sklearn不是我们学习的重点,请刹住方向及时回归主线。
from sklearn.linear_model import Perceptron
clf = Perceptron(fit_intercept=False, max_iter=1000, shuffle=False)
clf.fit(X, y)
五、作业-用petal组特征完成二分类(重点)
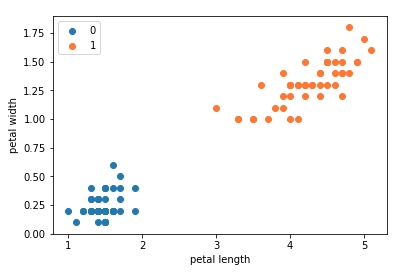
本文用了花萼(sepal)长度和宽度作为特征完成二分类任务,我们留下的作业是用花瓣(petal)长度和宽度作为特征完成二分类任务。
花瓣组特征与label的相关性如下:
# 花瓣组['petal length','petal width']特征分布查看
plt.scatter(df[:50]['petal length'], df[:50]['petal width'], label='0')
plt.scatter(df[50:100]['petal length'], df[50:100]['petal width'], label='1')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend()
纸上得来终觉浅,可能现在您依然看得迷迷糊糊,但是我相信您完成这部分作业肯定就能完全掌握感知机。
接下来您可以参考我们的代码训练一个鸢尾花感知器了。
代码都在github仓库里,就差喂你嘴里了,快来学习吧!
文集所有代码地址:https://github.com/AIGroup-Z/deep-neural-network
如果有任何问题,你不是一个人。可以在公众号首页找到我们的组队学习群。

