声明:本文所有内容由本人撰写转载请注明出处!
小波包变换常用于提取非线性信号的特征,常应用于故障诊断领域的故障特征提取。
但是网络上的实例都是用MATLAB实现的,至少我还没发现用Python完完整整实现小波包特征提取实例的。
本文给出使用Python做小波包特征提取的一个实例,并附有MATLAB编写的实现源码。
数据来源:自己采集得到的模拟电路故障响应数据,存在SumData文件夹中,其中文件夹共有9个excel文件,每一个excel文件存的是某种故障状态下采集得到的100组故障响应数据。
对单个Excel文件里面的100组数据做小波包分析提取特征的code如下:
import wavelet
import numpy as np
import matplotlib.pyplot as plt
import os
from sklearn import preprocessing
import pywt
import pywt.data
#获取样本矩阵的特征向量
def WaveletAlternation(SingleSample_Data):
Featureweidu, SingleDir_Samples = SingleSample_Data.shape #获取矩阵的列数和行数,即样本维数 2043 * 100
SingleDir_SamplesFeature =np.zeros((SingleDir_Samples,8)) #定义样本特征向量 #Array 形式
# SingleDir_SamplesFeature = [] # list形式
for i in range(SingleDir_Samples):
SingleSampleDataWavelet = SingleSample_Data[:,i] #对第i列做小波包分解
#进行小波变换,提取样本特征
wp = pywt.WaveletPacket(SingleSampleDataWavelet, wavelet='db3', mode='symmetric', maxlevel=3) #小波包三层分解
# print([node.path for node in wp.get_level(3, 'natural')]) #第3层有8个
#获取第level层的节点系数
aaa = wp['aaa'].data #第1个节点
aad = wp['aad'].data #第2个节点
ada = wp['ada'].data #第3个节点
add = wp['add'].data #第4个节点
daa = wp['daa'].data #第5个节点
dad = wp['dad'].data #第6个节点
dda = wp['dda'].data #第7个节点
ddd = wp['ddd'].data #第8个节点
#求取节点的范数
ret1 = np.linalg.norm(aaa,ord=None) #第一个节点系数求得的范数/ 矩阵元素平方和开方
ret2 = np.linalg.norm(aad,ord=None)
ret3 = np.linalg.norm(ada,ord=None)
ret4 = np.linalg.norm(add,ord=None)
ret5 = np.linalg.norm(daa,ord=None)
ret6 = np.linalg.norm(dad,ord=None)
ret7 = np.linalg.norm(dda,ord=None)
ret8 = np.linalg.norm(ddd,ord=None)
#8个节点组合成特征向量
SingleSampleFeature = [ret1, ret2, ret3, ret4, ret5, ret6, ret7, ret8]
SingleDir_SamplesFeature[i][:] = SingleSampleFeature #Array 形式
# SingleDir_SamplesFeature.append(SingleSampleFeature) #list 形式
# print('SingleDir_SamplesFeature:', SingleDir_SamplesFeature)
return SingleDir_SamplesFeature
上面code提取返回单个文件的100组样本的特征集SingleDir_SamplesFeature,现对整个文件夹的9个Excel文件做特征提取操作,code如下:
#获取文件夹中9个文件的特征向量
def Folder_SamplesFeatures(filename):
#folder_allSamplefeatures =[] #list 形式
folder_allSamplefeatures = np.zeros((100, 8)) #Array 形式
list = os.listdir(filename) #列出文件夹下所有的目录与文件
for i in range(0,len(list)):
path = os.path.join(filename,list[i])
if os.path.isfile(path):
my_matrix = np.loadtxt(open(path,"rb"),delimiter=",",skiprows=0)
Single_dir_SampleData = my_matrix[:,1: 101] #去除第一列数据,获取单个Excel里面的100组样本
Single_dir_Result = wavelet.WaveletAlternation(Single_dir_SampleData)
# folder_allSamplefeatures.append(Single_dir_Result) #list 形式
folder_allSamplefeatures = np.vstack((folder_allSamplefeatures,Single_dir_Result)) #垂直组合 Array形式
folder_allSamplefeatures = folder_allSamplefeatures[100:1000][:] #减掉前面100个多余数组,得到900个样本特征向量
return folder_allSamplefeatures
上面code对文件夹操作得到9个文件对应样本特征的组合,即900组样本特征-folder_allSamplefeatures。
但是,如果直接用这没有归一化的数据作为分类模型的输入,会导致计算量增加、训练时间过久等,故需要对返回的folder_allSamplefeatures做归一化操作。
对900组特征集做归一化操作code如下:
#归一化特征数据,范围(0,1)
def maxminnorm(array):
maxcols=array.max(axis=0)
mincols=array.min(axis=0)
data_shape = array.shape
data_rows = data_shape[0]
data_cols = data_shape[1]
norm=np.empty((data_rows,data_cols))
for i in range(data_cols):
norm[:,i]=(array[:,i]-mincols[i])/(maxcols[i]-mincols[i])
return norm
将数据归一化到(0, 1)之间,返回结果norm。
下面对特征样本集划分训练样本和测试样本。
划分方法:将每一种故障对应的100组特征的前50组划分为训练样本集,后面50组划分为测试样本集。
实现code如下:
#划分训练样本集和测试样本集,每一种故障有100个样本(9种故障一共900的样本),取每种故障的100的样本中的50个作为训练样本、剩下的50个作为测试样本
#给训练样本集和测试样本集打上标签
def Split_FeatureSamples900(FeatureSamples):
trainSum = np.zeros((50,8))
testSum = np.zeros((50,8))
for i in range(9):
Single_dir_Samples100 = Noralize_folder_allSamplefeatures[(i*100):(i+1)*100][:]
train = np.split(Single_dir_Samples100,2)[0] #分割为两部分,前一部分作为训练样本集
test = np.split(Single_dir_Samples100,2)[1] ##分割为两部分,后一部分作为测试样本集
trainSum = np.vstack((trainSum, train))
testSum = np.vstack((testSum, test))
trainSum_result = trainSum[50:500][:]
testSum_result = testSum[50:500][:]
return trainSum_result, testSum_result
至此,对故障数据集做特征提取并归一化的函数模块结束。
我们输入数据看结果:
filename = 'F:/Spyder/我的机器学习实战项目/3.Wavelet/Sumdata'
Folder_SamplesFeatures = Folder_SamplesFeatures(filename) #获取特征样本数据
Noralize_folder_allSamplefeatures= maxminnorm(Folder_SamplesFeatures) #归一化特征样本(0, 1)
trainsum_train, testsum_test = Split_FeatureSamples900(Noralize_folder_allSamplefeatures)
结果如图:
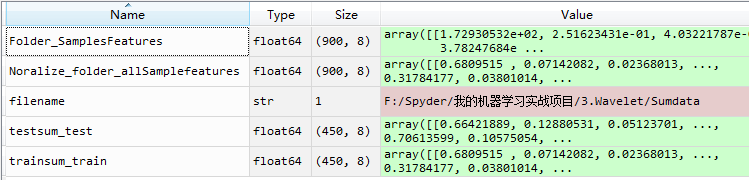
训练样本特征集结果:

测试样本特征集结果:

重要的事!!!走过路过不要错过!!!
MATLAB实现的源码如下,其中MATLAB中但故障训练样本集分为60组,即共有60 * 9 = 540组,测试样本集去除了第一个故障状态的数据,即共有40 *(9-1)=320组。
MATLAB运行结果如下:

完整的Python和MATLAB实现的源码见如下链接内容。
完整的Python实现源码和使用MATLAB实现的源码,可以对比学习,附有我的数据集,改变path路径可以直接运行得到结果。
