实战项目-基于国家统计局城乡规划数据的地名提取(1)
超简单的小项目,涉及到简单的爬虫以及基础的python编程知识。很简单哦

最近手里有一份公司的名单,其中大部分包含了地名信息。要求根据公司名称,获取到公司所属的地级市。类似于如下。可以看到每个公司名称都会包含一个地名信息,但其中有一部分是xx县,xx乡,xx区,对于这一部分信息就需要找到这个地名他所属的上级地级市。

我最终用了一种曲线救国的办法。首先用分词工具将公司名称中的地名提取出来,然后采集国家统计局地名数据,根据地名匹配到公司所属地级市。
这里我使用的分词工具是jieba。结巴使用方法也很简单,直接pip安装就行 。
pip install jieba
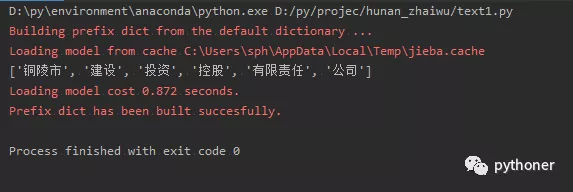
拿一个公司名测试下,可以看到已经将地名完美分割出来。
// An highlighted block
import jieba
words = jieba.lcut('铜陵市建设投资控股有限责任公司')
print(words)
接下来就是获取全国的地名数据,并保存为json文件。这一部分我是采集了国家统计局城乡规划的官网。
http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/index.html
网站很简洁,一个基本上没有反爬措施的静态页面,使用request+xpath+json可以完美实现。
接下来简单分析一下页面,因为是静态页面,所以直接打开F12的elements分析就行。这个网站首页是省份的列表页,然后点击进入,依次是地级市-区-镇/乡等的列表页。

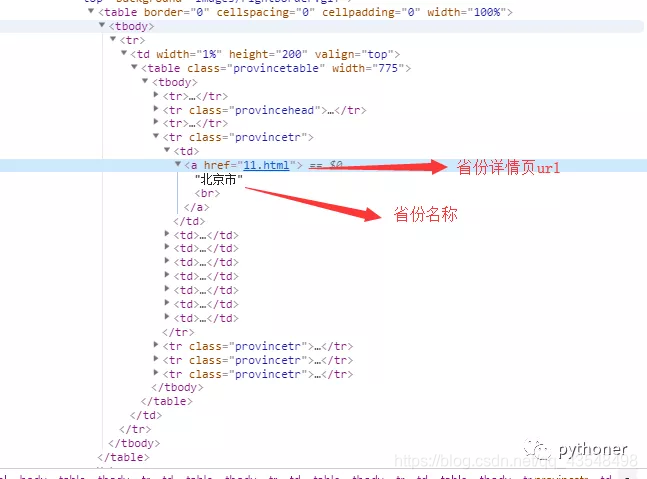
对于省份的列表页,可以通过xpath提取出数据
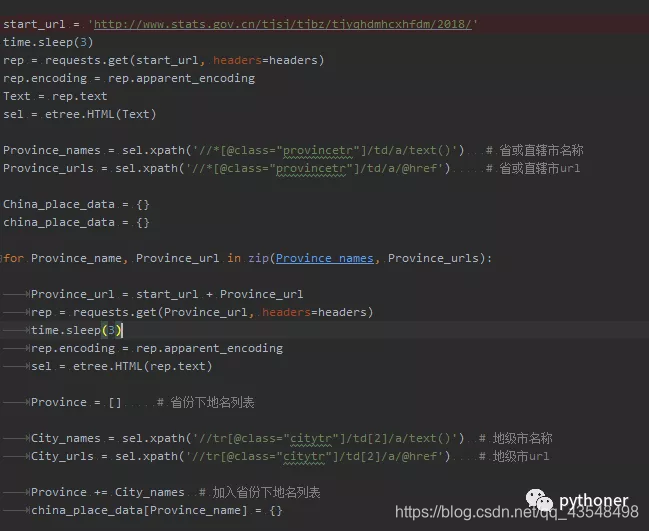
后续地级市,区,区以下地名数据采集与省份列表页相似,就不一一赘述了。需要注意的是,最终需要保存的数据结构分为两种类型。
1.[{湖南省:{郴州市:{***区:[地名1, 地名2, .....], }, {}, {}....}, {}, {}, ....}, {}, {}........]
一个大列表 列表中每个元素是字典,每个字典中包含每个省份的地级市信息,每个地级市对应地级市下属地名信息的字典,由此类推。
方便根据地名,向上匹配地级市。
2.[{湖南省:[地名1, 地名2, .....]}, {}, {},....]
一个大列表 列表中每个元素是字典,字典中每个键是省份,值是每个省份下所有地名信息。
方便根据地名,向上匹配省份。
在数据采集完毕后,需要保存为本地文件。将python数据结构存储为实体文件,其实有两种方式。分别是pickle,json。
在这里我选择json保存,
确定了保存结构之后,完善代码如下
// An highlighted block
import requests
from lxml import etree
import time
import json
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36,',
# 'Host': 'www.stats.gov.cn',
# 'Cookie': '_trs_uv=k163tn1b_6_51kd; AD_RS_COOKIE=20080918',
}
start_url = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/'
time.sleep(3)
rep = requests.get(start_url, headers=headers)
rep.encoding = rep.apparent_encoding
Text = rep.text
sel = etree.HTML(Text)
Province_names = sel.xpath('//*[@class="provincetr"]/td/a/text()') # 省或直辖市名称
Province_urls = sel.xpath('//*[@class="provincetr"]/td/a/@href') # 省或直辖市url
China_place_data = {}
china_place_data = {}
for Province_name, Province_url in zip(Province_names, Province_urls):
Province_url = start_url + Province_url
rep = requests.get(Province_url, headers=headers)
time.sleep(3)
rep.encoding = rep.apparent_encoding
sel = etree.HTML(rep.text)
Province = [] # 省份下地名列表
City_names = sel.xpath('//tr[@class="citytr"]/td[2]/a/text()') # 地级市名称
City_urls = sel.xpath('//tr[@class="citytr"]/td[2]/a/@href') # 地级市url
Province += City_names # 加入省份下地名列表
china_place_data[Province_name] = {}
for City_name, City_url in zip(City_names, City_urls):
City_url = start_url + City_url
rep = requests.get(City_url, headers=headers)
time.sleep(3)
rep.encoding = rep.apparent_encoding
sel = etree.HTML(rep.text)
County_names = sel.xpath('//tr[@class="countytr"]/td[2]/a/text()') # 区名称
County_urls = sel.xpath('//tr[@class="countytr"]/td[2]/a/@href') # 区url
Province += County_names # 加入省份下地名列表
china_place_data[Province_name][City_name] = {}
for County_name, County_url in zip(County_names, County_urls):
County_url = Province_url.replace('.html', '/') + County_url
rep = requests.get(County_url, headers=headers)
time.sleep(3)
rep.encoding = rep.apparent_encoding
Text = rep.text
sel = etree.HTML(Text)
Town_names = sel.xpath('//tr[@class="towntr"]/td[2]/a/text()') # 镇名称
Town_urls = sel.xpath('//tr[@class="towntr"]/td[2]/a/@href') # 镇url
Province += Town_names # 加入省份下地名列表
china_place_data[Province_name][City_name][County_name] = Town_names
print('{}采集完毕'.format(County_name))
print('{}采集完毕'.format(Province_name))
China_place_data[Province_name] = Province
print(China_place_data)
print(china_place_data)
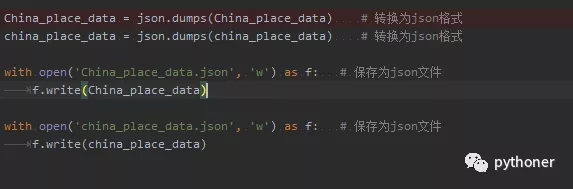
China_place_data = json.dumps(China_place_data) # 转换为json格式
china_place_data = json.dumps(china_place_data) # 转换为json格式
with open('China_place_data.json', 'w') as f: # 保存为json文件
f.write(China_place_data)
with open('china_place_data.json', 'w') as f: # 保存为json文件
f.write(china_place_data)
其中China_place_data与china_place_data分别对应以上两种数据结构。
每次请求之间加入了3秒休眠,做一个有素质的爬虫。
基于国家统计局的地名提取爬虫部分就到此结束啦。

欢迎扫码关注:

