df1 = pd.DataFrame([['张三', 10, '男'],
['李四', 11, '男'],
['王五', 11, '女'],
['赵六', 10, '女'],
['王七', 11, '男'],
['Mike', 10, '男']],
columns=['name', 'age', 'sex'])
df1
df2 = pd.DataFrame([['Mike', 10, '男'],
['Jane', 11, '女'],
['张三', 10, '男']],
columns=['name', 'age', 'sex'])
df2 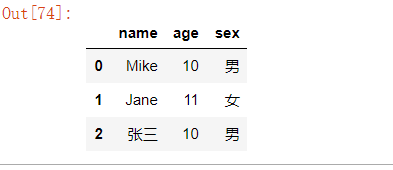
#取交集:
#pd.merge(df1,df2,on=['name', 'age', 'sex'],how='inner')
pd.merge(df1,df2,how='inner') 
#取并集
#pd.merge(df1,df2,on=['name', 'age', 'sex'],how='outer')
pd.merge(df1,df2,how='outer')

#取差集(从df1中过滤df2中存在的数据)
df1 = df1.append(df2)
df1 = df1.append(df2)
df1 = df1.drop_duplicates(subset=['name', 'age', 'sex'],keep=False)
df1
