玩过深度学习图像处理的都知道,对于一张分辨率超大的图片,我们往往不会采取直接压平读入的方式喂入神经网络,而是将它切成一小块一小块的去读,这样的好处就是可以加快读取速度并且减少内存的占用。就拿医学图像处理来说吧,医学CT图像一般都是比较大的,一张图片就可能达到500MB+,有的甚至超过1GB,下面是切过的一张已经被各种压缩过的肝脏CT图像的一角。
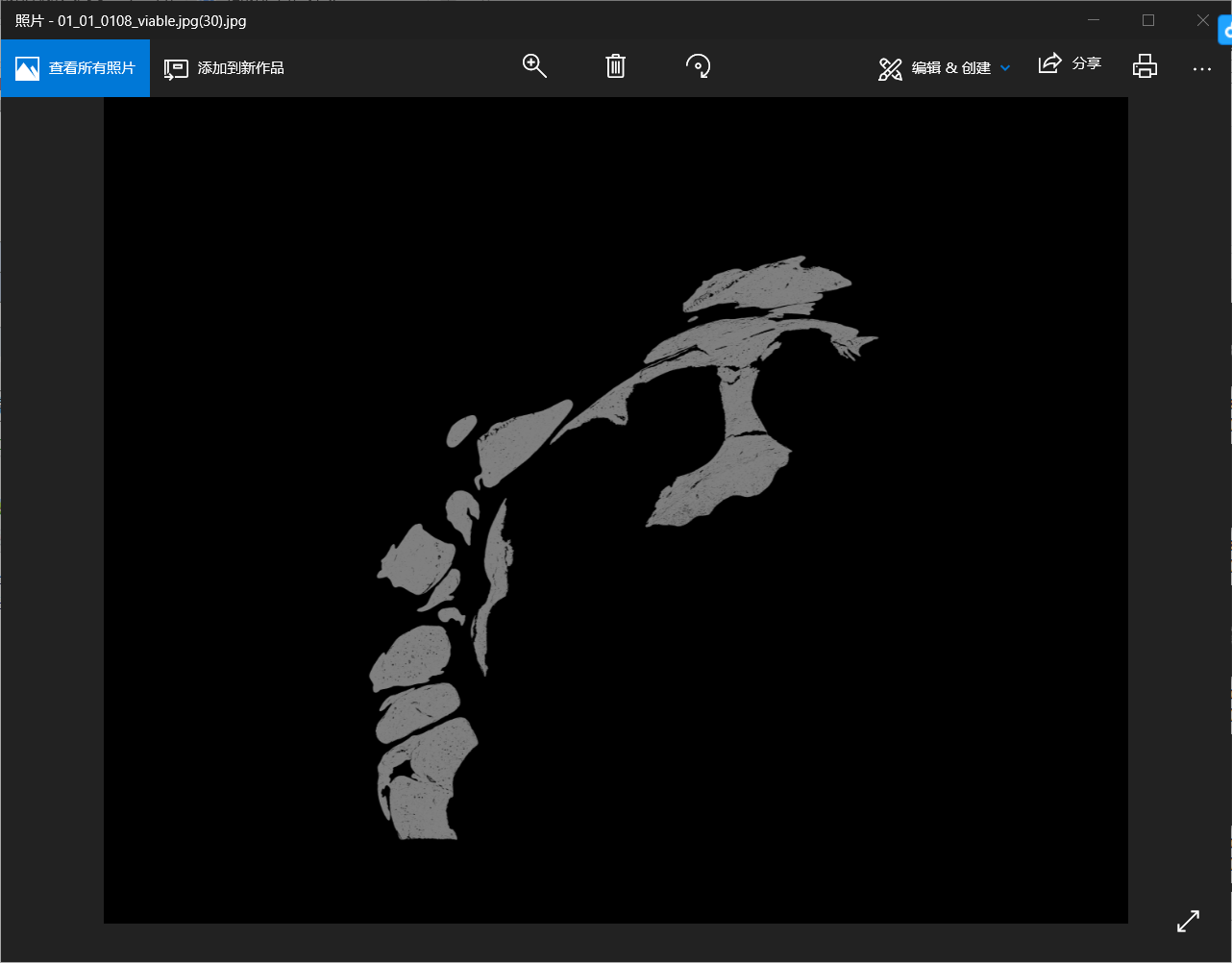
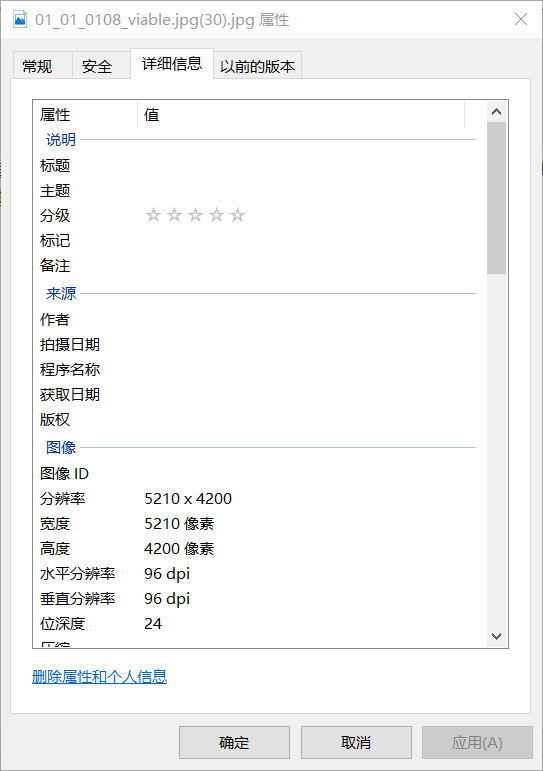
我们可以看到它的像素仍有5210*4200之多,如果直接把这样一张图片压平,将会得到一个5210*4200=21882000维的tensor,将这样一个上千万维的数据直接喂入神经网络,我不知道性能特别特别好的电脑能不能撑起来,反正我的电脑是肯定崩溃。那么如何处理这样图片呢?回到我们的标题----索引和切片。通过切片的方式我们可以把这张图片分成若干28*28(或者其他合适分辨率)的小图,分批次将这张图喂入神经网络,可想而知会取得不错的效果。接下来就记录几种索引切片的方式。
方式1:通过连续的[ ]
这种方式在各种编程语言中都很常见,即数组的索引,但是这种方式只能取到某一具体维度的数值,不能随心所欲的固定间隔或者非固定间隔的切片
a = tf.ones([1,5,5,3]) print(a[0][0]) print(a[0][0][0]) print(a[0][0][0][2])

方式2:通过[ , , ,……]
这种方式其实是numpy对方式1的一种在可读性方面的优化,和方式1相比,可读性明显提高
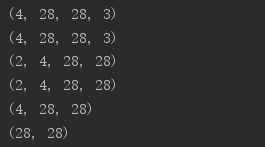
a = tf.random.normal([4,28,28,3]) print(a[1].shape) print(a[1,2].shape) print(a[1,2,3].shape) print(a[1,2,3,2].shape)

方式3:一维tensor可通过[ :]
这种方式也是python中比较常用的数组切片方式,切片范围[ A:B)
a=tf.range(10) print(a) print(a[-1:]) print(a[-2:]) print(a[:2]) print(a[:-1])

方式4:对于多维tensor可通过[ ,:,:,:……]
相对前面几种切片方式都更加丰富,也可以完成多样的切片(跳过某一维度)start:end
a = tf.random.normal([4,28,28,3]) print(a[0,:,:,:].shape) print(a[0,1,:,:].shape) print(a[:,:,:,0].shape) print(a[:,:,:,2].shape) print(a[:,0,:,:].shape)

方式5:隔行采样[ : : ,: : ,: : ,……]
通过增加了一个:,使用方式start:end:step进行间隔采样(::step代表从最开始到最末尾以步长step间隔采样)
a = tf.random.normal([4,28,28,3]) print(a[:,0:28:2,0:28:2,:].shape) print(a[:,:14,:14,:].shape) print(a[:,14:,14:,:].shape) print(a[:,::2,::2,:].shape)

注:若step<0则倒序采样
方式6:用…进行采样
...可以代替连续的:,增强代码的易书写性和可读性
a = tf.random.normal([2,4,28,28,3]) print(a[0,:,:,:,:].shape) print(a[0,...].shape) print(a[:,:,:,:,0].shape) print(a[...,0].shape) print(a[0,...,2].shape) print(a[1,0,...,0].shape)
方式6:selective indexing
使用tf.gather、tf.gather_nd、tf.boolean_mask进行随机采样
(1)tf.gather(在某一维度指定index)
# 下面的tensor即表示,4个班级,每个班级35名学生,每个学生8门课的成绩 a = tf.random.normal([4,35,8]) # axis表示维度,indices表示在axis维度上要取数据的索引 print(tf.gather(a,axis=0,indices=[2,3]).shape) # 可理解为取第2、3个班级的学生成绩,同a[2:4].shape print(tf.gather(a,axis=0,indices=[2,1,3,0]).shape) # 可理解为依次取第2、1、3、0个班级的学生成绩 print(tf.gather(a,axis=1,indices=[2,3,7,9,16]).shape) # 可理解为取所有班级第2,3,7,9,16个学生的成绩 print(tf.gather(a,axis=2,indices=[2,3,7]).shape) # 可理解为取所有班级所有学生第2,3,7门课的成绩

(2)tf.gather_nd(在多个维度指定index)
a = tf.random.normal([4,35,8]) # axis表示维度,indices表示在axis维度上要取数据的索引 print(tf.gather_nd(a,[0]).shape) # 可理解为取0号班级的所有成绩 print(tf.gather_nd(a,[0,1]).shape) # 可理解为取0号班级1号学生的成绩 print(tf.gather_nd(a,[0,1,2]).shape) # 可理解为取0号班级1号学生的第2门课成绩 print(tf.gather_nd(a,[[0,0],[1,1]]).shape) # 可理解为取0号班级0号学生和1号班级1号学生的成绩 print(tf.gather_nd(a,[[0,0],[1,1],[2,2]]).shape) # 可理解为取0号班级0号学生、1号班级1号学生、2号班级2号学生的成绩 print(tf.gather_nd(a,[[0,0,0],[1,1,1],[2,2,2]]).shape) # 可理解为0班0学0课,1班1学1课,2班2学2课的成绩 print(tf.gather_nd(a,[[[0,0,0],[1,1,1],[2,2,2]]]).shape) # shape与上不同

(3)tf.boolean_mask(通过True和False的方式选择数据)
a = tf.random.normal([4,28,28,3]) print(tf.boolean_mask(a,mask=[True,True,False,False]).shape) print(tf.boolean_mask(a,mask=[True,True,False],axis=3).shape) a = tf.ones([2,3,4]) print(tf.boolean_mask(a,mask=[[True,False,False],[False,True,True]]))
