一。一些用到的概念
数据结构:数据间一种或多种 特定关系 的元素的集合
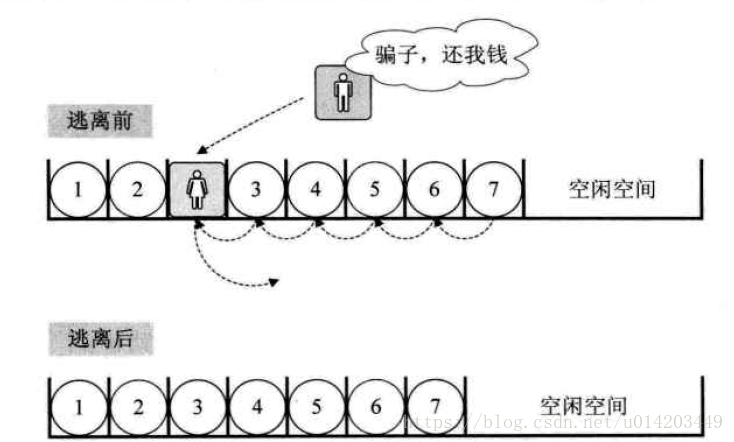
存储结构:1.顺序存储,数据是存放是连续的(美女来插队,所有人往后退一步)
2.链式存储,数据存放不是连续的,但之间有联系保证找到下一个数据,跟卧底一样,之间是单线联系()
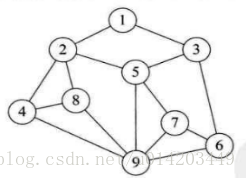
逻辑结构:数据对象中数据元素之间的相互关系,集合结构、线性结构、树形结构、图形结构


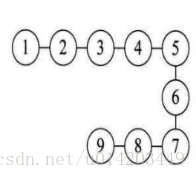
物理结构(存储结构):1.顺序存储结构,数据是连续存放的(举例美女来1和2间插队,所有人都得往后移步)
2.链式存储结构,数据不放在一起(像特务卧底一样,数据间单线联系,数据不会被一窝端,中间要断了,上下就找不到了)

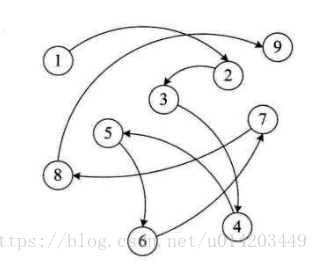
数据类型:一组性质相同的值的集合及定义在此集合上的一些操作的总称(可以理解为类,一些操作是类的方法)
抽象数据类型:一个数字模型及定义在该模型上的一组操作(根类会抽出 子类们共有的方法)
二。线性表(List)


a1是a2的前驱,ai+1 是ai的后继,a1没有前驱,an没有后继
n为线性表的长度 ,若n==0时,线性表为空表
下图是线性表,一行为一个数据a
1.顺序存储方式线性列表
存储位置连续,可以很方便计算各个元素的地址
如每个元素占C个存储单元,那么有:
Loc(An) = Loc(An-1) + C,于是有:
Loc(An) = Loc(A1)+(i-1)*C;

像美女插队,后面数据都要移动,较消耗资源
最简单的顺序存储线性表是数组。
ArrayList由数组组成,能放各种元素,必然是泛型Object[]数组,必然会有类似插队这种 add、remove方法,它继承的抽象类、实现的接口 会把共有的方法抽出来isClear、iterator 、set、get等
注:我用的是jdk1.8
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
来看add方法,感受下线性表
private static final int DEFAULT_CAPACITY = 10;//默认容量,一次加10
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;//ArrayList中存储数据的数组
private int size;//拥有元素的个数
public boolean add(E e) {
ensureCapacityInternal(size + 1); // size+1是需要的最小容量,这步结束后,elementData会变成一个扩容后的新数组
elementData[size++] = e; //把新元素e放进数组,size本身+1,其实就是当前索引
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { //如果原数组是空数组,则最小容量是 10 和 size+1 中较大值。
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);//为什么这么写?。。。这个方法不光add用,比如addAll也会用
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;//我们每对ArrayList操作一次,modCount就会+1
// overflow-conscious code
if (minCapacity - elementData.length > 0)//如果需要的最小容量 比目前数组的长度还大的话,就需要扩容
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;//原数组长度
int newCapacity = oldCapacity + (oldCapacity >> 1);//左移1位是乘2,右移是除2,新容量是原长度的二分之三
if (newCapacity - minCapacity < 0)//如果新容量比最小容量还小,新容量就直接等于最小容量
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)//如果新容量大于 集合最大,就和Interger的最大值比较
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);//用原数组、和新容量 生成一个新数组
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
//Arrays的方法
@SuppressWarnings("unchecked")
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)//如果新数组的类型是object 就new一个长度为新容量的数组,否则就产生一个 为newType类型的长度为新容量的数组
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0, //数组是不能扩容的,只能用新的数组
Math.min(original.length, newLength));//复制original原数组的内容到 新的copy数组,从0开始复制,copy从0开始接收,复制元素的个数是元素组长度和新容量的小zh
return copy; //复制元素的个数是元素组长度和新容量的小值,在这就是把原数组所有内容复制过去
}
add(E element)方法还好,只是再数组尾端加元素。容量够的话并不太消耗资源去创建新数组,但add(int index,E element)就是在集合指定索引处插入元素,会让后面的元素都往后移,会创建新数组
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
再看看remove方法,移除指定索引处元素:
public E remove(int index) {
rangeCheck(index);//校验下索引别越界
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1; //需要移动的元素数量 size-1 其实就是最后一个元素索引
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,//复制元素,从移除的元素后一位,移除的个数
numMoved);
elementData[--size] = null; //把最后一个元素置空,因为最后一个其实移到前一个位置了;size变化
return oldValue;
}
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
set方法就是把原位置上的元素替换了
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
toArray方法获得一个数组,就是简单的把原数组中的内容拷贝到新数组,toArray方法产生新数组的length通常等于元素个数size
public <T> T[] toArray(T[] a) {
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
看看迭代器
Iterator
public Iterator<E> iterator() {
return new Itr();//返回一个迭代器
}
/**
* An optimized version of AbstractList.Itr
*/
private class Itr implements Iterator<E> {//Arraylist的内部类
int cursor; // index of next element to return 返回的下一个元素索引,游标
int lastRet = -1; // index of last element returned; -1 if no such 上一个返回的元素索引
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size;//size和cursor相等说明往后没元素了
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;//获取arraylist中的数组
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
还有ListItr迭代器,也是内部类
private class ListItr extends Itr implements ListIterator<E> {
ListItr(int index) {
super();
cursor = index;
}
indexOf :就是遍历数组,找到索引,越看越简单
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
2.链式存储线性列表
线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素,这组存储单元可以是连续的,也可以是不连续的
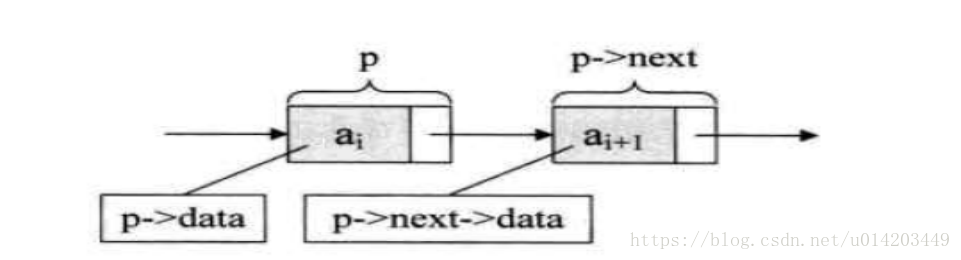
存储单元由两部分组成,数据源和指针,数据源放数据,指针指向下个存储单元。
用java 表示下:
public Class P{
Object data;
p next;//指针直接指向下一个P对象
}
P p1=new P(); p1.data="melo"; P p2=new P();
p1.next=p2;
优:删除还插入效率高 缺:查询效率低
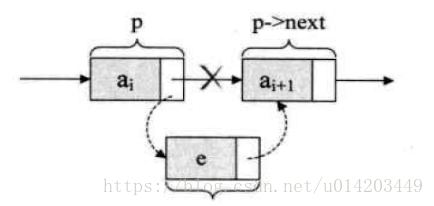
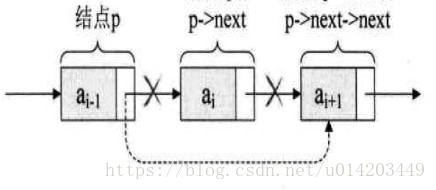
循环列表:将单链表中终端结点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相连的单链表称为单循环链表,简称循环链表

双向循环链表:双向循环链表是单向循环链表的每个结点中,再设置一个指向其前驱结点的指针域

空的双向循环列表:
LinkedList采用的就是链式存储线性表,来看看。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
/**链表中的第一个节点、存储单元
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**链表的最后一个节点、存储单元
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
//内部类,就理解为节点、存储单元吧
private static class Node<E> {
E item; //存放的数据,是泛型
Node<E> next; //上一个节点,跟刚刚写的java P类一样,指针指向上个节点对象
Node<E> prev; //下个节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
双向列表的插入:
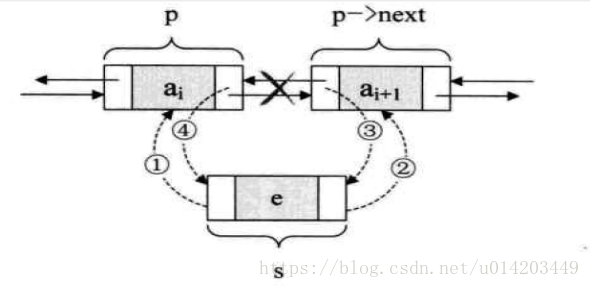
add方法:
public void add(E e) {
linkLast(e);
}
void linkLast(E e) {
final Node<E> l = last; //原最后节点要变倒数第二个
final Node<E> newNode = new Node<>(l, e, null); //新的节点,上指针连着原最后的节点,下指针连null
last = newNode; //链表的最后节点 变为新赠的节点
if (l == null)
first = newNode;//如果原最后节点是null,说明链表本身就是空的
else
l.next = newNode;//否则倒数第二个节点指向最后的节点
size++;
modCount++;
}
add(int index, E element)方法:从这里可以发现 LinkedList本没有index索引的概念,本来就不是数组,只是通过size遍历找索引处的节点
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size) //如果添加的位置是最后一个,和add方法一样
linkLast(element);
else
linkBefore(element, node(index)); //node(index)找到指定索引处的这个节点
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) { //指定索引如果小于 size的一半,则从集合的首节点开始遍历,找到索引处节点
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else { //指定索引如果大于size的一半,则从集合的尾节点开始遍历,找到索引处节点
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
void linkBefore(E e, Node<E> succ) { //succ就是指定索引目前的节点,把succ和前节点断开联系,都和新节点建立关联即可,记得把size+1
// assert succ != null; //
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
双向列表的删除:
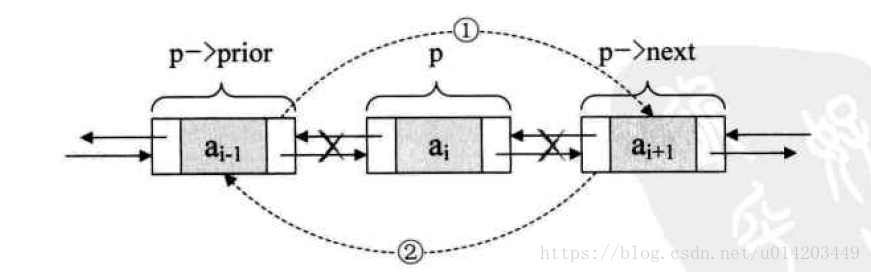
remove方法:
public boolean remove(Object o) {
if (o == null) { //移除数据是null的节点,从首个节点开始遍历,找到第一个数据为null的节点
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) { //从首个节点遍历,找到首个数据和o一样的节点
unlink(x);
return true;
}
}
}
return false;
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next; //要移除节点的下个节点
final Node<E> prev = x.prev; //要移除节点的上个节点
if (prev == null) { //如果上个节点是null,说明本就是第一个节点,移除后首节点变为next
first = next;
} else {
prev.next = next; //如果上个节点不是null,就把指针指向next
x.prev = null;
}
if (next == null) { //如果下个节点是null,说明本身就是尾节点,移除后尾节点变为last
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null; //移除节点数据置null
size--; //linkedlist元素数量-1
modCount++;
return element;
}
indexOf:从头节点遍历,找到数据符合的
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
peek:找到首节点的数据
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
poll:弹出首个元素,首元素变为下个元素,其实就是首节点变成下个节点
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
private E unlinkFirst(Node<E> f) {
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null;
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
toArray:遍历所有节点,把数据放入新数组,新数组的length通常等于元素个数size
public Object[] toArray() {
Object[] result = new Object[size];
int i = 0;
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
return result;
}