1. 概述
统计语言模型的目标:学习序列中单词的联合概率分布。
NNLM神经语言模型参考论文A Neural Probabilistic Language Model。
语言模型的一大问题是维数灾难,例如,如果想对自然语言中单词表大小为100000的10个相连的单词建立联合分布模型,将会有
个自由参数。为解决这个问题,该篇论文采用神经语言模型,且该文采用矩阵的形式,其中小写的v表示列向量,
表示其转置。
表示矩阵的第j行。
2. 神经语言模型
统计语言模型中一个单词的概率可以表示成在前面单词出现的条件下,后一个单词出现的概率(条件概率):
其中
表示第t个单词,
表示第i个单词到第j个单词。那么一个句子出现的概率为:
n-gram模型即利用上述公式,但假设当前词出现的概率仅与前n个词有关(贝叶斯则人次单词间是相互独立的)。但n-gram仍有一些缺点:参数众多(维度灾难);没有考虑词与词之间的相似性(比如The cat is walking in the bedroom与The dog is walking in the bedroom应该具有相似的概率,但是预料中cat出现的频次比dog多,则The cat is walking in the bedroom概率更大)。
为解决上述问题,该论文提出神经语言模型。其大致思想可以概述为以下三点:
- 为词表中的每个词分配一个分布式的词特征向量
- 使用序列中单词的特征向量表示序列的联合概率分布
- 同时训练词的特征向量和神经网络中的参数(这一思想被很多词向量的语言模型使用)
下面就具体看一下神经网络语言模型究竟怎么设计的。
2.1 神经语言模型基本理论
上述提到一个句子出现的概率为
将其转化成神经网络语言模型可以表示成:
。其中
即为神经语言模型。针对其中一个单词的概率就可表示为如下:
,论文中的公式与此符号不同,但本质一样,其为:
约束条件为:
|V|为词表的大小。第二个约束条件为什么是这样,一会讲到神经网络的结构就可以理解了。
统计语言模型的概率是得到一个句子出现的概率,但是前提是知道句子中每个单词出现的条件概率。那么,一个单词的条件概率怎么计算呢,就用到该论文中的神经语言模型,具体结构如下图所示:
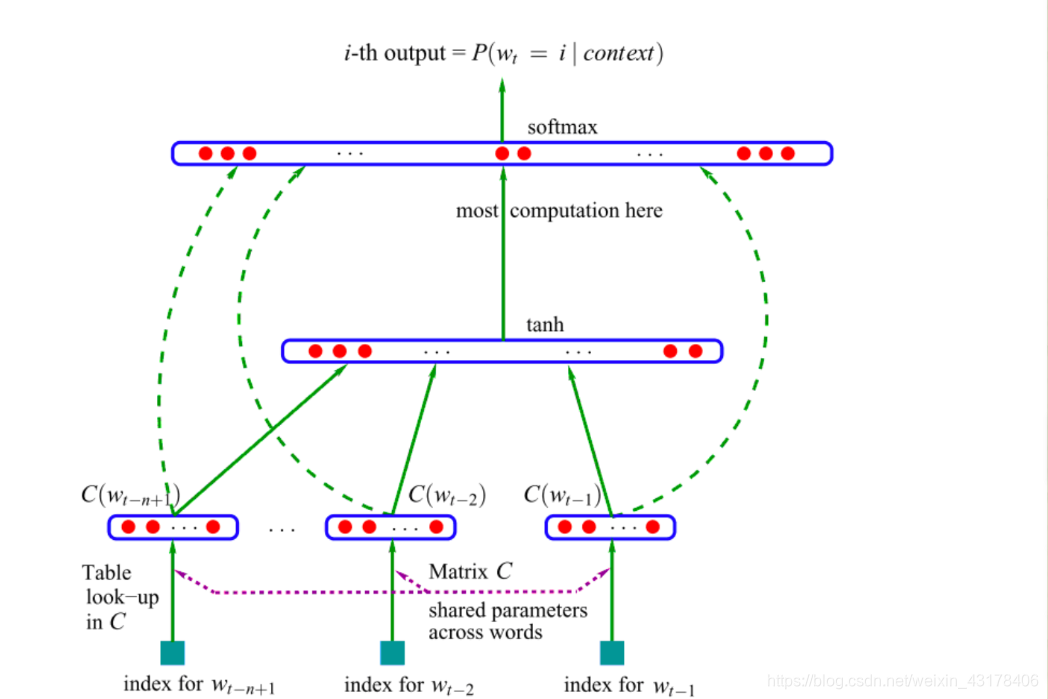
首先明确下,这张图同以前的DNN图一样,展示的是一个样本的结构,针对一个样本进行如下解释:
接下来,针对该图,我们一层层讲解。首先给定一个模型,需要知道输入是什么。从图中可以看出该结构的输入为每个词的index。假设词典V中有|V|个单词,那么可以为每个单词设置一个索引。而每个单词都可以用one-hot的形式表示,其中为1的那一维就是该单词的index。比如(1,0,0,0,0,…,0)表示该单词是词典中的第一个。假设现在想要得到"I like playing games"这句话的概率,而当前的任务是预测games这个单词的条件概率。又假如词典V中仅有10个词,而I是第2个,like是第三个,playing是第1个,very是第8个,那么我们的输入为
0,1,0,0,0,0,0,0,0,0,0 ---->图中的index for
这里为t-n+1
0,0,1,0,0,0,0,0,0,0,0 ---->图中的index for
1,0,0,0,0,0,0,0,0,0,0 ---->图中的index for
此外,在我们的模型中还有一个初始化的C,C的行数为|V|,列数为m。C的每一行是一个单词的向量,维度为m。也就是说C是词典V中所有单词的向量表示。并且C的行数和单词的index是对应的,比如like是词典中的第三个,那么他就在C中的第三行。将上述的one-hot构成的输入与C相乘,然后再拉直(成为向量),就可以得到我们真正的输入了。可以看到相乘后的结果就是该单词对应的初始化向量。(因为one-hot表示,只有一个数为1,其余都为0,因此取出了该单词在C中对应的那一行)。这里注意一下,与C相乘后得到的输入也即我们的词向量,后向传播时也要进行更新。到现在,我们得到了图中的
。
有了模型的输入,下面就好办了,首先是输入
与参数相乘,再套一个tanh,然后下一层再乘以相应参数,为了得到输出,套一个softmax。softmax里面的数据是|V|维的,即我们想要通过神经网络得到I like playing出现的情况下,词典中所有单词出现的概率。此时就应该明白为什么有第二个约束条件了。论文中的具体公式表示如下:
其中
是每个输出词i未归一化log概率,计算如下:
这里我对论文中的参数顺序做了一个调整,其中d表示第一个隐藏层的偏置项,x即为刚才
拉直的向量,H为第一个隐藏层的权重参数。U为第二个隐藏层的权重参数,b为第二个隐藏层的偏置项。这里比较奇怪的是Wx,论文中是这样说的:当不需要从字特征到输出的直接连接时,将矩阵W设置为0。所以当W=0时,就是我们平时理解的全连接神经网络,加上Wx只是为了让输入与中间输出建立关系。(对于所有样本,可以改写成对应的矩阵形式)
有了模型的架构,还有一个问题是如何优化,即模型的损失函数是什么?论文中给出损失函数如下:
其中,
为正则化项,且与偏置项无关。可以看到,论文中的损失函数,是针对整个句子的(对上述一句话的概率求log),也即一句话联合概率的log值。
如果采用随机梯度算法的话,梯度更新的法则为:

从更新法则可以看出,这是针对一个单词的条件概率,而不是整个句子的,也就是所有样本的。
到此,论文的主体部分就介绍差不多了。但是仍然存在一些疑问。
2.2 疑问
第一个疑问:对于单个词的条件概率损失函数究竟是不是softmax的交叉熵损失函数呢。论文中一开始说目标函数是整个句子的,后来更新权重参数用的是一个单词的,但是形式还不同于交叉熵。看到有一个github代码是这样写的:loss = -tf.reduce_mean(tf.reduce_sum(tf.log(outputs) * one_hot_targets, 1))。也就是说该作者认为是论文那种形式,输出后乘以一个one-hot表示(取出目标词的概率)
第二个疑问:假如"I like playing games"我就想预测I的概率,此时输入是什么呢?有一个想法,类似于n-gram前面,每个句子句首都有一个<s>,所以是不是<s>对应的向量呢?
第三个疑问:神经网络模型中每个样本的输入维度应该一样,那么给定一个句子,处理成神经语言模型想要的输入时,每次依赖的词的个数不一样,如何处理呢。比如’'I like you",第一个样本输入是I的向量,第二个样本是I like的向量,那么如何处理维度不一致呢?
由于没有找到官方的源代码,这些疑问只能暂时放下了。希望以后能够解决。
2.3 疑问更新
参考github的一个实现:对于疑问1,该作者采用的是论文形式:loss = -tf.reduce_mean(tf.reduce_sum(tf.log(outputs) * one_hot_targets, 1))
针对疑问2和3:该作者固定每个样本的单词个数,因此在最开始构造时会在前面填充seq_lenth(句子单词的个数)个0(0对应词汇表里的),在最后面填充seq_lenth个2(2对应词汇表里的),1为词汇表里的UNK。
个人认为该作者的代码比较符合论文原著。现附上该作者代码的github链接:
https://github.com/FuYanzhe2/NNLM
代码共有三个py文件,第一个为数据处理,代码如下:
#encoding:utf-8
#import sys
#reload(sys)
#sys.setdefaultencoding('utf8')
import os
import codecs
import collections
from six.moves import cPickle
import numpy as np
import re
import itertools
class TextLoader():
def __init__(self, data_dir, batch_size, seq_length, mini_frq=3):
self.data_dir = data_dir
self.batch_size = batch_size
self.seq_length = seq_length
self.mini_frq = mini_frq
input_file = os.path.join(data_dir, "input.zh.txt")
vocab_file = os.path.join(data_dir, "vocab.zh.pkl")
self.preprocess(input_file, vocab_file)
self.create_batches()
self.reset_batch_pointer()
def build_vocab(self, sentences): # sentences为列表,每个元素为一句话中词语构成的小列表
word_counts = collections.Counter() # 类似于创建一个空字典
if not isinstance(sentences, list):
sentences = [sentences]
for sent in sentences:
word_counts.update(sent) # 统计每个词出现的次数
vocabulary_inv = ['<START>', '<UNK>', '<END>'] + \
[x[0] for x in word_counts.most_common() if x[1] >= self.mini_frq]
# 词表:由start、unk、end、以及词频3次以上的词构成
vocabulary = {x: i for i, x in enumerate(vocabulary_inv)} # 词表字典:按照词频从高到低排序
return [vocabulary, vocabulary_inv]
def preprocess(self, input_file, vocab_file):
with codecs.open(input_file, 'r', 'utf-8') as f: # input.zh文件
lines = f.readlines()
if lines[0][:1] == codecs.BOM_UTF8:
lines[0] = lines[0][1:]
lines = [line.strip().split() for line in lines]
self.vocab, self.words = self.build_vocab(lines) # 列表套列表,每个小列表是一句话的分词结果
self.vocab_size = len(self.words) # 单词的个数
#print 'word num: ', self.vocab_size
with open(vocab_file, 'wb') as f: # 需要写入的文件
cPickle.dump(self.words, f) # 将单词的列表写入文件
raw_data = [[0] * self.seq_length +
[self.vocab.get(w, 1) for w in line] +
[2] * self.seq_length for line in lines]
self.raw_data = raw_data
# 列表套列表,大列表共有句子总数个元素,每个小元素由seq_length个0+一句话中每个词的index+seq_length个2构成
def create_batches(self):
xdata, ydata = list(), list()
for row in self.raw_data:
for ind in range(self.seq_length, len(row)):
xdata.append(row[ind-self.seq_length:ind])# xdata为raw_data的第0-seq_lenth个
ydata.append([row[ind]]) # ydata即为xdata后一个单词
self.num_batches = int(len(xdata) / self.batch_size)
if self.num_batches == 0:
assert False, "Not enough data. Make seq_length and batch_size small."
xdata = np.array(xdata[:self.num_batches * self.batch_size])
ydata = np.array(ydata[:self.num_batches * self.batch_size])
self.x_batches = np.split(xdata, self.num_batches, 0)
self.y_batches = np.split(ydata, self.num_batches, 0)
def next_batch(self):
x, y = self.x_batches[self.pointer], self.y_batches[self.pointer]
self.pointer += 1
return x, y
def reset_batch_pointer(self):
self.pointer = 0
第二个为NNLM的框架文件,代码如下:
import argparse
import math
import time
import numpy as np
import tensorflow as tf
from input_data import TextLoader
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--data_dir', type=str, default='data/',
help='data directory containing input.txt')
parser.add_argument('--batch_size', type=int, default=120,
help='minibatch size')
parser.add_argument('--win_size', type=int, default=5,
help='context sequence length')
parser.add_argument('--hidden_num', type=int, default=64,
help='number of hidden layers')
parser.add_argument('--word_dim', type=int, default=50,
help='number of word embedding')
parser.add_argument('--num_epochs', type=int, default=10,
help='number of epochs')
parser.add_argument('--grad_clip', type=float, default=10.,
help='clip gradients at this value')
args = parser.parse_args()
data_loader = TextLoader(args.data_dir, args.batch_size, args.win_size)
args.vocab_size = data_loader.vocab_size
graph = tf.Graph()
with graph.as_default():
input_data = tf.placeholder(tf.int64, [args.batch_size, args.win_size])
targets = tf.placeholder(tf.int64, [args.batch_size, 1])
with tf.variable_scope('nnlm' + 'embedding'):
embeddings = tf.Variable(tf.random_uniform([args.vocab_size, args.word_dim], -1.0, 1.0))
embeddings = tf.nn.l2_normalize(embeddings, 1)
with tf.variable_scope('nnlm' + 'weight'):
weight_h = tf.Variable(tf.truncated_normal([args.win_size * args.word_dim, args.hidden_num],
stddev=1.0 / math.sqrt(args.hidden_num)))
softmax_w = tf.Variable(tf.truncated_normal([args.win_size * args.word_dim, args.vocab_size],
stddev=1.0 / math.sqrt(args.win_size * args.word_dim)))
softmax_u = tf.Variable(tf.truncated_normal([args.hidden_num, args.vocab_size],
stddev=1.0 / math.sqrt(args.hidden_num)))
b_1 = tf.Variable(tf.random_normal([args.hidden_num]))
b_2 = tf.Variable(tf.random_normal([args.vocab_size]))
def infer_output(input_data):
"""
hidden = tanh(x * H + b_1)
output = softmax(x * W + hidden * U + b_2)
"""
input_data_emb = tf.nn.embedding_lookup(embeddings, input_data)
input_data_emb = tf.reshape(input_data_emb, [-1, args.win_size * args.word_dim])
hidden = tf.tanh(tf.matmul(input_data_emb, weight_h)) + b_1
hidden_output = tf.matmul(hidden, softmax_u) + tf.matmul(input_data_emb, softmax_w) + b_2
output = tf.nn.softmax(hidden_output)
return output
outputs = infer_output(input_data)
one_hot_targets = tf.one_hot(tf.squeeze(targets), args.vocab_size, 1.0, 0.0)
loss = -tf.reduce_mean(tf.reduce_sum(tf.log(outputs) * one_hot_targets, 1))
# Clip grad.
optimizer = tf.train.AdagradOptimizer(0.1)
gvs = optimizer.compute_gradients(loss)
capped_gvs = [(tf.clip_by_value(grad, -args.grad_clip, args.grad_clip), var) for grad, var in gvs]
optimizer = optimizer.apply_gradients(capped_gvs)
embeddings_norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / embeddings_norm
with tf.Session(graph=graph) as sess:
tf.global_variables_initializer().run()
for e in range(args.num_epochs):
data_loader.reset_batch_pointer()
for b in range(data_loader.num_batches):
start = time.time()
x, y = data_loader.next_batch()
feed = {input_data: x, targets: y}
train_loss, _ = sess.run([loss, optimizer], feed)
end = time.time()
print("{}/{} (epoch {}), train_loss = {:.3f}, time/batch = {:.3f}".format(
b, data_loader.num_batches,
e, train_loss, end - start))
np.save('nnlm_word_embeddings.zh', normalized_embeddings.eval())
if __name__ == '__main__':
main()
第三个为测试文件,代码如下:
import pickle
import numpy as np
import os
import math
data_dir = "./data"
vocab_file = os.path.join(data_dir, "vocab.zh.pkl")
with open(vocab_file, 'rb') as f:
vocab = pickle.load(f, encoding='bytes')
word_emb = np.load('nnlm_word_embeddings.zh.npy')
#vocab = {v : k for k, v in vocab.items()}
word1_id = vocab["中国"]
word2_id = vocab["美国"]
word1_emb = word_emb[word1_id]
word2_emb = word_emb[word2_id]
def cosin_distance(vector1, vector2):
dot_product = 0.0
normA = 0.0
normB = 0.0
for a, b in zip(vector1, vector2):
dot_product += a * b
normA += a ** 2
normB += b ** 2
if normA == 0.0 or normB == 0.0:
return None
else:
return dot_product / ((normA * normB) ** 0.5)
print(cosin_distance(word1_emb,word2_emb))
总结模型的输入和标签:

