(本文是笔者查阅一定资料整理原创所写,受知识面限制,如存在错误,欢迎指出)
第一部分: Analytic Visualizations
数据分析的基本要求。
大数据分析的对象主要为海量数据,涉及到的数据由于受限于获取途径,管理方式等因素,可能存在一定程度上的不统一,缺失等问题,再加上现阶段大数据分析通常仍然由人工分析为主,故仍然存在一定程度的分析不确定性。这时,辅助以可视化数据分析平台,借助于可视化图表更容易建立数据之间直观的关联关系。同时更有助于与他人之间进行数据信息方面的交流和传递。 
第二部分.:Data Mining Algorithms
与 Analytic Visualizations箱对应的是Data Mining Algorithms,即数据挖掘算法与可视化分析的关系。数据挖掘算法的服务对象是计算机本身,而可视化分析的服务对象为涉及数据分析的分析者及使用者。
与常规计算机算法追求的空间效率与时间效率相同的是,一个优秀的数据挖掘算法同样追求的是能以更快的处理速度处理更大的数据量以获取更有价值的挖掘信息。
具体算法因处理的数据对象及处理的目标期望的不同而不同,常见的数据挖掘算法包括决策树算法,k-均值聚类等。
第三部分:Predictive Analytic Capabilities
利用统计类工具,如预测模型,机器学习,数据挖掘等方法对所获取的数据进行信息提炼实现对事物未来的发展方向进行预测的一个过程,是大数据分析与现实生活关联最紧密的一个部分。
随着信息时代的进一步到来,大数据分析在商业领域的应用越来越广泛。对获取数据的信息提炼,商家很容易评估可能存在的风险和潜在的商机,这也是为什么目前世界五百强企业大多建立了自己企业的信息部门的原因。
预测性分析最典型的一个应用就是金融体系的信用评分。金融服务机构根据分析客户贷款,信用记录等数据评估其消费能力制定针对性的服务项目。

第四部分:Semantic Engines
语义技术的直接应用,即通过分析用户所传递信息实现在语义层面上对用户检索要求的认识和处理。
如可视化分析部分提及,由于数据获取方式等诸多因素所带来的非结构化数据等诸多问题,解析,提取,分析数据本身即存在一定的局限性,而语义引擎便是建立在此基础上提取信息的一种方式。
目前大数据分析相对成熟体系的Hadoop体系的大数据架构包括五大架构分类:传统大数据架构,流式架构,Lambda架构,Kappa架构,Unifield架构,此处由于笔者目前实力有限,暂不进行详细分析。
第五部分.:Data Quality and Master Data Management
这一部分相对容易理解,百度上对于数据质量和数据管理的定义是“对数据从计划、获取、存储、共享、维护、应用、消亡生命周期的每个阶段里可能引发的各类数据质量问题,进行识别、度量、监控、预警等一系列管理活动,并通过改善和提高组织的管理水平使得数据质量获得进一步提高。”
好的数据质量有助于分析师们提炼出更有价值的信息,这就需要分析师们在信息因素、技术因素、流程因素和管理因素等因素上对数据的质量加以控制。
第六部分:Data Warehouse
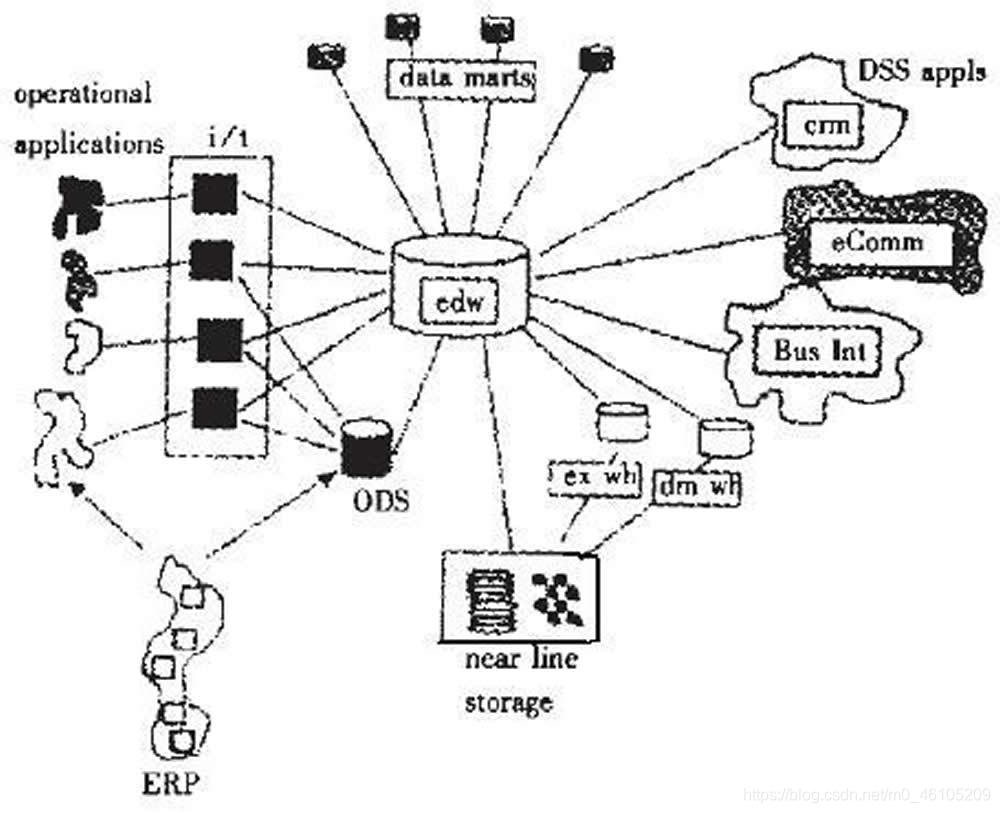
“数据仓库”一概念由计算机科学家比尔.恩门首次提出,泛指为服务者的决策制定过程提供所有需求数据类型支持的战略集合。
数据仓库一定是面相服务对象所建立的,因此数据仓库具有一定的主题性概念,同时数据仓库的数据来源往往是分散的操作性数据,但进入仓库的数据通常是经过了一定的加工,集成,被赋予了一定价值的数据。
由于数据仓库的建立目的是为决策者提供数据,所以数据仓库具有不可更新的特点。除此之外,数据仓库还包含了:效率足够高,数据质量,扩展性等一系列特点。
大数据分析的六大基本组成

猜你喜欢
转载自blog.csdn.net/m0_46105209/article/details/104013731
今日推荐
周排行