Spring Cloud Hoxton 版本使用 Sleuth服务链路跟踪
前言
在上一篇文章博主已经讲解了项目如何创建,不会的话可以前往学习,传送门:Spring Cloud Hoxton 版本微服务项目搭建eureka注册中心 。
本篇用来讲解–Spring Cloud Hoxton 版本使用 Sleuth服务链路跟踪!
摘要
Spring Cloud Sleuth 是分布式系统中跟踪服务间调用的工具,它可以直观地展示出一次请求的调用过程,本文将对其用法进行详细介绍。
Spring Cloud Sleuth 简介
随着我们的系统越来越庞大,各个服务间的调用关系也变得越来越复杂。当客户端发起一个请求时,这个请求经过多个服务后,最终返回了结果,经过的每一个服务都有可能发生延迟或错误,从而导致请求失败。这时候我们就需要请求链路跟踪工具来帮助我们,理清请求调用的服务链路,解决问题。
使用
首先给相应的服务项目,添加请求链路跟踪功能的支持;
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
修改application.yml文件,配置收集日志的zipkin-server访问地址:
spring:
application:
name: xxxx # 某服务名称,注册的服务
zipkin:
base-url: http://localhost:9411
#设置Sleuth的抽样收集概率
sleuth:
sampler:
probability: 0.1
整合Zipkin获取及分析日志
Zipkin是Twitter的一个开源项目,可以用来获取和分析
Spring Cloud Sleuth中产生的请求链路跟踪日志,它提供了Web界面来帮助我们直观地查看请求链路跟踪信息。
SpringBoot 2.0以上版本已经不需要自行搭建zipkin-server,我们可以从该地址下载 zipkin-server:repo1.maven.org/maven2/io/z…
下载完成后使用以下命令运行zipkin-server:
java -jar zipkin-server-2.12.9-exec.jar
Zipkin页面访问地址:http://localhost:9411
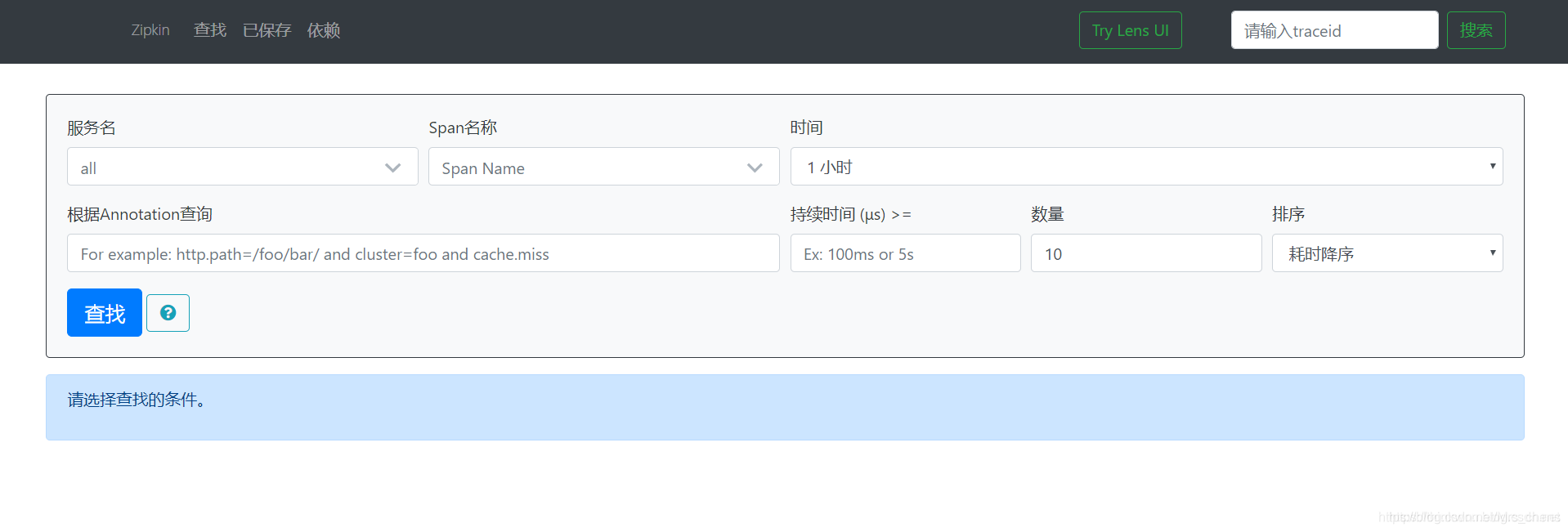

更多的使用自己多多尝试,后面会专门出一篇相关文章。
使用Elasticsearch存储跟踪信息
如果我们把
zipkin-server重启一下就会发现刚刚的存储的跟踪信息全部丢失了,可见其是存储在内存中的,有时候我们需要将所有信息存储下来,这里以存储到Elasticsearch为例,来演示下该功能。
安装Elasticsearch
下载Elasticsearch6.2.2的zip包(具体版本看自己了,要注意尽量版本统一),并解压到指定目录,下载地址:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-6-2-2

下载完成后的三个文件
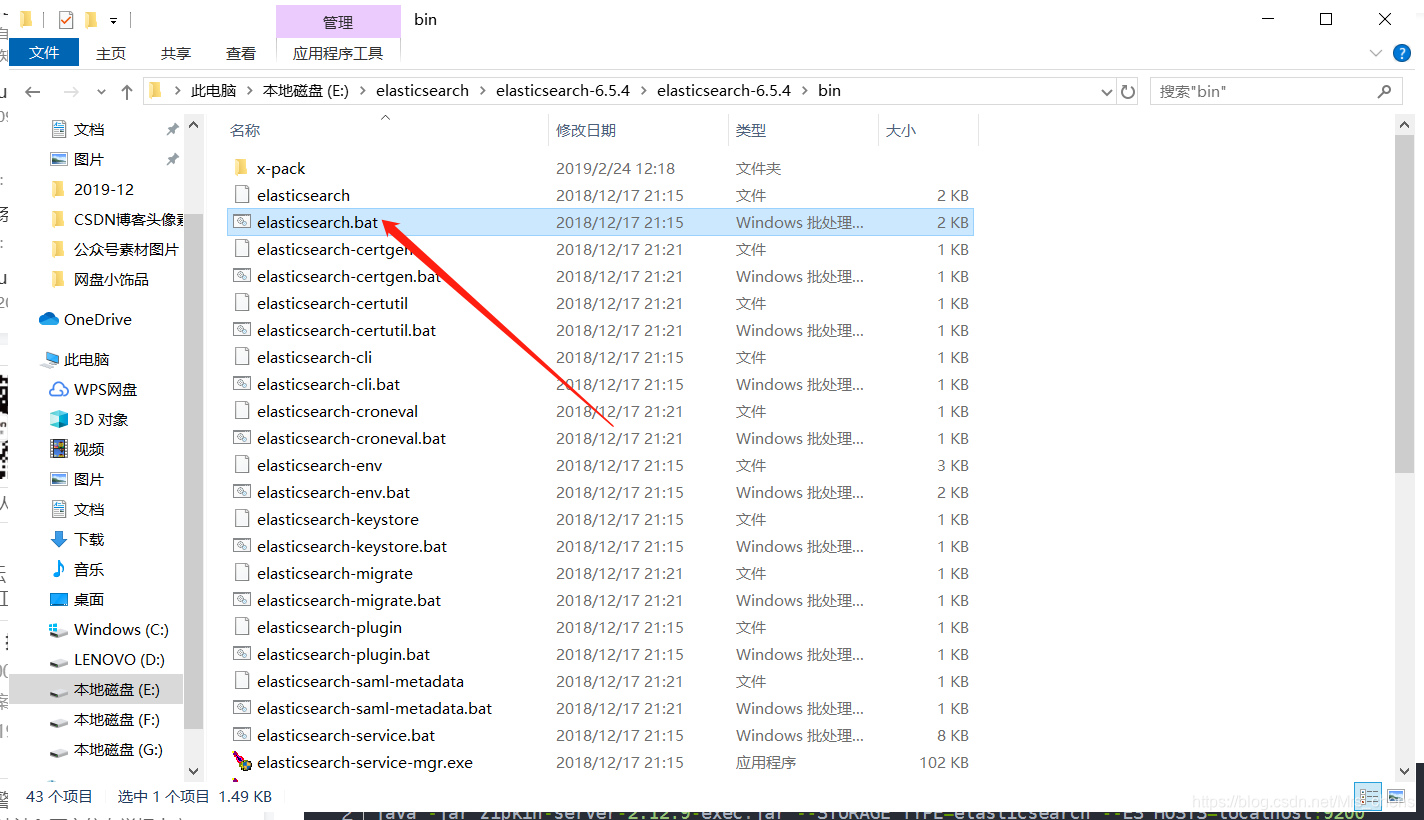
运行bin目录下的elasticsearch.bat启动Elasticsearch
修改启动参数将信息存储到Elasticsearch
使用以下命令运行,就可以把跟踪信息存储到Elasticsearch里面去了,重新启动也不会丢失;
# STORAGE_TYPE:表示存储类型 ES_HOSTS:表示ES的访问地址
java -jar zipkin-server-2.12.9-exec.jar --STORAGE_TYPE=elasticsearch --ES_HOSTS=localhost:9200
如果安装了Elasticsearch的可视化工具Kibana的话,可以看到里面的数据。
可以去参考:https://github.com/openzipkin…
其更多操作自己尝试一下!后面博主会分享---->ELK搭建日志管理平台以及SEO搜索优化等文章。
最后
-
更多参考精彩博文请看这里:《陈永佳的博客》
-
喜欢博主的小伙伴可以加个关注、点个赞哦,持续更新嘿嘿!
