一 最难的一件事
要成为大牛,其实不难,只需要做一件事 -- 学习;然而其实也很难,因为必须做到一件事 -- 坚持学习。无关智商,无关信仰,能否坚持到底,至关重要。
白天要上班,往往要加班,还要积极完成小孩的课业与辅导,处理好家务琐事,只能晚上孤独的学习,要系统的入门,独学而无友,有问题只能求诸于己,咬牙死磕。晚上别人在睡前电视,周末别人在惬意时光,都要苦苦战斗,如切如磋,如琢如磨。100要学AI的IT,真正行动的也许不过1/5,坚持一个月的可能已不足10人,能始终坚持到入门,找到感觉的,也就2-3个人了吧,能有人能成为大牛,是小概率事件了。
因此,咬牙坚持,是最好的良药,也是最难的一件事。
要做到坚持,也要讲方法,不能太苦,要快乐的坚持,至少要痛并快乐着。因此学习节奏也就是时间安排非常重要。
建议的入门时间安排:1)每周一、三、五,每晚花两个小时学习、看视频 2)周六、周日每天四小时左右。 3)坚持三个月以上。 4)平时学习侧重看视频、书籍;周末侧重完成课程附带的编程作业、及思考归纳。
关于思考与归纳的几个层次举例:
1)知道理解人工智能这个概念(几乎所有人);
2)知道“机器学习”这个概念(有一部分人);
3)清楚描述“深度学习”、“机器学习”和“神经网络”的关系(一小部分人);
4)能够正确说明“卷积”、“池化”、“梯度下降”这些名词的正确含义与计算/实现的方法(很少一部分人);
5)能清楚地理解损失函数和反向传播的数学表达(非常少的人);
6)能够阐述网络参数的一个修改(比如把卷积核改小)对precision/recall会产生什么影响(极少极少的人);
7)准确描述上述影响到底是什么原理(几乎没有人)。
二 数学是最大的拦路虎吗
一) 别人的经验
作为“尚未入门的广大学友”、“不明真相的吃瓜群众”,从哪里入手好呢? 线性代数?概率论?那是最糟糕的选择!它们只会让你入门之前就彻底丧失信心,其漫长而陡峭的学习曲线还会让你误以为这是一个无法进入的领域。事实上,只有已经入门并并深入前进(比如能够正确并完整的讲解“卷积”,“池化”,“LSTM”这些词的正确含义、原理和计算/实现方法)之后,你才真正需要更多的数学知识。入门学习中用到的数学知识,只有以下三点:
1. 懂得矩阵运算的基本计算方法,能够手动计算[3×4]×[4×3]的矩阵,并明白为什么会得到一个[3×3]的矩阵。
2. 懂得导数的基本含义,明白为什么可以利用导数来计算梯度,并实现迭代优化。
3. 能够计算基本的先验及后验概率。
二) 一些理解
AI 的学习有多方面的诉求和阶段,不同的阶段对数学有不同的需求,不同的方向也有不同的需要。除前面所说的,未入门阶段其实不需要太多专业数学知识,另外,做研究和做工程、做应用也是两个不同的难度级别。
殊途同归,估计到高深处都是一样的了。入门时其实不需刻意。
三 入门学习路线
一) 零基础学习入门课程: 吴恩达的机器学习课程开始: Machine Learning - Stanford University | Coursera
吴恩达的英语又慢又清晰,课程字幕的翻译又到位,课程设置与课中测验及时而又合理,重点清晰、作业方便,再加上吴恩达教授深入浅出的讲解,讲解过程中不时的鼓励和调侃,都能让你更为积极地投入到机器学习的学习之中,让你扎实而快速地掌握机器学习的必备基础知识。
这门在线课程,相当于斯坦福大学CS229的简化版,涵盖内容包括机器学习最基础的知识、概念及其实现,以及最常用的算法(例如PCA、SVM)和模型(全连接神经网络)。学习这门课程,重要的是基础的概念与实现。作为一名具备编程基础的开发人员,在这个阶段要将自身理论同实践相结合的优势发挥出来,充分利用它所提供的编程作业,尽可能多地实践,从理论和代码两个角度去理解课程中的知识点。
二) 夯实基础
回头去看一遍CS229,将传统算法整体熟悉一遍,尽可能把所有的基本概念都掌握扎实。
三) 选择主攻领域并学习
任何人不可能选择计算机视觉(CV)、自然语言处理(NLP)以及其他领域等全部领域学习。在每个领域下,都有大量的研究者在投入精力钻研,发表论文和成果。可选择一到两个方向作为主攻,跟上学术界主流的进展。 在完成了相应领域的学习后,下一步要做的就是尝试阅读最新的经典论文并试图实现。
四) 编程语言与框架
1. 入门编程语言 python
2. 框架
1) pytorch
2) tensorflow
五) 实战常用数据集
1. mnist 手写数字库
每条数据是固定的784个字节,由28x28个灰度像素组成。体积小(10M左右)、数据多(6万张训练图片)、适用范围广(NN/CNN/SVM/KNN都可以拿来跑跑)而闻名天下,其地位相当于机器学习界的Hello World。在LeCun的MNIST官方网站上(yann.lecun.com/exdb/mnist/),还贴有各种模型跑这个数据集的最好成绩,当前的最好得分是CNN的,约为99.7%。由于该数据集非常之小,所以即便是在CPU上,也可以几秒钟就跑完NN的训练,或是几分钟跑完一个简单的CNN模型。
2. CIFAR 图形库
Tensorflow给出了CIFAR的例程: https://www.tensorflow.org/tutorials/deep_cnn 并附有代码:
https://github.com/tensorflow/models/tree/fb96b71aec356e054678978875d6007ccc068e7a/tutorials/image/cifar10
四 入门学习经验之谈
1. 最好和一个真正能做出东西的团队或跟随真正的牛人一起学习相比,比自己一个人速度要快十倍都不止。深刻理解业务,选择合适的模型算法,找到实际应用场景,实现它,实现它,实现它。
2. 不要太迷信论文,很多写论文纯粹在编故事(好论文除外),一定要复现论文或者尝试自己做出一些东西。DL\ML其实是一门实践性的学科,只有通过实验才能把握到其中的细节与真谛。虽说也是在写程序,但是DL的程序基本上无法直观地debug,所以非得自己去复现一下,实践一下,用performance来说话,才知道有没有出错。
3. 不能浅尝辄止,不要求快,没有捷径。自己首先有个心理预期,数学好的入门也得一年半载的,数学需要补基础的估计要1-2年。可以去上培训班,交点钱,但也就跟机器学习混个脸熟。想入门还得花时间慢慢磨,真的没捷径,真的没捷径,真的没捷径!。
4. 不要太迷信复杂的东西和新技术,以为新东西肯定就效果爆棚。其实都是不存在的。永远不要迷信某个特定的模型,要摸索理解各种不同模型的特性。
5. 模型不求多,精通几个常见的,把机器学习的套路摸透就可以了。比如LR,朴素贝叶斯,决策树,基于SVD相关的简单模型,如推荐系统等。把机器学习的套路摸透什么意思呢?比如LR为什么用logloss,而不是平方损失?为什么logloss 是凸函数,而平方的不是?优化算法啥时候用一阶mini-batch sgd,啥时候用二阶方法,为什么?这还只是说了损失函数与优化算法,还有模型结构,模型的效果评估指标,如何利用欠拟合/过拟合来分析指导优化模型等等。因为简单的模型容易理解,有时数学上的证明也是可行的。这样,以它们为例子更容易理解机器学习这套东西,建立自己的直觉,自己的直觉,自己的直觉,几何的或物理的。
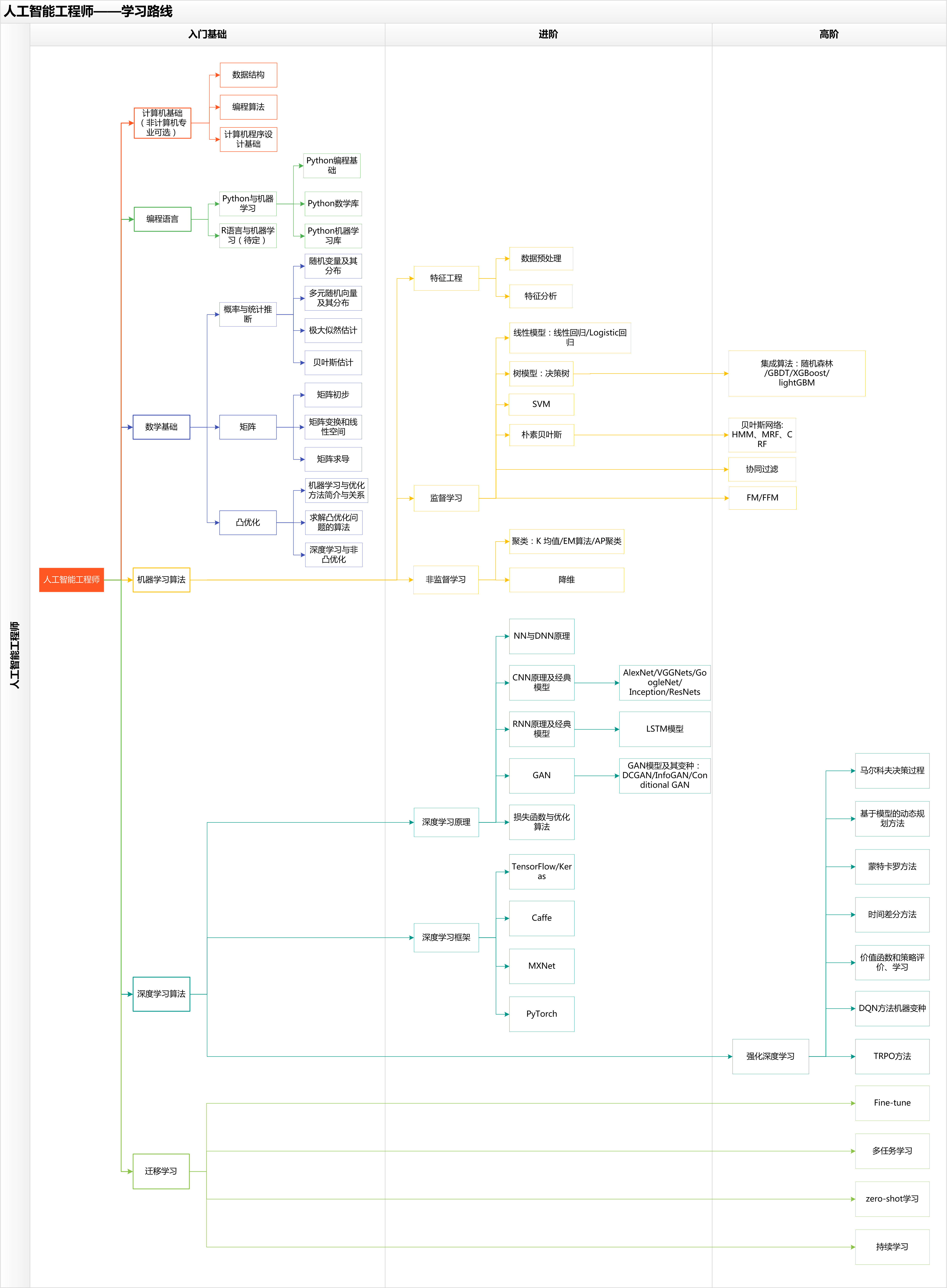
五 人工智能工程师学习图谱