给你一个方程,左边用 words 表示,右边用 result 表示。
你需要根据以下规则检查方程是否可解:
- 每个字符都会被解码成一位数字(0 - 9)。
- 每对不同的字符必须映射到不同的数字。
- 每个
words[i]和result都会被解码成一个没有前导零的数字。 - 左侧数字之和(
words)等于右侧数字(result)。
如果方程可解,返回 True,否则返回 False。
示例 1:
输入:words = ["SEND","MORE"], result = "MONEY"
输出:true
解释:映射 'S'-> 9, 'E'->5, 'N'->6, 'D'->7, 'M'->1, 'O'->0, 'R'->8, 'Y'->'2'
所以 "SEND" + "MORE" = "MONEY" , 9567 + 1085 = 10652
示例 2:
输入:words = ["SIX","SEVEN","SEVEN"], result = "TWENTY"
输出:true
解释:映射 'S'-> 6, 'I'->5, 'X'->0, 'E'->8, 'V'->7, 'N'->2, 'T'->1, 'W'->'3', 'Y'->4
所以 "SIX" + "SEVEN" + "SEVEN" = "TWENTY" , 650 + 68782 + 68782 = 138214
示例 3:
输入:words = ["THIS","IS","TOO"], result = "FUNNY"
输出:true
示例 4:
输入:words = ["LEET","CODE"], result = "POINT"
输出:false
提示:
2 <= words.length <= 51 <= words[i].length, results.length <= 7words[i], result只含有大写英文字母- 表达式中使用的不同字符数最大为 10
解题思路
首先思考最暴力的解法,也就是枚举出现字符的全排列,然后尝试每种排列的做法是否可行。
from itertools import permutations
from collections import defaultdict
class Solution:
def isSolvable(self, words: List[str], result: str) -> bool:
U = set(result)
for word in words:
U |= set(word)
U_len, U_list = len(U), list(U)
for p in permutations(range(10), U_len):
chat2digit = defaultdict(int) # 字符数字映射表
for i in range(U_len):
chat2digit[U_list[i]] = p[i]
if chat2digit[result[0]] == 0:
continue
l, r = 0, 0 # l:words对应和 r:result对应值
for i in result:
r = r * 10 + chat2digit[i]
for word in words:
if chat2digit[word[0]] == 0:
break
t = 0
for i in word:
t = t * 10 + chat2digit[i]
l += t
else:
if l == r:
return True
return False
这种写法的时间复杂度是5*7*10!=127008000,使用cpp可能能过,但是用python肯定过不去,那么需要优化。我们首先需要将上面的代码写成递归回溯的形式,可以式子写成如下形式。
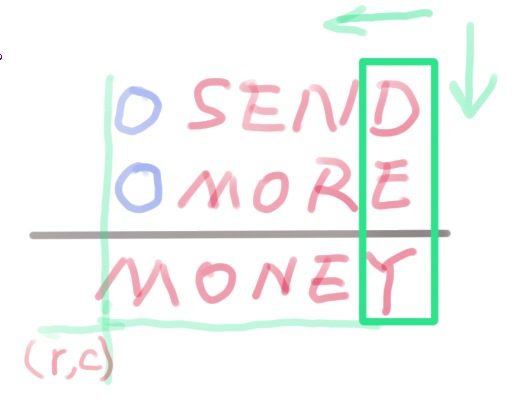
有一点可以确定,结果字符串的长度一定是最长的(如果不是,那么返回False)。以结果字符串的长度作为标准,其他字符串的左侧补0。我们可以从右上侧开始枚举每个字符可能对应的数字,那么此时这个问题就变成了Leetcode 2:两数相加(最详细解决方案!!!)。
我们可以将上面的算式看成是矩阵,然后通过dfs从右上向左下遍历矩阵。考虑边界问题,对于每一列来说,当遍历到最后一行的时候,我们需要计算这一列的和sums。这里有一个剪枝条件,就是如果当前字符串已经在映射表中了,但是此时sum%10和表中对应的映射值不同,显然我们就可以终止了。另一个边界就是遍历到最后一列)了,此时如果还有进位的话,肯定就不对了。
class Solution:
def isSolvable(self, words: List[str], result: str) -> bool:
allWords = words + [result]
firstChars = set(word[0] for word in allWords if len(word) > 1)
n = max(map(len, allWords)) # 最长字符串长度
if len(result) < n:
return False
def dfs(r, c, carry, vis, char2digit):
"""
r: 行
c: 列
carry: 进位
vis: 记录哪些数字使用过
char2digit: 字符数字映射
"""
if c == n: # 枚举到result的最后一个字符
return carry == 0
if r == len(allWords): # 枚举到最后一行
sums = sum(char2digit[word[-c - 1]] if c < len(word) else 0 for word in words) + carry # 计算当前列的和
if sums % 10 != char2digit[result[-c - 1]]:
return False
return dfs(0, c + 1, sums // 10, vis, char2digit)
if (r < len(words) and c >= len(words[r])): # 当前行的字符串太短,枚举下一行
return dfs(r + 1, c, carry, vis, char2digit)
cur = allWords[r][-c-1] # 当前遍历到的字符
if cur in char2digit: # 或当前字符之前出现过
return dfs(r + 1, c, carry, vis, char2digit)
if cur not in char2digit: # 当前字符之前没有出现
firstDigit = 1 if cur in firstChars else 0
for i in range(firstDigit, 10):
if i not in vis:
char2digit[cur] = i
vis.add(i)
if dfs(r + 1, c, carry, vis, char2digit.copy()):
return True
vis.remove(i)
return False
return dfs(0, 0, 0, set(), {})
虽然可以解决问题,但是这个代码的效率很低。这个问题还有一种思考方式,可以将字符串看成一个变量,例如:
SEND = S*1000 + E*100 + N*10 + D
MORE = M*1000 + O*100 + R*10 + E
MONEY = M*10000 + O*1000 + N*100 + E*10 + Y
由于SEND+MORE=MONEY,那么可以转化为S*1000-M*9000+E*91-O*900-N*90+R*10+D-Y=0。那么现在的工作就变成了,枚举1~9之间的数使得上述方程成立即可。
class Solution:
def isSolvable(self, words: List[str], result: str) -> bool:
dic = collections.defaultdict(int)
for word in words:
for i, c in enumerate(word[::-1]):
dic[c] += 10 ** i
for i, c in enumerate(result[::-1]):
dic[c] -= 10 ** i
eq = sorted(dic.items(), key=lambda x: -abs(x[1]))
ch, rat = zip(*eq)
firstChars = {word[0] for word in words + [result]}
def dfs(u, vis, sums):
if u == len(rat):
return sums == 0
firstDigit = 1 if ch[u] in firstChars else 0
for i in range(firstDigit, 10):
if i not in vis:
vis.add(i)
if dfs(u + 1, vis, sums + rat[u] * i):
return True
vis.remove(i)
return dfs(0, set(), 0)
但是这么做会超时。那么需要剪枝!剪枝!剪枝!
这里的剪枝思路比较特别,因为我们已经将问题转化为了方程,那么方程左边的值的范围是可以确定的。如何确定呢?左边的值范围在[l,r]之间,那么对于l其实就是将系数中的负数乘上较大的数而正数乘上较小的数得到,采用同样的思路可以得到r。当方程中的一个变量确定的时候,此时[l,r]的区间会随之减小。根据这个原理我们可以估算出左边值的取值范围。
class Solution:
def isSolvable(self, words: List[str], result: str) -> bool:
dic = collections.defaultdict(int)
for word in words:
for i, c in enumerate(word[::-1]):
dic[c] += 10 ** i
for i, c in enumerate(result[::-1]):
dic[c] -= 10 ** i
eq = sorted(dic.items(), key=lambda x: -abs(x[1]))
ch, rat = zip(*eq)
firstChars = {word[0] for word in words + [result]}
suf_min, suf_max = [], []
for i in range(len(rat)): # 计算左边值的范围
pos_rat = [c for c in rat[i:] if c > 0]
neg_rat = [c for c in rat[i:] if c < 0]
suf_max.append(
sum(p * v for p, v in zip(pos_rat, range(10)[::-1])) +
sum(n * v for n, v in zip(neg_rat, range(10)))
)
suf_min.append(
sum(p * v for p, v in zip(pos_rat, range(10))) +
sum(n * v for n, v in zip(neg_rat, range(10)[::-1]))
)
def dfs(u, vis, sums):
"""
u: 当前系数的下表
vis: 表示哪些数使用过
sums: 计算当前和
"""
if u == len(rat):
return sums == 0
if not (suf_min[u] <= -sums <= suf_max[u]): # 注意是-sums
return False
firstDigit = 1 if ch[u] in firstChars else 0
for i in range(firstDigit, 10):
if i not in vis:
vis.add(i)
if dfs(u + 1, vis, sums + rat[u] * i):
return True
vis.remove(i)
return dfs(0, set(), 0)
这个代码的效率很高,非常优秀!!!
我将该问题的其他语言版本添加到了我的GitHub Leetcode
如有问题,希望大家指出!!!
