相关概念
MapReduce是一个基于HDFS的分布式计算框架,是一个可以将分布式计算抽象为Map和Reduce的编程模型,它的核心思想是分治,将大量数据分到不同机器上去分别计算最终汇总从而进行高效的数据处理,但是MapReduce不支持迭代和循环会有一定的局限性,如果有需要迭代就会需要进行多伦的MapReduce。
一:分片:
1.1:何为分片
分片的主要作用就是将一个大的文件在逻辑上进行划分,以此来将大量数据分配到不同的map任务中去进行分布的计算,InputFormat对文件根据块大小进行划分,之后recodereader会读根据分片的信息从HDFS中读入数据到Map任务中。
1.2:分片于block的关系
1.3:分片如何确定:
分片会根据块大小来进行划分,默认与块大小一致,但是也可以通过设置Hadoop属性来确定。分片大小会由下面这个公式来确定,
max( minimunsize , min( maximusize , blocksize ));
二:分区
2.1:作用:
根据Key值将数据分到不同的reduce机器上。每个key
2.2:如何进行分区
1:默认通过HashPartitioner进行分区;
2:自定义分区类继承Partitioner重写getPartitioner方法
3:使用其他内置分区器
三:分组:
分组是将reduce中相同Key的数据放到同一批次中去处理。
四:合并:
为了减少写入磁盘的数据量而进行combine操作,注意!只有当combine操作不会对最终结果产生影响时才可定义combine操作。并且只有当磁盘中的溢写文件大于预设值时才会进行combine操作。
五:归并:
将多个小的磁盘文件归并为大的已分区并且排序的磁盘文件,map端归并最终会归并为一个大文件,reduce端归并如果磁盘文件过多可能会进行多伦归并形成多个大文件,这些文件不再继续进行归并直接交给reduce端。通过配置属性mapreduce.task.io.sort.factor控制每轮归并文件数量。
MapReduce原理
六:MapReduce执行过程:
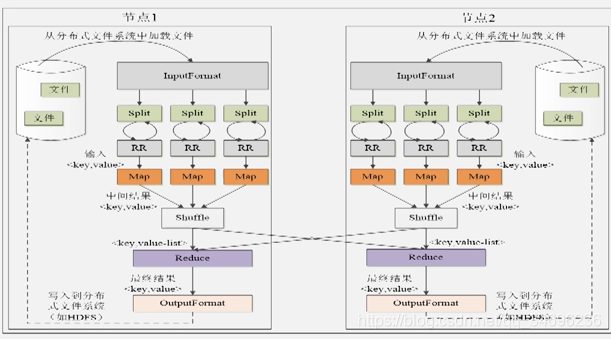
1:InputFormat从HDFS中加载文件,并且他会对文件进行一个逻辑上的划分来切分成Split:
2:RecodeReader根据分片的位置信息读取分片中的内容以Key-Value的形式输出给Map任务。
3:每个map任务对数据进行处理之后会输出Key-Value,经过shuffle之后分发给reduce机器进行处理。
4:reduce进行数据处理之后会通过OutputFormat输出到HDFS中。
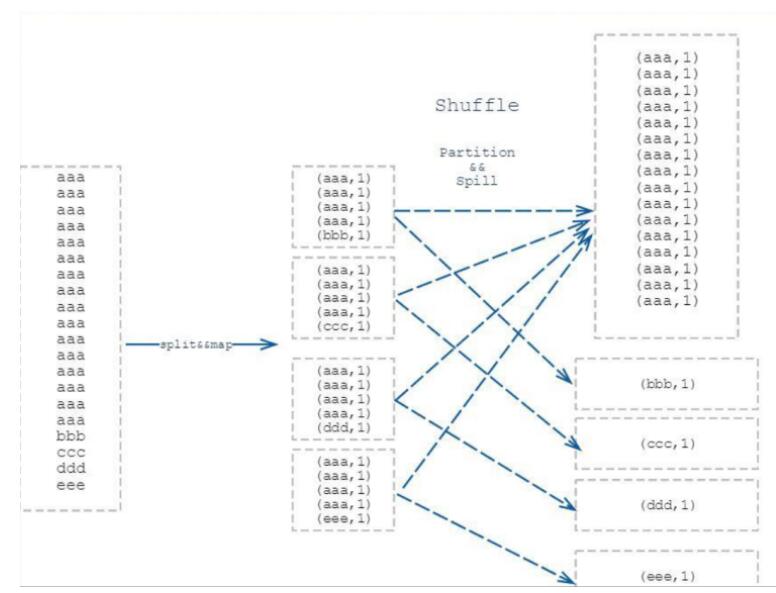
七:MapReduce的shuffle过程:
全流程:

map端:

1:每个map任务对数据进行处理之后会输出Key-Value到一个环形缓冲区.
2:当缓冲区数据达到一定阈值之后会溢写到磁盘形成多个磁盘文件,这个过程会对数据进行分区,按照key值进行排序以及如果定义conbiner函数还要进行的合并。
3:当map所有数据都溢写到磁盘之后,多个小的文件磁盘文件归并为一个大的磁盘文件之后reduce取走相应分区的数据数据
reduce端:
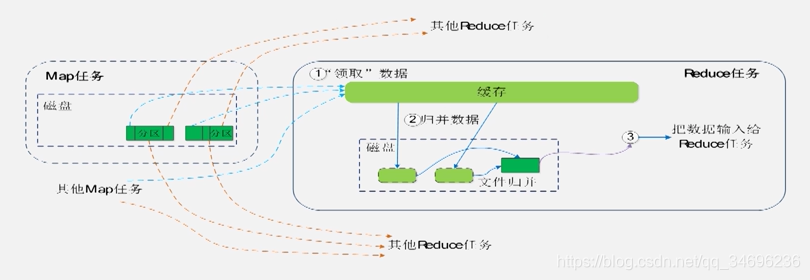
4:从不同机器的相应分区拿到数据之后会先写到缓存之中。如果缓存满了则溢写到磁盘形成磁盘文件,如果有大量磁盘文件会进行多伦归并形成多个大文件,之后每个大文件进行合并操作交给reduce进行处理。如果缓存还没满就已经读完数据就不需要溢写直接交给reduce。
八:MapReduce数据倾斜:
前面提到过mapreduce主要是分支思想,通过分治来进行高效的数据处理,那么数据的划分则尤为重要。如果要是数据划分不好导致有的机器需要处理非常多的数据从而造成的效率低下就发生了数据倾斜。这里只对MapReduce数据倾斜进行讨论。
MapReduce数据倾斜表现:
1:reduce卡在99%不动。
MapRecuce数据倾斜罪魁祸首:
shuffle,shuffle过程中由于map任务输出的Key值分布不均在导致部分数据量非常大的相同的Key-Value拉去到一台Reduce机器。
MapReduce:数据倾斜原因:
在MapReduce程序中造成数据倾斜的主要原因一般是原始数据本身就有问题,这样一来map端输出的Key-Value中部分Key可能会远远多于其他的Key-Value,因为正常来讲数据的分布很大概率是不均匀的。Hive中业务逻辑也会造成数据倾斜。
MapReduce解决数据倾斜:
如果知道是那部分数据造成数据倾斜:
将造成倾斜部分数据的Key后增加标记,使他们划分到不同Reduce。但这会对结果产生影响,所以还需在进行一次mapreduce操作。。
如果未知是哪部分数据造成数据倾斜:
在Map端进行聚集操作,效率更高但会耗费更多内存。
将所有数据的Key后增加标记再次进行划分。
肯定会有其他的方法,总之,只要能够解决reduce处理所数据的分布不均就可以缓解数据倾斜。
