-
torch.sort(input,dim=-1,descending=False,out=None): → Tensor
将input张量在指定维按升序排序元素。
如果dim未指定,则默认为最后一个维度。
如果descending为True,则按降序排序。
返回一个命名元组(values,indices),其中values为值排好序的张量,indices为values对应的索引张量。
参数
input(Tensor): 输入张量。
dim(int,可选): 排序的维度。
descending(bool,可选): 控制排序方式。
out(tuple,可选): 可被选作做输出缓冲区的输出元组(Tensor,LongTensor)。
Example:

-
torch.topk(input,k,dim=None,largest=True,sorted=True,out=None): → (Tensor,LongTensor)
返回input在给定dim维的前k大的元素。
如果dim未给,则默认为input的最后维。
如果largest为False,则返回第k小的元素。
返回一个命名元组(values,indices),其中values为值排好序的张量,indices为values对应的索引张量。
如果bool值sorted为True,则返回的张量也会被排序。
参数
input(Tensor): 输入张量。
k(int): 返回前k个值。
dim(int,可选): 排序的维度。
largest(bool,可选): 决定返回的是最大值还是最小值。
sorted(bool,可选): 决定返回的张量是否排序。
out(tuple,可选): 可被选作做输出缓冲区的输出元组(Tensor,LongTensor)。
Example:

Spectral Ops
-
torch.fft(input,signal_ndim,normalized=False): → Tensor
该函数用来计算复到复(complex-to-complex)的离散傅里叶变换。忽略了批维度(batch dimensions),它计算以下的表达式:
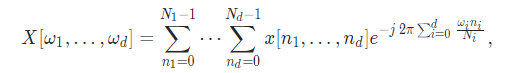
其中d = signal_ndim为信号的维度数,Ni为第i信号维的大小。该方法支持1D,2D和3D的复到复的,由signal_ndim指示的变换。输入必须是最后一维大小为2——表示复数的实部和虚部,且拥有可选的任意数量的前导批维度的,至少signal_ndim+1维的张量。如果normalized被设置为True,则通过将结果除以
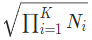
来进行规范化。返回形状与input相同的且同时具有实部和虚部的张量。
该函数的逆函数为ifft()。
Note:
对于CUDA张量,cuFFT计划使用LRU高速缓存来加速在有着相同配置和几何的张量上重复运行的FFT方法。见 https://blog.csdn.net/JachinMa/article/details/94026347 以了解更多操作和控制高速缓存的细节。Warning:
对CPU张量来说,本方法目前只适用于MKL。使用torch.backends.mkl.is_available()来检查MKL是否安装。参数
input(Tensor): 至少有signal_ndim+1维的输入张量。
signal_ndim(int): 每个信号的维度数。signal_ndim可以是1,2或3.
normalized(bool,可选): 决定是否返回g规范化的结果。默认为False。
Example:

-
ifft(input,signal_ndim,normalized=False): → Tensor
该函数用来计算复到复(complex-to-complex)的逆离散傅里叶变换。忽略了批维度(batch dimensions),它计算以下的表达式:
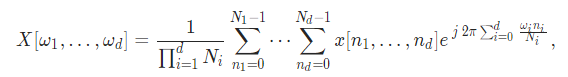
其中d = signal_ndim为信号的维度数,Ni为第i信号维的大小。该参数的规格基本与fft()相同。然而,如果normalized被设为True,该函数返回结果与
的乘积来进行g规范化。因此,要反转fft(),应为fft()设置相同的规范化参数。返回形状与input相同的且同时具有实部和虚部的张量。
该函数的逆函数为fft()。
Note:
对于CUDA张量,cuFFT计划使用LRU高速缓存来加速在有着相同配置和几何的张量上重复运行的FFT方法。见 https://blog.csdn.net/JachinMa/article/details/94026347 以了解更多操作和控制高速缓存的细节。Warning:
对CPU张量来说,本方法目前只适用于MKL。使用torch.backends.mkl.is_available()来检查MKL是否安装。参数
input(Tensor): 至少有signal_ndim+1维的输入张量。
signal_ndim(int): 每个信号的维度数。signal_ndim可以是1,2或3.
normalized(bool,可选): 决定是否返回g规范化的结果。默认为False。
Example:

-
torch.rfft(input,signal_ndim,normalized=False,onesided=True): → Tensor
该函数用来计算实到复(real-to-complex)的离散傅里叶变换。它在数学上和fft()等效,仅在输入和输出的格式上有差异。
该方法支持1D,2D和3D的复到复的,由signal_ndim指示的变换。输入必须是最后一维大小为2——表示复数的实部和虚部,且拥有可选的任意数量的前导批维度的,至少signal_ndim+1维的张量。如果normalized被设置为True,则通过将结果除以
来进行规范化,其中Ni为第i信号维的大小。实对复傅里叶变换结果遵循共轭对称:
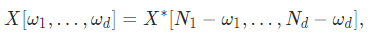
其中×为共轭操作符,d = signal_ndim。onesided控制是否避免输出结果的冗余。如果设为True(默认值),输出将不会是形状为(,2)的完整的复结果——其中×为input的形状,取而代之的,是最后一个维度将会是
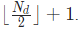
的一半。该函数的逆函数为irfft()。
Note:
对于CUDA张量,cuFFT计划使用LRU高速缓存来加速在有着相同配置和几何的张量上重复运行的FFT方法。见 https://blog.csdn.net/JachinMa/article/details/94026347 以了解更多操作和控制高速缓存的细节。Warning:
对CPU张量来说,本方法目前只适用于MKL。使用torch.backends.mkl.is_available()来检查MKL是否安装。参数
input(Tensor): 至少有signal_ndim+1维的输入张量。
signal_ndim(int): 每个信号的维度数。signal_ndim可以是1,2或3.
normalized(bool,可选): 决定是否返回g规范化的结果。默认为False。
Example:

-
torch.irfft(input,signal_ndim,normalized=False,onesided=True): → Tensor
该函数用来计算实到复(real-to-complex)的逆离散傅里叶变换。它在数学上和ifft()等效,仅在输入和输出的格式上有差异。
该方法支持1D,2D和3D的复到复的,由signal_ndim指示的变换。输入必须是最后一维大小为2——表示复数的实部和虚部,且拥有可选的任意数量的前导批维度的,至少signal_ndim+1维的张量。如果normalized被设置为True,则通过将结果除以
来进行规范化,其中Ni为第i信号维的大小。实对复傅里叶变换结果遵循共轭对称:
其中×为共轭操作符,d = signal_ndim。onesided控制是否避免输出结果的冗余。如果设为True(默认值),输出将不会是形状为(,2)的完整的复结果——其中×为input的形状,取而代之的,是最后一个维度将会是
的一半。该函数的逆函数为irfft()。
Note:
对于CUDA张量,cuFFT计划使用LRU高速缓存来加速在有着相同配置和几何的张量上重复运行的FFT方法。见 https://blog.csdn.net/JachinMa/article/details/94026347 以了解更多操作和控制高速缓存的细节。Warning:
对CPU张量来说,本方法目前只适用于MKL。使用torch.backends.mkl.is_available()来检查MKL是否安装。参数
input(Tensor): 至少有signal_ndim+1维的输入张量。
signal_ndim(int): 每个信号的维度数。signal_ndim可以是1,2或3.
normalized(bool,可选): 决定是否返回g规范化的结果。默认为False。
Example:
