一、创建表分区
MySql默认是支持表分区的,可以通过语句查询是否开启表分区功能:show plugins ;
![]()
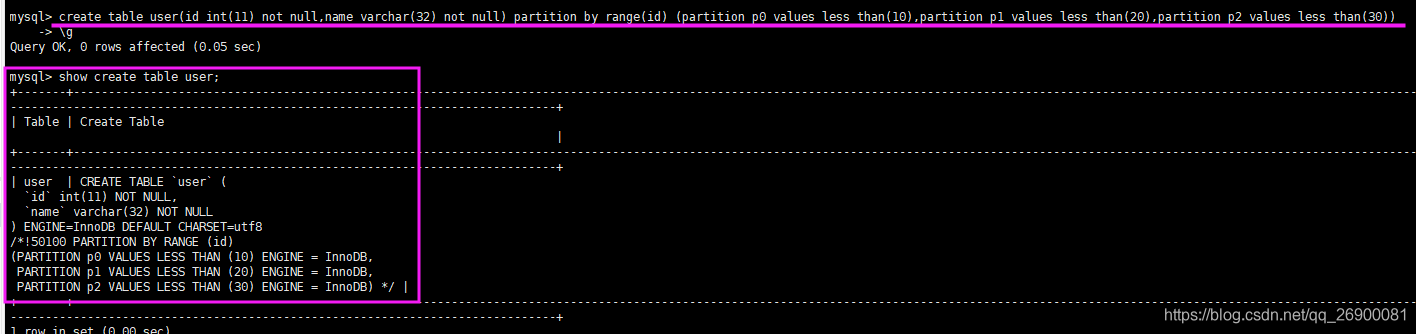
创建表分区只需要在创建表的语句后面加上分区语句就可以,例如:
create table user(id int(11) not null,name varchar(32) not null) --正常的创建语句
partition by range(id) --根据表字段id来创建分区
(
partition p0 values less than(10), --第一个分区p0,范围~-9
partition p1 values less than(20), --第二个分区p1,范围10-19
partition p2 values less than(30), --第三个分区p2,范围20-29
partition p3 values less than maxvalue --第四个分区p2,范围30-~
) --需要注意的是分区字段“id”的取值范围等于分区取值范围
数据存储文件将根据分区被拆分成多份:*.ibd , .frm文件是表格式文件:
![]()
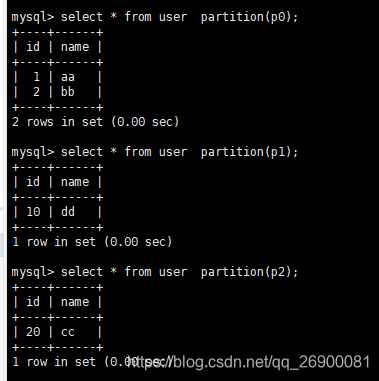
新增几条数据后查询可以看到数据已经分散在不同的分区中:
二、表分区的类型
1、RANGE表分区:范围表分区,按照一定的范围值来确定每个分区包含的数据,如上使用的就是range表分区;
partition by range(id) partition p0 values less than()
分区函数使用的字段必须是整数类型(bit, int ,tinyint,bigint等),分区的定义范围必须是连续的,且不能重叠,使用values less than()来定义分区范围,从小到大定义范围。
给分区字段赋值的时候分区字段取值范围不能超过values less than()的取值范围。使用values less than maxvalue来将未来不确定的值放到这个表分区中。
按时间类型(datetime)来做表分区可以在RANGE()中使用函数来做转换,例如:partition by range(year(create_time)),timestamp可以使用unix_timestamp('2019-11-20 00:00:00')转化。
2、LIST表分区:列表表分区,按照一个一个确定的值来确定每个分区包含的数据
partition by list(id) partition p0 values in(1,2,3)
分区字段必须是整数类型或者分区函数返回整数,取值范围通过values in()来定义。不能使用maxvalue。
create table user4(sex int(1)) partition by list(sex) (partition p0 values in(1),partition p1 values in(2));
3、HASH表分区:哈希表分区,按照一个自定义的函数返回值来确定每个分区包含的数据
partition by hash(id) partitions 4
根据hash算法来分配到分区中,以上设置四个分区,并根据id%4进行取模运算,根据余数插入到指定的分区中。
create table user7(id int) partition by hash(id) partitions 3;
4、KEY表分区:key表分区,与哈希表分区类似,只是用MySql自己的HASH函数来确定每个分区包含的数据;
partition by key() partitions 4
key()括号里面可以包含0个或多个字段(不必是整数类型,可以是普通字段),如果表中有主键或者唯一键,所引用的字段必须是主键或者主键的一部分。如果没有写字段,默认使用主键,如果表中没有主键,则使用唯一键,但唯一键必须设置为not null。
5、多字段分区(range、list):可以指定多个字段作为分区字段;以下以多字段range作为讲解:
例如:partition by range columns(id,name)
多字段分区可以使用非整数类型来作为分区字段。使用这个特性可以用来创建单字段的非整数类型的表分区。
对比方式从左到右,第一个字段值小于第一个字段分区值则放在第一个分区,等于或大于第一个字段分区值则对比第二个字段值与第一个字段分区值的大小,以此类推。
create table user6(sex varchar(10),name varchar(10),age varchar(10)) partition by range columns(sex,name,age) (partition p0 values less than('d','f','h'),partition p1 values less than('l','n','x'));
先比较sex字段,再比较name字段,最后比较age字段。使用select ('a','b')<('b','c')来验证
三、创建表分区的约束条件
1、如果表有主键(primary key)或者唯一键(unique key),分区字段必须被包含于主键和唯一键字段的交集部分。
错误的例子:

正确的例子:


三、表分区的使用
1、使用分区字段"id"做查询的时候只查询id所处的分区,否则查询所有分区:

四、表分区的主要优点
1、可以允许在一个表里存储更多的数据,突破磁盘限制和文件系统限制。
2、对于从表里删除过期的历史数据比较容易,只需要移除对应的分区。
3、对于某些查询或修改语句,可以自动将数据范围缩小到一个至几个分区上,优化语句执行效率。
