Yolov1
Yolov1是Yolo 系列的开山之作,论文中给出了具体的损失函数。
其思想本质也极为简单暴力,把目标检测问题看成是一个回归问题,
坐标,宽高,分类,置信度(有目标置信度,没有目标置信度)损失都采用SSE损失函数,一顿狂怼,依赖平台算力把目标检测出来,没有什么特别的技巧。。
其输出向量形式为7 * 7 * (2 * 5 + 20) = 7 * 7 * 30
损失函数定义如下:

Yolov2
Yolov2是Yolov1的升级版,
- 使用K-mean聚类的方法产生anchor box的数目,聚类采用1—IOU(box,centriod)作为距离度量,然后在模型复杂度和召回率之间作了一个权衡,确定了K=5。
此外,Yolov1是基于单元格进行预测,所以一个单元格只能预测一个目标。yoloV2每个单元格有5个anchor box,且单元格编码方式改变了,编码基于单元格的anchor bo一个单元格可以同时预测多个类别。 - 所有卷积层都应用BN,加快收敛和减少过拟合。
- 输入多尺度训练(因为只有卷积层和Pooling层,可以随时改变尺寸,每10epoch改变一次输入尺寸)。
- feature map网格划分是 13 * 13,其输出向量编码形式是 13 * 13 * 5 * (C + 5) ,得到更精细的特征,适应小目标检测。
Yolov2的损失函数跟Yolov1差别不大,唯一的差别就是关于bbox的w和h的损失去掉了根号,作者认为根号没有必要,即
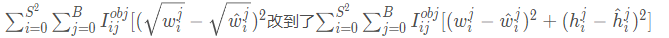
Yolosv3
Yolov3 采用了类FPN的特征融合的思想,将深层的语义特征和浅层的细节特征进行融合,是预测精度得到进一步提升。
- YOLO3延续Yolov2聚类得到先验框的这种方法,为每种下采样尺度设定3种先验框,总共聚类出9种尺寸的先验框。在COCO数据集这9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。

- 对象分类由softmax改成logistic。预测对象类别时不使用softmax,类别分数执行 softmax 操作的前提是类别是互斥的,改成使用logistic的输出进行预测。这样能够支持多标签对象(比如一个人有Woman 和 Person两个标签),
- 多尺度密集预测。对于一个416416的输入图像,在每个尺度的特征图的每个网格设置3个先验框,总共有 13 * 13 * 3 + 26* 26 * 3 + 52* 52 * 3 = 10647 个预测。每一个预测是一个(4+1+80)=85维向量,这个85维向量包含边框坐标(4个数值),边框置信度(1个数值),对象类别的概率(对于COCO数据集,有80种对象)。
对比一下,YOLO2采用13 * 13 * 5 = 845个预测,YOLO3的尝试预测边框数量增加了10多倍,而且是在不同分辨率上进行,所以mAP以及对小物体的检测效果有一定的提升。 - 采用残差结构,形成更深的网络层次,以及多尺度检测,提升了mAP及小物体检测效果。
损失函数分为x/y损失,w/h损失,置信度损失,类别损失。
a)xy loss
xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, raw_pred[..., 0:2], from_logits=True)
可以看出,是一个binary_crossentropy损失。
b)wh损失
wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh - raw_pred[..., 2:4])
是一个方差。
c)置信度损失
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) + (1 - object_mask) * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) * ignore_mask
用的是sigmoid函数代替softmax来计算概率分布,损失函数采用采用的是二分类交叉熵。
d)最后,对loss进行简单的加总求和取均值
xy_loss = K.sum(xy_loss) / mf
wh_loss = K.sum(wh_loss) / mf
confidence_loss = K.sum(confidence_loss) / mf
class_loss = K.sum(class_loss) / mf
loss += xy_loss + wh_loss + confidence_loss + class_loss
