上篇文章:mysql知识盘点【壹】_SQL优化
本文主要基于Mysql数据库的InnoDB引擎介绍下其索引的实现。
索引结构
在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能,当进行范围查找时只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率。
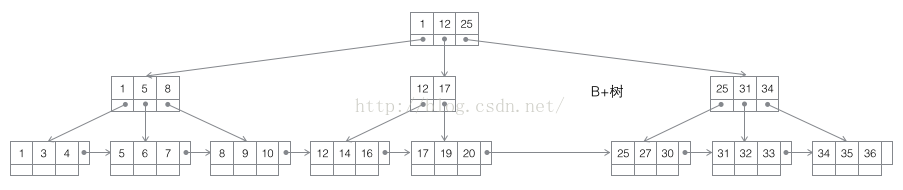
一般来说,由于索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。为了提高查询性能,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。
这样做的理论依据是计算机科学的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。
页(page)是InnoDB存储引擎管理数据库的最小磁盘单位,InnoDB中的页大小为16KB,且不可以更改。上面说的预读的长度一般为页的整倍数。
聚簇索引
在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引,称为聚簇索引。
因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键。如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
表中的聚簇索引(clustered index)就是一级索引。除此之外,表上的其他非聚簇索引都是二级索引,又叫辅助索引(secondary indexes)。
那么InnoDB与MyISAM在索引实现上有何区别呢?
1.InnoDB的数据文件本身就是索引文件,而MyISAM为另做存储;
2.InnoDB的辅助索引data域存储相应记录主键的值,而MyISAM存储的是地址;
索引覆盖
覆盖索引的优势,在于可以从索引中直接获取查询结果并返回,不需要回表查询。通常使用满足如下条件:
1.select查询的返回列包含在索引列中;
2.有where条件时,where条件中要包含索引列或复合索引的前导列;
3.查询结果的总字段长度可以接受;
不能使用索引的情况
1.查询条件与联合索引列顺序不匹配;
2.查询条件没有使用索引第一列;
3.前缀模糊匹配;
4.范围列后面的列无法用到索引;
5.对字段进行了函数计算;
不适合建索引
1.表记录比较少;
2.区别度比较低;