关于redis的概念请见我上一篇博客
目录
一、redis主从复制

1、原理:
主从复制,指将一台Redis服务器(master)的数据,复制到其他的Redis服务器(slave)。前者称为主节点(master),后者称为从节点(slave),数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
原理图如下:

主从复制分类:
(1)、一主一从:用于主节点故障转移从节点,当主节点的“写”命令并发高且需要持久化,可以只在从节点开启AOF(主节点不需要),这样即保证了数据的安全性,也避免持久化对主节点的影响
(2)、一主多从:针对“读”较多的场景,“读”由多个从节点来分担,但节点越多,主节点同步到多节点的次数也越多,影响带宽,也加重主节点的稳定
(3)、树状主从:一主多从的缺点(主节点推送次数多压力大)可用些方案解决,主节点只推送一次数据到从节点B,再由从节点B推送到C,减轻主节点推送的压力。
4. 数据同步
redis 2.8版本以上使用psync命令完成同步,过程分“全量”与“部分”复制
全量复制:一般用于初次复制场景(第一次建立SLAVE后全量)
部分复制:网络出现问题,从节点再次连接主节点时,主节点补发缺少的数据,每次数据增量同步
心跳:主从有长连接心跳,主节点默认每10S向从节点发ping命令,repl-ping-slave-period控制发送频率
5. 主从的缺点
a)主从复制,若主节点出现问题,则不能提供服务,需要人工修改配置将从变主
b)主从复制主节点的写能力单机,能力有限
c)单机节点的存储能力也有限
6.主从故障如何故障转移
a)主节点(master)故障,从节点slave-1端执行 slaveof no one后变成新主节点;
b)其它的节点成为新主节点的从节点,并从新节点复制数据;
c)需要人工干预,无法实现高可用。

二、主从复制的实现
实验环境准备:
server1 172.25.58.1 redis主服务器
server2 172.25.58.2 redis从服务器
server3 172.25.58.3 redis从服务器
172.25.58.250 linux真机
1.编译安装redis,安装完会自动启动
获取redis包(目前使用5.0以上版本,为了后面的redis cluster)
在server1上进行安装:
注意安装redis之前要进行安装gcc
[root@server1 ~]# yum install gcc -y
tar zxf redis-5.0.3.tar.gz #在官网上下载好
cd /root/redis-5.0.3
make 编译
make install 安装
cd /root/redis-5.0.3/utils
./install_server.sh ##执行redis的安装脚本,安装完会自动启动
#使用脚本安装完毕,一直按回车即可netstat -tnlp 可以看到redis默认是开启127.0.0.1的6379端口,这样只能本地访问
[root@server1 utils]# netstat -tnlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 6425/redis-server 1
所以需要配置所有接口都能访问
vim /etc/redis/6379.conf ##修改端口
70 bind 0.0.0.02、重启服务
/etc/init.d/redis_6379 restart
也可以用systemctl restart redis_6379,但是重启好像不生效,可以开启服务注意:如果不提前安装gcc就会报错:说缺少gcc
/bin/sh: cc: command not found
make[1]: *** [adlist.o] Error 127
make[1]: Leaving directory `/root/redis-5.0.3/src'
make: *** [install] Error 2
3、使用redis-cli (redis命令行工具)进行测试
发现可以写入数据,查看数据,删除数据
注意:这里的数据是key-value形式,如果是同一个key的value,会进行覆盖
[root@server1 ~]# redis-cli
127.0.0.1:6379> set name yunyuzhu
OK
127.0.0.1:6379> get name
"yunyuzhu"
127.0.0.1:6379> get yunyuzhu
(nil)
127.0.0.1:6379> quit
2、在server2上安装reids
[root@server1 ~]# scp -r redis-5.0.3 [email protected]:/root
#在server2上安装
[root@server2 redis-5.0.3]# make install #由于已经make过了,直接进行安装即可
[root@server2 utils]# ./install_server.sh #执行安装脚本
3、配置从:在server2上配置从
[root@server2 ~]# vim /etc/redis/6379.conf
slaveof 172.25.58.1 6379 ##文件最后加
配置完文件重启redis
[root@server2 ~]# /etc/init.d/redis_6379 restart#测试:
在server1上:
[root@server1 ~]# redis-cli
127.0.0.1:6379> set name wsp
OK
127.0.0.1:6379> get name
"wsp"
在server2上:
[root@server2 ~]# redis-cli
127.0.0.1:6379> get name
"wsp"[结果说明]:就是实现主从数据库的同步
注意:server1上存入的值,在server2上可以看到,但是在server2上不能写入
说明:redis的数据保存在/var/lib/redis/6379/dump.rdb
如果有问题,redis起不来,可以删除这文件再试
[root@server1 ~]# cd /var/lib/redis/6379/
[root@server1 6379]# ls
dump.rdb
[root@server1 6379]# cat dump.rdb
REDIS0009� redis-ver5.0.3�
redis-bits�@�ctime��]used-mem�repl-stream-db��repl-id(3eb75fecbd1d8f9c6f9386f53c52c34a6838dbfe�
repl-offset��
aof-preamble���yyzzghnamyunyuzhu�=7�'#[roo[ro[[r[root@[可以参考redis中文官网http://www.redis.cn
http://www.redis.cn/documentation.html
redis配置文件参数说明:
vim /etc/redis/6379.conf
219 save 900 1 ##这几行表示,有一个键值发生变化时,会过900s更新,下面依次类推,因为不停更新会耗费资源
220 save 300 10
221 save 60 10000
分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改
先看60秒,如果有10000个更改,那就save了吧。
如果没有,那么等到300秒,看是否有10个更改,有就save了吧。
同理900秒。。。
redis的复制功能是支持多个数据库之间的数据同步。一类是主数据库(master)一类是从数据库(slave),
主数据库可以进行读写操作,当发生写操作的时候自动将数据同步到从数据库,而从数据库一般是只读的,
并接收主数据库同步过来的数据,一个主数据库可以有多个从数据库,而一个从数据库只能有一个主数据库。
从数据库的数据是以自己的主数据库为标准的
redis主从复制原理:
当一个从数据库启动后,会向主数据库发送SYNC命令,主数据库接收到SYNC命令后会开始在后台保存快照(即RDB持久化过程),并将保存期间接受到的命令缓存起来。当快照完成后,redis会将快照文件和所有缓存的命令发送给从数据库。从数据库收到后,会载入快照文件并执行收到的缓存命令。当主从数据库断开重连后会重新执行上述操作,不支持断点续传。
三、配置redis高可用(哨兵)
背景:
无论是主从模式,还是哨兵模式,这两个模式都有一个问题,不能水平扩容,并且这两个模式的高可用特性都会受到Master主节点内存的限制。还有一点,实现哨兵模式的配置也不简单,甚至可以说有些繁琐,所以在工业场景里这两个模式都不建议使用,如果要使用必须有相关的问题的解决方案,以免后续带来的问题。
1、哨兵作用和架构
哨兵主要作用:基于redis的主从复制,解决主节点故障恢复的自动化问题,进一步提高系统的高可用性。
在介绍哨兵之前,首先从宏观角度回顾一下 Redis 实现高可用相关的技术。
包括:持久化、复制、哨兵和集群,其主要作用和解决的问题是:
- 持久化:持久化是最简单的高可用方法(有时甚至不被归为高可用的手段),主要作用是数据备份,即将数据存储在硬盘,保证数据不会因进程退出而丢失。
- 复制:复制是高可用 Redis 的基础,哨兵和集群都是在复制基础上实现高可用的。
复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。
- 哨兵:在复制的基础上,哨兵实现了自动化的故障恢复。
- 缺陷:写操作无法负载均衡;存储能力受到单机的限制。
- 集群:通过集群,Redis 解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
下来我们再回到哨兵身上,Redis Sentinel,即 Redis 哨兵,在 Redis 2.8 版本开始引入。哨兵的核心功能是主节点的自动故障转移。
下面是 Redis 官方文档对于哨兵功能的描述:
- 监控(Monitoring):哨兵会不断地检查主节点和从节点是否运作正常。
- 自动故障转移(Automatic failover):当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点。
- 配置提供者(Configurationprovider):客户端在初始化时,通过连接哨兵来获得当前 Redis 服务的主节点地址。
- 通知(Notification):哨兵可以将故障转移的结果发送给客户端。
其中,监控和自动故障转移功能,使得哨兵可以及时发现主节点故障并完成转移;而配置提供者和通知功能,则需要在与客户端的交互中才能体现。
这里对“客户端”一词在本文的用法做一个说明:只要通过 API 访问 Redis 服务器,都会称作客户端,包括 redis-cli、Java 客户端 Jedis 等。
为了便于区分说明,本文中的客户端并不包括 redis-cli,而是比 redis-cli 更加复杂。
redis-cli 使用的是 Redis 提供的底层接口,而客户端则对这些接口、功能进行了封装,以便充分利用哨兵的配置提供者和通知功能。
哨兵的架构
典型的哨兵架构图如下所示:
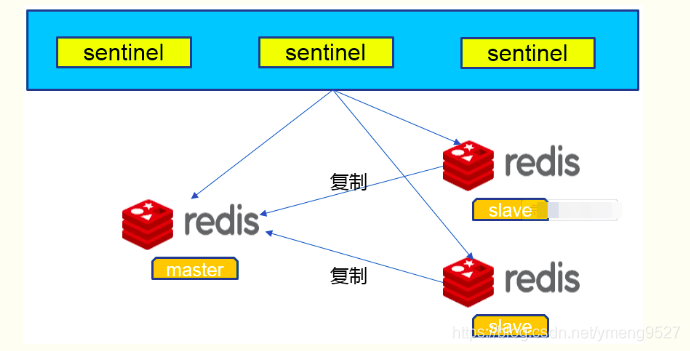
它由两部分组成,哨兵节点和数据节点:
- 哨兵节点:哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的 Redis 节点,不存储数据。
- 数据节点:主节点和从节点都是数据节点。
2、哨兵实现的基本原理
哨兵节点支持的命令
哨兵节点作为运行在特殊模式下的 Redis 节点,其支持的命令与普通的 Redis 节点不同。
在运维中,我们可以通过这些命令查询或修改哨兵系统;不过更重要的是,哨兵系统要实现故障发现、故障转移等各种功能,离不开哨兵节点之间的通信。
而通信的很大一部分是通过哨兵节点支持的命令来实现的。下面介绍哨兵节点支持的主要命令。
基础查询
通过这些命令,可以查询哨兵系统的拓扑结构、节点信息、配置信息等:
- info sentinel:获取监控的所有主节点的基本信息。
- sentinel masters:获取监控的所有主节点的详细信息。
- sentinel master mymaster:获取监控的主节点 mymaster 的详细信息。
- sentinel slaves mymaster:获取监控的主节点 mymaster 的从节点的详细信息。
- sentinel sentinels mymaster:获取监控的主节点 mymaster 的哨兵节点的详细信息。
- sentinel get-master-addr-by-name mymaster:获取监控的主节点 mymaster 的地址信息,前文已有介绍。
- sentinel is-master-down-by-addr:哨兵节点之间可以通过该命令询问主节点是否下线,从而对是否客观下线做出判断。
增加/移除对主节点的监控
sentinel monitor mymaster2 192.168.92.128 16379 2:与部署哨兵节点时配置文件中的 sentinel monitor 功能完全一样,不再详述。
sentinel remove mymaster2:取消当前哨兵节点对主节点 mymaster2 的监控。
强制故障转移
sentinel failover mymaster:该命令可以强制对 mymaster 执行故障转移,即便当前的主节点运行完好。
例如,如果当前主节点所在机器即将报废,便可以提前通过failover命令进行故障转移。
基本原理
关于哨兵的原理,关键是了解以下几个概念。
定时任务
每个哨兵节点维护了 3 个定时任务,定时任务的功能分别如下:
- 通过向主从节点发送 info 命令获取的主从结构。
- 通过发布订阅功能获取其他哨兵节点的信息。
- 通过向其他节点发送 ping 命令进行心跳检测,判断是否下线。
主观下线
在心跳检测的定时任务中,如果其他节点超过一定时间没有回复,哨兵节点就会将其进行主观下线。
顾名思义,主观下线的意思是一个哨兵节点“主观地”判断下线;与主观下线相对应的是客观下线。
客观下线
哨兵节点在对主节点进行主观下线后,会通过 sentinelis-master-down-by-addr 命令询问其他哨兵节点该主节点的状态。
如果判断主节点下线的哨兵数量达到一定数值,则对该主节点进行客观下线。
需要特别注意的是,客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。
选举哨兵节点
当主节点被判断客观下线以后,各个哨兵节点会进行协商,选举出一个哨兵节点,并由该节点对其进行故障转移操作。
监视该主节点的所有哨兵都有可能被选为,选举使用的算法是 Raft 算法。
Raft 算法的基本思路是先到先得:即在一轮选举中,哨兵 A 向 B 发送成为哨兵节点的申请,如果 B 没有同意过其他哨兵,则会同意 A 成为哨兵节点。
选举的具体过程这里不做详细描述,一般来说,哨兵选择的过程很快,谁先完成客观下线,一般就能成为***。
故障转移
选举出的哨兵,开始进行故障转移操作,该操作大体可以分为 3 个步骤:
- 在从节点中选择新的主节点:选择的原则是,首先过滤掉不健康的从节点,然后选择优先级***的从节点(由 slave-priority 指定)。
如果优先级无法区分,则选择复制偏移量***的从节点;如果仍无法区分,则选择 runid 最小的从节点。
- 更新主从状态:通过 slaveof no one 命令,让选出来的从节点成为主节点;并通过 slaveof 命令让其他节点成为其从节点。
- 将已经下线的主节点(即 6379)设置为新的主节点的从节点,当 6379 重新上线后,它会成为新的主节点的从节点。
通过上述几个关键概念,可以基本了解哨兵的工作原理。
3、哨兵的具体实现如下:
在redis的主从复制模式中,设置了一主一从,在哨兵模式中再添加一台虚拟机server3
先将server3的redis的环境配置好,为了方便起见,我们将server1的解压目录上传到server3上。
进行编译安装,打开服务。
同样的,修改监听的ip为所有,并在配置文件添加从服务器的主服务器的ip、端口。
测试主从同步是否成功。
server3的配置:
[root@server1 ~]# scp -r redis-5.0.3 [email protected]:/root
#再开一台server3,配置redis,本篇博客开始已经有涉及
[root@server3 redis-5.0.3]# make install #安装
[root@server3 utils]# ./install_server.sh #执行脚本尽行安装
[root@server3 redis]# vim 6379.conf
70 bind 0.0.0.0
89 protected-mode no #顺便关闭server3的保护模式
1379 slaveof 172.25.58.1 6379 #最后一行添加
#开启主从模式
[root@server3 redis]# /etc/init.d/redis_6379 restart
[root@server3 utils]# netstat -antlp #查看6379端口是否开启
测试
[root@server3 utils]# redis-cli
127.0.0.1:6379> get yyz
"zgh"到此为止,已经实现了一主(server1)二从(server2、server3)的主从复制
接下来实现哨兵模式
也就是master坏了,从master的所有slave中选举出一个新的master出来
配置哨兵
在server1上(master)编辑配置文件
#复制master上的配置哨兵的文件,然后进行配置
[root@server1 redis-5.0.3]# pwd
/root/redis-5.0.3
[root@server1 redis-5.0.3]# cp sentinel.conf /etc/redis/
[root@server1 ~]# vim /etc/redis/sentinel.conf
17 protected-mode no ##关闭保护模式
84 sentinel monitor mymaster 172.25.58.1 6379 2
113 sentinel down-after-milliseconds mymaster 10000
84行##配置master信息,后面的2表示投票机制,至少有2个节点认为master挂了,才会切换
# 在此,由于有两个slave节点,所以,在此投票机制,设置为2即可,应用的话是情况而定
121行##改为10s,表示master挂后10s会切换
注意:如果启动过哨兵,对应的行数,可能会有所变化~~~
【配置文件解析】
#84 Sentinel监听的master地址,第一个参数是给master起的名字(mymaster),第二个参数为master IP,第三个为master的redis端口,第四个为当该master挂了的时候,若想将该master判为失效,在Sentine集群中必须至少2个Sentine同意才行,只要该数量不达标,则就不会发生故障迁移。
也就是说只要有2个sentinel认为master下线,就认为该master客观下线,
启动failover并选举产生新的master。通常最后一个参数不能多于启动的sentinel实例数。
这个配置是sentinel需要监控的master/slaver信息,格式为sentinel monitor
其中应该小于集群中slave的个数,当失效的节点数超过了,则认为整个体系结构失效
不过要注意, 无论你设置要多少个 Sentinel 同意才能判断一个服务器失效,
一个 Sentinel 都需要获得系统中多数(majority) Sentinel 的支持, 才能发起一次自动故障迁移,
并预留一个给定的配置纪元 (configuration Epoch ,一个配置纪元就是一个新主服务器配置的版本号)。
换句话说, 在只有少数(minority) Sentinel 进程正常运作的情况下, Sentinel 是不能执行自动故障迁移的。
注意:一定要先scp到slave节点上再启动(因为开启哨兵后,就会产生一些文件信息)
[root@server1 redis]# scp sentinel.conf server2:/etc/redis/
[root@server1 redis]# scp sentinel.conf server3:/etc/redis/
[root@server1 ~]# redis-server /etc/redis/sentinel.conf --sentinel ##开启哨兵
#在server2和server3上同样要开启
[root@server2 ~]# redis-server /etc/redis/sentinel.conf --sentinel
[root@server3 ~]# redis-server /etc/redis/sentinel.conf --sentinel
记得写本地解析哦~~~~
在server1上查看端口,26379端口
[root@server1 redis]# netstat -antlp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 976/redis-server 0.
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 615/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 864/master
tcp 0 0 172.25.58.1:26379 172.25.58.2:49682 TIME_WAIT -
tcp 0 0 172.25.58.1:22 172.25.58.250:46316 ESTABLISHED 2056/sshd: root@pts
接下来模拟哨兵:
由于server1终端已经在开启哨兵模式,此时在真机上重新ssh一个server1:
[root@foundation58 kiosk]# ssh [email protected]
[email protected]'s password:
Last login: Fri Dec 6 03:08:09 2019 from 172.25.58.250
####server1上可以看到sentinel信息#######
[root@server1 ~]# redis-cli
127.0.0.1:6379> info
# Server
redis_version:5.0.3
# Replication
role:master
connected_slaves:2
slave0:ip=172.25.58.2,port=6379,state=online,offset=107618,lag=0
slave1:ip=172.25.58.3,port=6379,state=online,offset=107755,lag=0
看到上面信息说明配置成功~~~~~~
#挂掉server1的redis
[root@server1 ~]# redis-cli
127.0.0.1:6379> SHUTDOWN
not connected>1、查看进程(ps ax | grep redis)可以看到server1的redis-server进程已经关闭
但是server1的redis-sentinel进程依然正常运行,可以参加选举
[root@server1 ~]# ps ax | grep redis
2150 pts/0 Sl+ 0:00 redis-server *:26379 [sentinel]
2174 pts/1 S+ 0:00 grep --color=auto redis
2、在server2上可以看到将master由server1切换为server3,并且可以看到投票结果
2373:X 06 Dec 2019 04:16:52.874 # +odown master mymaster 172.25.58.1 6379 #quorum 3/2
2373:X 06 Dec 2019 04:16:52.874 # +new-epoch 1
2373:X 06 Dec 2019 04:16:52.874 # +try-failover master mymaster 172.25.58.1 6379
2373:X 06 Dec 2019 04:16:52.877 # +vote-for-leader 5e54555fe753571c0b3e9d93672b23505271c3ae 1
2373:X 06 Dec 2019 04:16:52.884 # b159bb5adb6f45f4fd59ec3d2549695792ab6bcb voted for 5e54555fe753571c0b3e9d93672b23505271c3ae 1
2373:X 06 Dec 2019 04:16:52.885 # 3404799b67c25eb7b43c59d0d5b56a33408b20fe voted for 5e54555fe753571c0b3e9d93672b23505271c3ae 1
2373:X 06 Dec 2019 04:16:52.932 # +elected-leader master mymaster 172.25.58.1 6379
2373:X 06 Dec 2019 04:16:52.932 # +failover-state-select-slave master mymaster 172.25.58.1 6379
2373:X 06 Dec 2019 04:16:52.998 # +selected-slave slave 172.25.58.3:6379 172.25.58.3 6379 @ mymaster 172.25.58.1 6379
2373:X 06 Dec 2019 04:16:52.998 * +failover-state-send-slaveof-noone slave 172.25.58.3:6379 172.25.58.3 6379 @ mymaster 172.25.58.1 6379
2373:X 06 Dec 2019 04:16:53.089 * +failover-state-wait-promotion slave 172.25.58.3:6379 172.25.58.3 6379 @ mymaster 172.25.58.1 6379
2373:X 06 Dec 2019 04:16:53.746 # +promoted-slave slave 172.25.58.3:6379 172.25.58.3 6379 @ mymaster 172.25.58.1 6379
2373:X 06 Dec 2019 04:16:53.746 # +failover-state-reconf-slaves master mymaster 172.25.58.1 6379
2373:X 06 Dec 2019 04:16:53.809 # +failover-end master mymaster 172.25.58.1 6379
2373:X 06 Dec 2019 04:16:53.809 # +switch-master mymaster 172.25.58.1 6379 172.25.58.3 6379
2373:X 06 Dec 2019 04:16:53.809 * +slave slave 172.25.58.2:6379 172.25.58.2 6379 @ mymaster 172.25.58.3 6379
2373:X 06 Dec 2019 04:16:53.809 * +slave slave 172.25.58.1:6379 172.25.58.1 6379 @ mymaster 172.25.58.3 6379
2373:X 06 Dec 2019 04:17:03.829 # +sdown slave 172.25.58.2:6379 172.25.58.2 6379 @ mymaster 172.25.58.3 6379
2373:X 06 Dec 2019 04:17:03.829 # +sdown slave 172.25.58.1:6379 172.25.58.1 6379 @ mymaster 172.25.58.3 63793、在server1上使用命令远程登陆(redis-cli -h 172.25.58.2)redis集群中的server2,可以看到
server3是master,server2是slave
2373:X 06 Dec 2019 04:17:03.829 # +sdown slave 172.25.58.1:6379 172.25.58.1 6379 @ mymaster 172.25.58.3 63794、在此查看sentinel.conf,文件,可以看到当我们开启sentinel模式后,在文件末尾会产生 相关的内容,如果我们在sentinel模式开启后发送文件,配置文件会有问题。当然读者也可以自己重新配置文件。
sentinel leader-epoch mymaster 1
sentinel known-replica mymaster 172.25.58.2 6379
sentinel known-replica mymaster 172.25.58.1 6379
sentinel known-sentinel mymaster 172.25.58.1 26379 3404799b67c25eb7b43c59d0d5b56a33408b20fe
sentinel known-sentinel mymaster 172.25.58.2 26379 5e54555fe753571c0b3e9d93672b23505271c3ae
sentinel current-epoch 1
5、编辑redis的配置文件,发现已经恢复为原来的样子
已经没有了master信息
此时vim /etc/redis/6379.conf 手动添加上master的如下信息:
replicaof 172.25.58.3 6379 #加到最后一行5、重启server1上的redis服务 /etc/init.d/redis_6379 restart 或者 systemctl restart redis
6、查看进程,已经恢复好了 ps ax
注意:
这里为什么要我们手动去把server1变为slave,而不是选举完之后直接将master置为slave?
因为server1原来是master,上面会有重要的数据,而且它的slave节点server2和server3上的数据有可能不完全和server1同步
如果这个时候直接将server1置为slave的话,它会以新的master节点作为参考,丢弃原来的所有数据
这时候就有可能造成严重的数据丢失
7、测试:登陆server2,新的master
进行查询所有的key:(可以看到,在master上之前设置的都存在,没有丢失)
127.0.0.1:6379> keys *
1) "123"
2) "lsm"
3) "yyz"
4) "name"8、可以看到server2是master节点,server1和server3是slave节点
同时数据依然存在,保留在我们集群中的每一个节点之上
127.0.0.1:6379> keys *
1) "123"
2) "lsm"
3) "yyz"
4) "name"可以看到server1的6379端口挂掉
sentinel哨兵也能看到信息
redis常用基础命令 (这是一个链接)
1036:X 31 Mar 2019 17:49:21.927 # +odown master mymaster 172.25.58.1 6379 #quorum 3/2
1036:X 31 Mar 2019 17:49:22.546 # +switch-master mymaster 172.25.58.1 6379 172.25.58.2 6379总结来说,故障转移分为三个步骤:
1)从下线的主服务的所有从服务里面挑选一个从服务,将其转成主服务
sentinel状态数据结构中保存了主服务的所有从服务信息,领头sentinel按照如下的规则从从服务列表中挑选出新的主服务;
删除列表中处于下线状态的从服务;删除最近5秒没有回复过领头sentinel info信息的从服务;
删除与已下线的主服务断开连接时间超过 down-after-milliseconds*10毫秒的从服务,
这样就能保留从的数据比较新(没有过早的与主断开连接);
领头sentinel从剩下的从列表中选择优先级高的,如果优先级一样,选择偏移量最大的(偏移量大说明复制的数据比较新),
如果偏移量一样,选择运行id最小的从服务。
2)已下线主服务的所有从服务改为复制新的主服务
挑选出新的主服务之后,领头sentinel 向原主服务的从服务发送 slaveof 新主服务 的命令,复制新master。
3)将已下线的主服务设置成新的主服务的从服务,当其回复正常时,复制新的主服务,变成新的主服务的从服务
同理,当已下线的服务重新上线时,sentinel会向其发送slaveof命令,让其成为新主的从。
温馨提示:还可以向任意sentinel发生sentinel failover <masterName> 进行手动故障转移,这样就不需要经过上述主客观和选举的过程。
