SegNet
Demo: http://mi.eng.cam.ac.uk/projects/segnet/
Last Edited: May 09, 2019 5:18 PM
Tags: FCN,SegNet
论文地址: https://arxiv.org/pdf/1511.00561.pdf
前言
可以看看官网的演示效果:SegNet
或者是直接看看这个演示效果:https://youtu.be/CxanE_W46ts

SegNet的主要动机是场景理解的应用(语义分割),主要动机是为了设计一个Memory and Computational Time均高效的网络结构用于道路和室内场景理解。
设计的最初目的就是为了从解决语义分割后边界精确定位的问题。
定量的评估表明,SegNet在和其他架构的比较上,时间和内存的使用都比较高效。
模型对比分析
Pascal VOC 12的偏向性
- 数据集中大部分图都有一两个由高度多样的背景包围的前景。
- 隐含地导致其偏向于含有检测技术的算法。
不同分割论文解码方法总结
- Decoupled,用大量弱标签数据进行分类网络的训练,使得分割网络性能得到改善。
- DeepLab,使用分类网络的特征图和独立的CRF后处理技术来执行分割。
- DeconvNet、Edge Boxes,使用区域proposals,通过额外的推理辅助来增强分割网络的性能。
因此,上面这些算法,它们与场景理解的不同之处在于,他们的目的是利用对象的共同出现( co-occurrences of objects—CRF)以及其他空间上下文(other spatial-context—proposal)来执行可靠的分割。
提出原因
多尺度的深层架构也被广泛采用。它们有两种风格,(1)使用几个尺度的输入图像和相应的深度特征提取网络;(2)组合来自单个深层结构的不同层的特征图(ParseNet)。
通常的想法是提取多尺度特征来提供局部和全局的空间信息(zoom-out),再利用浅层编码层的特征图以保留更高频率的细节,从而获得更细致的类别边界。其中一些架构由于参数太多而难以训练。因此,多阶段训练往往也需要数据增强。由于特征是从多个卷积路径提取的,导致推理过程也是复杂度比较高的。还有的团队在多尺度网络后附加CRF,并共同训练。然而,这个步骤在测试时不是前馈的,需要优化才能确定MAP标签。
介绍
网络结构

我们可以看到是一个对称网络,由中间绿色Pooling层与红色Upsampling层作为分割,左边是卷积提取高维特征,并通过Pooling使图片变小,SegNet作者称该过程为Encoder,右边是反卷积(在这里反卷积与卷积没有区别)与Upsampling,通过反卷积使得图像分类后特征得以重现,Upsampling使图像变大,SegNet作者称该过程为Decoder,最后通过Softmax,输出不同分类的最大值。
SegNet高效的原因是因为仅仅保留了MaxPooling的结果,并没有保留卷积后的产物,因此非常节省内存。
对比VGG-16
- 编码网络和VGG-16的卷积层相同。
- 移除了全连接层。
- 解码器使用从相应的编码器接受的Max-Pooling Indices来进行输入特征图的非线性Upsampling。
使用max-pooling indices的原因
Max-Pooling可以实现在输入图像上进行小的空间位移时保持平移不变性。然而,连续的下采样导致了在输出的特征图上,每一个像素都重叠着着大量的输入图像中的空间信息。对于图像分类任务,多层最大池化Max-Pooling和下采样由于平移不变性可以获得较好的鲁棒性,但导致了特征图大小和空间信息的损失。图像分割任务中边界划分至关重要,而这么多有损边界细节的图像表示方法显然不利于分割。因此,在进行下采样之前,在编码器特征映射中获取和存储边界信息是十分重要的。如果推理过程中的内存不受约束,则所有编码器特征映射(在下采样后)都可以存储。在实际应用中,情况通常不是这样,因此我们提出了一种更有效的方法来存储这些信息——只存储最大池化索引,即存储每个池化窗口中最大特征值的位置,用于每个编码器特征映射。
基于VGG16的对称网络结构,网络把全卷积层去掉了,这样就可实现end-to-end的训练,节省计算时间。论文中提到如果把encoder卷积层的信息加入到decoder中会提高准确率,但是运算消耗增加,因此作者并没有这么做,采用了一种Unpooling的方法,如下图:

- 没有增加参数:稀疏,且不需要参与训练
- 降低内存:decoder不用存储encoder中的输出结果
- 提升了边界的描绘能力
- 该网络结构可以扩展到任意的encoder-decoder网络结构
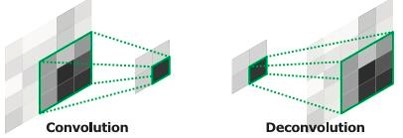
对比SegNet和FCN实现Decoder的过程。SegNet保留Pooling时的位置信息,Upsampling时直接将数据放在原先的位置,而FCN采用Transposed Convolutions+双线性插值,每一个像素都是运算后的结果。

可以看出网络大小相比FCN是要小很多,但是时间上由于加了很多去卷积层,所以并不快。
解码网络中复用max-pooling indices的好处
- 改善了边界划分。
- 减少了端到端训练的参数量。
- 仅需要少量的修改就可以合并到任何编码-解码形式的架构。
Decode实验对比

| 变量 | 说明 |
|---|---|
| SegNet-Basic | 1. 4个Encode,4个Decode; 2. upsample上采样采用下采样downsample的indices; 3. encode/decode上,每一个conv之后接一个BN操作; 4. 对于decoder网络,conv中没有采用ReLU非线性激活函数和biases偏置; 5. 采用7x7卷积核,则VGG layer4的感受野为106x106; 6. decoder卷积的filter个数与对一个的encoder卷积filter个数相同。 |
| SegNet-SingleChannelDecoder | 1. decoder卷积核个数为1。 |
| FCN-Basic-NoDimReduction | 1. 最终的维度和对应的encoder相对应。 |
- 采用双线性插值进行上采样,固定参数【不参与学习】
- 采用max-pooling indices进行上采样【不参与学习】
- 采用双线性插值进行上采样,参数参与学习
- 双线性插值进行初始化
- 结论:FCN-Basic-NoDimReduction效果最好。
总结
该论文提出了一种encoder-decoder的分割方法,相比较FCN,该方法采用了max-pooling indices进行上采样,有效的降低了upsample中的内存使用问题。
附录
深度学习之语义分割-SegNet - whz1861的博客 - CSDN博客
卷积神经网络CNN(4)-- SegNet - Fate_fjh的博客 - CSDN博客
中文翻译
【論文翻譯】SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation - IT閱讀
