0.前言
最近的Android项目里有用到Protocol Buffer,Protocol Buffer是Google公司开发的一种数据描述语言,类似于XML,是一种结构化数据的数据存储格式,可用于数据传输量较大的即时网络通信IM等场景。之所以使用它,说明它是有不可替代的优势,这里借用CarSon的一张图来说明:
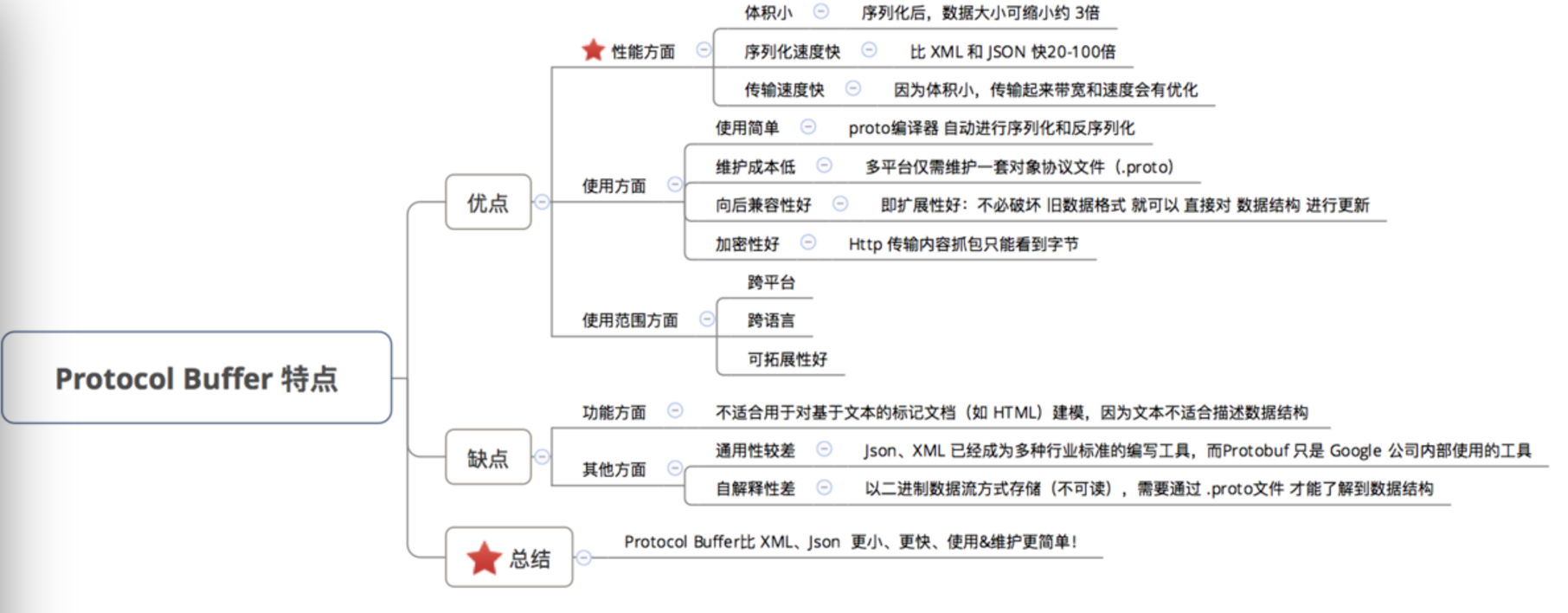
Protocol Buffer主要的优势在于三点:
(1)体积小速度快。像XML这种报文是基于文本格式的,存在大量的描述信息,虽然对于人来说可读性更好,但增加了序列化时间、网络传输时间等。导致系统的整体性能下降。而PB则将信息序列化为二进制的格式,安全性提高的同时,序列化后的数据大小缩小了3倍,序列化速度比Json快了20-100倍,也必然会减小网络传输时间。
(2)跨平台跨语言。接收端和发送端只需要维护同一份proto文件即可。proto编译器会根据不同的语言,生成对应的代码文件。
(3)向后兼容性。还有一个非常重要的优点就是可以不必破坏旧的数据格式,就可以直接对数据结构进行更新。
1.Protocol Buffer的使用
1.1 Protocol Buffer安装包下载
Protocol Buffer目前有2和3两个版本,不知道为啥项目中用的是2版本,因此本文也就使用2的版本吧,可以到官网(自备梯子)下载2.6.1版本的安装包。后面会介绍3对于2做的一些改变。
1.2 安装Protocol Buffer
本文使用Mac操作系统。首先在终端使用HomeBrew安装各种依赖。
brew installautoconf automake libtool curl
./autogen.sh
./configure最后编译未编译的依赖包。
make
make check //检查依赖包是否完整
make install //开始安装PB
protoc –version //验证是否安装成功
1.3 编写proto文件
现在编写一个demo.proto文件作为消息的模型。有了proto文件,PB才会为我们生成相应的代码。有点像AIDL语言的感觉。
syntax = "proto2";
package com.example.calvin.helloworld;
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
message AddressBook {
repeated Person person = 1;
}
(1)首先声明了使用的PB的版本是2,接着是声明一个包名,包名同Android项目的包名。
(2)接着使用message关键字声明了一个People结构体和一个同级的AddressBook的结构体表示通讯录。内部使用repeated声明这个通讯录里可以有N个People。
(3)在看People结构体里面,声明了一个姓名、ID、以及Email,最后是一个枚举类型的号码,并使用repeated声明一个人不止有一个号码。这个号码的信息嵌套在了People结构体内,也是使用message来声明的PhoneNumber,内部是String类型的号码,以及号码类型即为刚才声明的枚举类型,默认为HOME。
(4)最后就是诸如required string name = 1意义,required和optional表示字段修饰符,string为字段类型,最后的1表示标示号。
required表示是一个必须字段,发送方在发送消息之前必须设置该字段的值,接收方必须能够识别该字段的意思。否则会导致消息被丢弃。optional表示是一个可选字段,发送方可以不用设置该字段的值。接收方如果能够识别可选字段就进行相应的处理,如果无法识别,则忽略该字段。因为optional字段的特性,后来添加的字段都统一的设置为optional字段,这样老的版本无需升级程序也可以正常的与新的软件进行通信,只不过新的字段无法识别而已,可以做到按需升级和平滑过渡。
关于字段类型,可以看到使用到了int32等不同于Java的字段类型,具体可以参考下面这张官网上的对照表。
右边四列分别为C++,Java,Python以及Go。

最后是标示号,范围为[1,2^29-1],每个消息的字段都有一个唯一的数字标签,用来表示你的字段在二进制消息中处的位置。标示号一旦指定,在使用过程中不可以更改。
标示号范围[1,15]表示该字段在编码时占1个字节,一般用于频繁出现的消息字段。
范围[16,2047]表示占2个字节。
不能使用[19000,19999]的标签号,这些标签号是为protobuf内部所保留的。
1.4 编译proto文件
把proto文件置于protobuf-2.6.1的根目录下,切换到该目录并执行下面的编译命令。
protoc ./demo.proto --java_out=./
1.5 应用到Android项目中
把新生成的Demo.java拷贝到Android工程中即可进行使用。首先添加Gradle依赖,版本号要一致。
compile 'com.google.protobuf:protobuf-java:2.6.1'
Demo.Person.Builder personBuilder = Demo.Person.newBuilder();
//该字段的字段修饰符是required,所以必须赋值
personBuilder.setName("Calvin");
personBuilder.setId(150884);
personBuilder.setEmail("[email protected]");
Demo.Person.PhoneNumber.Builder phoneNumber = Demo.Person.PhoneNumber.newBuilder();
phoneNumber.setNumber("025-83792727");
phoneNumber.setType(Demo.Person.PhoneType.HOME);
Demo.Person.PhoneNumber Calvin_Phone = phoneNumber.build();
List<Demo.Person.PhoneNumber> myNumberList = new ArrayList<>();
myNumberList.add(Calvin_Phone);
personBuilder.addAllPhone(myNumberList);
Demo.Person Calvin = personBuilder.build();
Demo.AddressBook.Builder book_bd = Demo.AddressBook.newBuilder();
List<Demo.Person> myPeopleList = new ArrayList<>();
myPeopleList.add(Calvin);
book_bd.addAllPerson(myPeopleList);
Demo.AddressBook book = book_bd.build();
这里就得到了book实体,包含了一个通讯录中的全部信息。接着就可以使用book.toByteArray()进行序列化,得到二进制的字节数组。反序列化也很简单直接使用Demo.AddressBook.parseFrom(byteArray)将字节数组重新包装成一个Demo.AddressBook的实体。也可以使用book.writeTo(outputStream)将其打成输出流的形式,parseFrom方法是可以接收一个输入流进行反序列化的。
结果如下:

还有PB是支持将类实体和json的相互转换的,很贴心!
compile 'com.googlecode.protobuf-java-format:protobuf-java-format:1.4'//添加依赖
//转json
JsonFormat jsonFormat = new JsonFormat();
String result_json = jsonFormat.printToString(book);
//json转实体对象
Message.Builder builder = Demo.AddressBook.newBuilder();
InputStream input_json = new ByteArrayInputStream(result_json.getBytes()); jsonFormat.merge(input_json, builder);
Demo.AddressBook result_json_msg = (Demo.AddressBook) builder.build();

2 不适合Protocol Buffer的地方
2.1 Protocol Buffer的缺点
Protocol Buffer虽然很好用,但是也是有缺点的:
(1)不适合对如HTML文件等基于文本标记文档的建模,因为数据结构不适合描述文本。
(2)序列化成二进制数据带来了速度快体积小更安全等特性,但是也不可避免地带来了可读性差的问题。
2.2 什么时候更适合使用Json
有些时候JSON比Protocol Buffers更适合,包括如下的场景:
(1)你需要或者想让数据对人是可读的。
(2)服务端应用程序是用javaScript编写,并且这些数据是直接发送到web浏览器。
(3)不想添加另外一个工具到你的项目中。
3 Protocol Buffer3做出的一些改变
(1)只保留repeated标记数组类型,optional和required都被废弃了。
(2)default标记不能再使用。类似于这种:[default=XX]。理由是如果序列化端的default和反序列化端的default描述不一样会导致最终结果完全不一致。
(3)proto2里的默认值是枚举的第一个value对应的值,不一定为0。proto3在你定义value时,强制要求第一个值必须为0。
( 4 )其他改变可参考官方文档。