DQL
1 分组查询
- group by
用于结合聚合函数,根据一个或多个列对结果集进行分组。
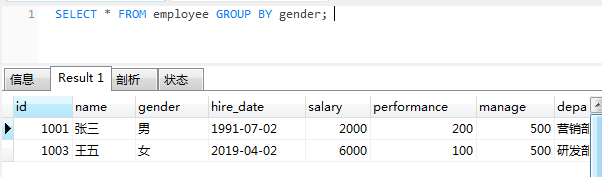
当group by单独使用时,只显示每组的第一条记录
select * from employee group by gender;
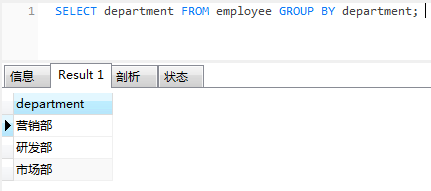
select department from employee group by department;
- 去重、分组计数
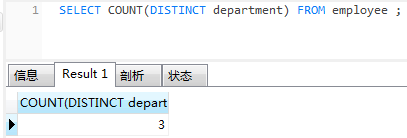
去重计数
select count(distinct department) from employee;
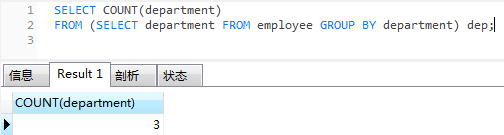
分组计数
SELECT COUNT(department)
FROM (SELECT department FROM employee GROUP BY department) dep;
或
SELECT COUNT(1)
FROM (SELECT 1 FROM employee GROUP BY department) dep;
【区分去重和分组的区别】
distinct需要将department列中的全部内容都存储在一个内存中,可以理解为一个hash结构,key为department的值,最后计算hash结构中有多少个key即可得到结果。但是需要将所有不同的值都存起来。内存消耗可能较大。
而group by的方式是先将department排序。而数据库中的group一般使用sort的方法,即数据库会先对department进行排序。而排序的基本理论是,时间复杂为nlogn,空间为1,然后只要单纯的计数就可以了。优点是空间复杂度小,缺点是要进行一次排序,执行时间会较长。
- 显示分组里面的内容
select department, group_concat(`name`)
from employee group by department;
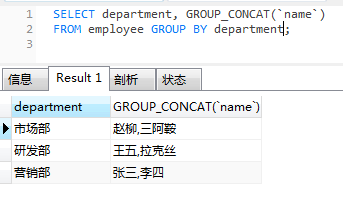
使用分组时,出现在select后面的字段要求是group by 中的字段,或者聚合函数中的字段。
-- group by中的
select name,gender
from employee group by gender,name;

-- 聚合函数中的
select department, group_concat(salary),sum(salary)
from employee group by department;
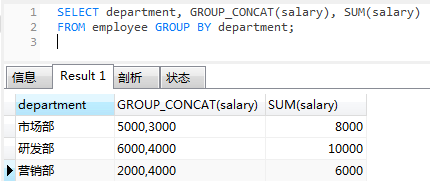
-- 查询每个部门的部门名称和每个部门的工资和
select department, sum(salary) from employee group by department;
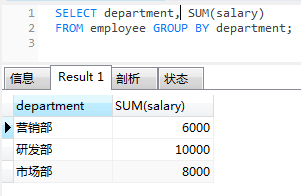
-- 查询每个部门的部门名称以及每个部门的人员和人数
select department, group_concat(`name`), count(*)
from employee group by department;

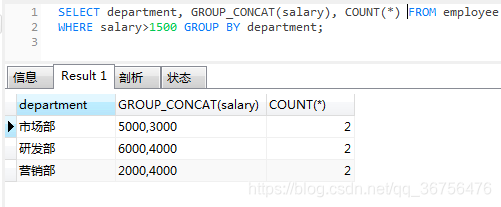
-- 查询每个部门的部门名称以及每个部门工资大于1500的人数
select department, group_concat(salary), count(*) from employee
where salary>1500 group by department;
2 带条件的分组查询 group by + having
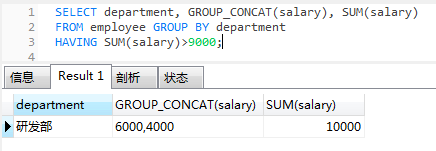
- 查询工资总和大于9000的部门名称
select department, group_concat(salary),sum(salary) from employee
group by department
having sum(salary)>9000;
【having和where的区别】
having是在分组后(即只有满足条件的数据)对数据进行过滤的,where是在分组之前进行过滤。
注意:where后不能使用聚合函数例如sum,having后可以使用
where是针对分组前记录的条件,如果某行记录没有满足where子句的条件,那么这行记录不会参加分组;而having是对分组后的数据的约束。
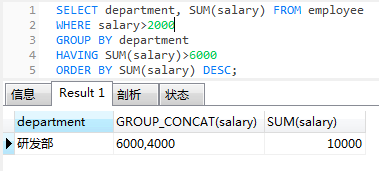
- 查询部门里所有人工资大于2000,且工资总和大于6000的部门名称以及工资和,并排序
select department,sum(salary) from employee
where salary>2000
group by department
having sum(salary)>6000
order by sum(salary) desc;
3 limit 限制查询结果返回数量
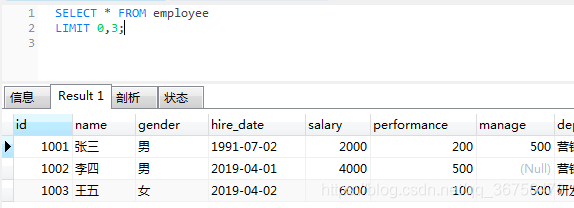
- 限制查询条数
限制从哪一行开始查,总共要查几行,角标从0开始
-- 从0开始,查3条
.. select * from employee limit 0,3;
- limit分页
【思路】
int curPage = 1; curPage为当前页
int pageSize = 3; pageSize为每页显示多少条数据
– 当前页为1第一页从0开始 (1-1)*3=0
– 当前页为2第二页从3开始 (2-1)*3=3
select * from employee limit(curPage-1)*pageSize,pageSize;
即为 select * from employee limit 0,3;
4 数据完整性
保证用户输入到数据库中的数据是正确的
在创建表时给表中添加约束
分为:实体完整性、域完整性、引用完整性
5 实体完整性
表中的一行(一条记录)代表一个实体(entity)
- 作用:标记每一行的数据不重复,行级约束
- 约束类型:主键约束、唯一约束、自动增长列
- 主键约束:每一个表中有一个主键(数据唯一,不能为null)
主键指的是一个列或多列的组合,其值能唯一地标识表中的每一行,通过它可强制表的实体完整性。主键主要是用于其他表的外键关联,以及本记录的修改与删除。
建立主键约束
-- 声明时进行约束
create table person(id bigint primary key,name varchar(50));
-- 最后进行约束
等同于create table person(id bigint, name varchar(50),primary key(id));
- 联合主键
关系数据库允许通过多个字段唯一标识记录,即两个或更多的字段都设置为主键,这种主键被称为联合主键
create table student(id bigint, sno bigint, name varchar(50), primary key(id,sno);
- 对没有添加约束的表添加约束
alter table student add constraint primary key(sno);
- 唯一约束
指定列的数据不能重复,但是可以为空值
create table student(sno bigint,name varchar(50),age int unique);
- 自动增长列
指定列的数据自动增长,即使数据删除,还是从删除的序号继续往下
create table student(
id int primary key auto_increment,
name varchar(20) unique);
6 域完整性
限制此单元格的数据正确,不对照此列的其他单元格比较,域代表当前单元格
- 域完整性约束:数据类型,非空约束not null,默认值约束default。
- 数据类型:数值类型、日期类型、字符串类型
- 非空约束、默认值约束
create table stu(
id int primary key auto_increment,
name varchar(20) unique not null,
gender char(1) default '男');
7 参照完整性
是指表与表之间的一种对应关系,通常情况下可以通过设置两表之间的主键、外键关系,或者编写两表的触发器来实现。
有对应参照完整性的两张表格,在对他们进行数据插入、更新、删除的过程中,系统都会将被修改表格与另一张对应表格进行对照,从而阻止一些不正确的数据的操作。
- 数据库的主键和外键类型一定要一致
-- score表的外键sid参照stu表的主键id
create table stu(id int primary key, name varchar(50), age int);
create table score(sid int, score int,
constraint sc_st_fk foreign key(sid) references stu(id));
-- constraint约束 foreign key(外键) references(参照)
8 表之间的关系
- 一对一
一个ID对应一个人 - 一对多关系
create table person(id int primary key auto_increment,name varchar(50);
create table car(name varchar(20),color varchar(20),pid int,
constraint c_p_fk foreign key(pid) references person(id));
- 多对多关系
create table teacher(tid int primary key, name varchar(50));
create table stu(sid int primary key, name varcahr(50));
create table tea_stu_rel(tid int, sid int);
-- 建立联系,一个表添加多个外键
alter table tea_stu_rel add constraint foreign key(tid) references teacher(tid);
alter table tea_stu_rel add constraint foreign key(sid) references stu(sid);
【为什么要拆分表】
为了避免大量冗余数据的出现
