zookeeper到底是什么?
zookeeper实际上是yahoo开发的,用于分布式中一致性处理的框架。最初其作为研发Hadoop时的副产品。由于分布式系统中一致性处理较为困难,其他的分布式系统没有必要 费劲重复造轮子,故随后的分布式系统中大量应用了zookeeper,以至于zookeeper成为了各种分布式系统的基础组件,其地位之重要,可想而知。著名的hadoop、kafka、dubbo 都是基于zookeeper而构建。
zookeeper的一致性:
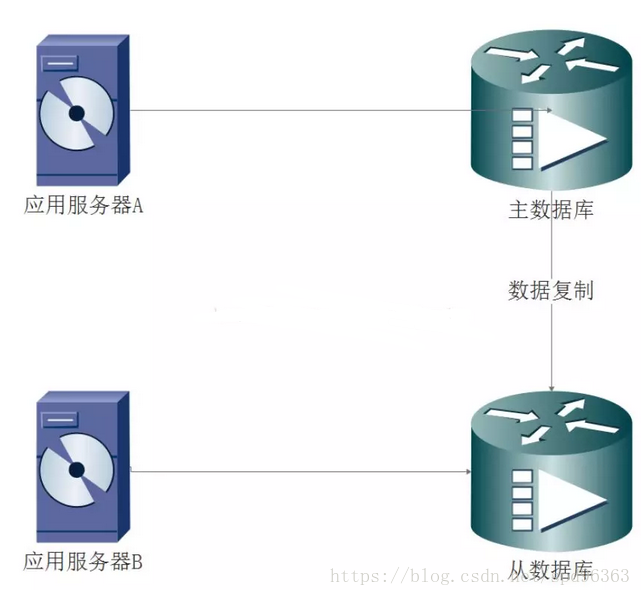
所谓的一致性,实际上就是围绕着“看见”来的。谁能看见?能否看见?什么时候看见?举个例子:淘宝后台卖家,在后台上架一件大促的商品,通过服务器A提交到主数据库,假设刚提交后立马就有用户去通过应用服务器B去从数据库查询该商品,就会出现一个现象,卖家已经更新成功了,然而买家却看不到;而经过一段时间后,主数据库的数据同步到了从数据库,买家就能查到了。
假设卖家更新成功之后买家立马就能看到卖家的更新,则称为强一致性;
如果卖家更新成功后买家不能看到卖家更新的内容,则称为弱一致性;
而卖家更新成功后,买家经过一段时间最终能看到卖家的更新,则称为最终一致性。
如果要给一致性下个定义,可以是分布式系统中状态或数据保持同步和一致。特别需要注意一致性跟事务的区别,可以记得学习数据库时特别强调ACID,故而满足ACID的数据库能够做事务,其中C即是一致性,因此,事务是一致性的一种特例,比起一致性更难达成。
一些常见的解决一致性问题的方式:
查询重试补偿。对于分布式应用中不确定的情况,先使用查询接口查询到当前状态,如果当前状态不一致则采用补偿接口对状态进行重试推进,或者回滚接口对业务做回滚。典型的场景如银行跟支付宝之间的交互。支付宝发送一个转账请求到银行,如一直未收到响应,则可以通过银行的查询接口查询该笔交易的状态,如该笔交易对方未收到,则采取补偿的模式进行推送。
定时任务推送。对于上面的情况,有可能一次推送搞不定,于是需要2次,3次推送。不要怀疑,支付宝内最初掉单率很高,全靠后续不断的定时任务推送增加成功率。
TCC。try-confirm-cancel。实际上是两阶段协议,第二阶段的可以实现提交操作或是逆操作。
zookeeper到底能做什么?
在业界的实际应用是什么?了解这些应用,会对zookeeper能够做的事有更直观的认识。
hadoop
鼻祖级应用,ResourceManager(资源管理器)在整个hadoop中算是单点,为了实现其高可用,分为主备ResourceManager,zookeeper在其中管理整个ResourceManager。
可以想象,主备ResourceManager最初是主RM提供服务,如果一切安好,则zookeeper无用武之地。然而,总归会出现主RM提供不了服务的情况。于是会出现主备切换的情况,而zookeeper正是为主备切换保驾护航。
传统的主备切换,可以让主备之间维持心跳连接,一旦备机发现主机心跳检测不到了,则自己切换为主机,原来的主机等待救援。这种方式有两个问题,一是由于网络抖动,负载过大等问题,备机检测不到心跳并不能说明主机一定挂了,有可能一定时间后主机或网络恢复,这时候主机并不知道备机已经切换为主机,两台主机互相争用,可能造成脑裂;二是如果一些数据集中在主机上面,则备机切换时由于同步延时势必会损失掉一部分的数据。
如何解决这些问题?早期的方式提供了不少解决方案,比如备机一旦切换为主机,则通过电源控制直接切断主机电源,简单粗暴,但是此刻备机已经是单点,如果主机是因为量撑不住而挂,那备机有可能会重蹈覆辙,最终导致整个服务不可用。
zookeeper又是如何解决这个问题的呢?
zookeeper作为第三方集群参与到主备节点中去,当主备启动时会在zookeeper上竞争创建一个临时锁节点,争用成功者则充当主机,其余备机;
所有备机会监听该临时锁节点,一旦主机与zookeeper间session失效,则临时节点被删除;
一旦临时节点被删除,备机开始重新申请创建临时锁节点,重新争用为主机;
用zookeeper如何解决脑裂?实际上主机争用到节点后通过对根节点做一个ACL权限控制,则其他抢占的机器由于无法更新临时锁节点,只有放弃成为备机。
zookeeper使用了非常简单又现成的方式来解决的这个问题,比起其他方案方便不少,这也是为啥zookeeper流行的原因。说白了,就是把复杂操作封装化精简化。
dubbo
作为业界知名的分布式SOA框架,dubbo的主要的服务注册发现功能便是由zookeeper来提供的。
对于一个服务框架,注册中心是其核心中的核心,虽然暂时挂掉并不会导致整个服务出问题,但是一旦挂掉,整体风险就很高。考虑一般情况,注册中心就是单台机器的时候,其实现很容易,所有机器起来都去注册服务给它,并且所有调用方都跟它保持长连接,一旦服务有变,即通过长连接来通知到调用方。但是当服务集群规模扩大时,这事情就不简单了,单机保持连接数有限,而且容易故障。
作为一个稳定的服务化框架,dubbo可以选择并推荐zookeeper作为注册中心。其底层将zookeeper常用的客户端zkclient和curator封装成为ZookeeperClient。
当服务提供者服务启动时,向zookeeper注册一个节点;
服务消费者则订阅其父节点的变化,诸如启动停止都能够通过节点创建删除得知,异常情况比如被调用方掉线也可以通过临时节点session 断开自动删除得知;
服务消费方同时也会将自己订阅的服务以节点创建的方式放到zookeeper;
于是可以得到映射关系,诸如谁提供了服务,谁订阅了谁提供的服务,基于这层关系再做监控,就能轻易得知整个系统情况。
zookeeper的基本数据模型
一句话,类似Linux文件系统的节点模型
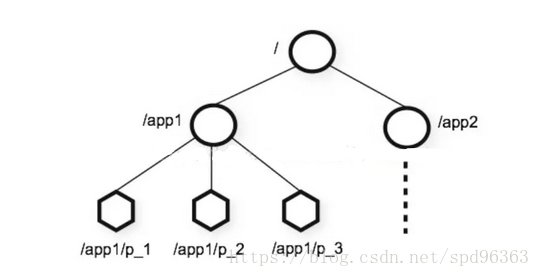
其节点有如下有趣而又重要的特性:
同一时刻多台机器创建同一个节点,只有一个会争抢成功。利用这个特性可以做分布式锁。
临时节点的生命周期与会话一致,会话关闭则临时节点删除。这个特性经常用来做心跳,动态监控,负载等动作。
顺序节点保证节点名全局唯一。这个特性可以用来生成分布式环境下的全局自增长id。
通过zookeeper提供的原语服务,可以对zookeeper能做的事情有个精确和直观的认识。
zookeeper提供的原语服务
创建节点
删除节点
更新节点
获取节点信息
权限控制
事件监听
实际上,就是对节点的增删查改加上权限控制与事件监听,但是通过对这些原语的组合以及不同场景的使用,可以实现很多用法。
数据发布订阅。即注册中心,见上面dubbo用法。主要通过对节点管理做到发布以及事件监听做到订阅。
负载均衡。见上面kafka用法。
命名服务。zookeeper的节点结构天然支持命名服务,即把信息集中存储,并以树状管理,方便统一查阅。
分布式协调通知。协调通知实际上与发布订阅类似,由于引入的第三方的zookeeper,实际上对很多种协调通知做了解耦,比如参考文献4中提到的消息推送,心跳检测等。
集群管理与master选举。通过上面的第二点特性,可以轻易得知集群机器存活状况,从而轻松管理集群;通过上面第一点特性,可以做出master争抢。
分布式锁。实际上就是第一点特性的应用。
分布式队列。实际上就是第三点特性的应用。
分布式的并发等待。类似于多线程的join问题,主任务的执行依赖于其他子任务全部执行完毕,在单机多线程里可以用join,但是分布式环境下如何实现呢。利用zookeeper,可以创建一个主任务节点,旗下子任务一旦执行完毕,则在主任务节点下挂一个子任务节点,等节点数量足够,则认为主任务可以开始执行。
可以发现,所有的原语就是zookeeper的基础,而其他的用法总结无非是将原语放到不同场景下的归类。