一、部署说明
1.节点
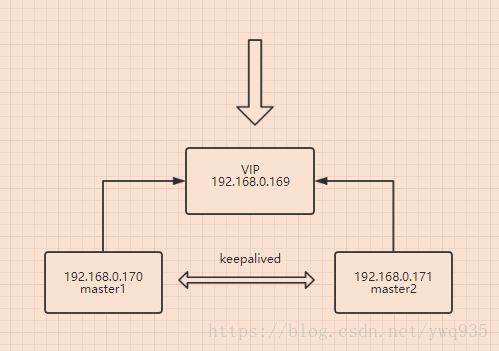
master1: IP:192.168.0.170/24 hostname:171
master2: IP:192.168.0.171/24 hostname:172
VIP:192.168.0.169/24
2.工具版本:
etcd-v3.1.10-linux-amd64.tar.gz
kubeadm-1.9.0-0.x86_64.rpm
kubectl-1.9.0-0.x86_64.rpm
kubelet-1.9.9-9.x86_64.rpm
kubernetes-cni-0.6.0-0.x86_64.rpm
socat-1.7.3.2-2.el7.x86_64.rpm
docker离线镜像:
etcd-amd64_v3.1.10.tar
k8s-dns-dnsmasq-nanny-amd64_v1.14.7.tar
k8s-dns-kube-dns-amd64_1.14.7.tar
k8s-dns-sidecar-amd64_1.14.7.tar
kube-apiserver-amd64_v1.9.0.tar
kube-controller-manager-amd64_v1.9.0.tar
kube-proxy-amd64_v1.9.0.tar
kubernetes-dashboard_v1.8.1.tar
kube-scheduler-amd64_v1.9.0.tar
pause-amd64_3.0.tar
以上安装包的云盘链接随后附上.有梯子翻墙的直接装,无需离线包。
=================================================
k8s 高可用2个核心 apiserver master和etcd
apiserver master:(需高可用)集群核心,集群API接口、集群各个组件通信的中枢;集群安全控制;
etcd :(需高可用)集群的数据中心,用于存放集群的配置以及状态信息,非常重要,如果数据丢失那么集群将无法恢复;因此高可用集群部署首先就是etcd是高可用集群;
kube-scheduler:调度器 (内部自选举)集群Pod的调度中心;默认kubeadm安装情况下–leader-elect参数已经设置为true,保证master集群中只有一个kube-scheduler处于活跃状态;
kube-controller-manager: 控制器(内部自选举)集群状态管理器,当集群状态与期望不同时,kcm会努力让集群恢复期望状态,比如:当一个pod死掉,kcm会努力新建一个pod来恢复对应replicasset期望的状态;默认kubeadm安装情况下–leader-elect参数已经设置为true,保证master集群中只有一个kube-controller-manager处于活跃状态;
kubelet: 将agent node注册上apiserver
kube-proxy: 每个node上一个,负责service vip到endpoint pod的流量转发,老版本主要通过设置iptables规则实现,新版1.9基于kube-proxy-lvs 实现

二、提前准备
1.关闭防火墙,selinux,swap
systemctl stop firewalld
systemctl disable firewalld
systemctl disable firewalld
setenforce 0
sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/sysconfig/selinux
sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
sed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/sysconfig/selinux
sed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/selinux/config
swapoff -a
echo 'swapoff -a ' >> /etc/rc.d/rc.local2.内核开启网络支持
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl -p /etc/sysctl.conf若执行sysctl -p 时报错,尝试:
modprobe br_netfilter
ls /proc/sys/net/bridge三、配置keepalived
yum -y install keepalived
cat >/etc/keepalived/keepalived.conf <<EOL
global_defs {
router_id LVS_k8s
}
vrrp_script CheckK8sMaster {
script "curl -k https://192.168.0.169:6443"
interval 3
timeout 9
fall 2
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 61
# 主节点权重最高 依次减少
priority 120
advert_int 1
#修改为本地IP
mcast_src_ip 192.168.0.170
nopreempt
authentication {
auth_type PASS
auth_pass sqP05dQgMSlzrxHj
}
unicast_peer {
#注释掉本地IP
#192.168.0.170
192.168.0.171
}
virtual_ipaddress {
192.168.0.169/24
}
track_script {
CheckK8sMaster
}
}
EOL
systemctl enable keepalived && systemctl restart keepalived
master2上修改配置里的相应ip和优先级后同样启动.
查看vip是否正常漂在master1上:
[root@170 pkgs]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:1c:5d:71 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.170/24 brd 192.168.0.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.0.169/24 scope global secondary ens33
valid_lft forever preferred_lft forever
四、etcd配置
1.配置环境变量:
export NODE_NAME=170 #当前部署的机器名称(随便定义,只要能区分不同机器即可)
export NODE_IP=192.168.0.170 # 当前部署的机器 IP
export NODE_IPS="192.168.0.170 192.168.0.171 " # etcd 集群所有机器 IP
# etcd 集群间通信的IP和端口
export ETCD_NODES="170"=https://192.168.0.170:2380,"171"=https://192.168.0.171:23802.创建ca和证书和秘钥
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
chmod +x cfssl_linux-amd64
mv cfssl_linux-amd64 /usr/local/bin/cfssl
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
chmod +x cfssljson_linux-amd64
mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
chmod +x cfssl-certinfo_linux-amd64
mv cfssl-certinfo_linux-amd64 /usr/local/bin/cfssl-certinfo生成ETCD的TLS 秘钥和证书
为了保证通信安全,客户端(如 etcdctl) 与 etcd 集群、etcd 集群之间的通信需要使用 TLS 加密,本节创建 etcd TLS 加密所需的证书和私钥。
创建 CA 配置文件:
cat > ca-config.json <<EOF
{
"signing": {
"default": {
"expiry": "8760h"
},
"profiles": {
"kubernetes": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "8760h"
}
}
}
}
EOF==ca-config.json==:可以定义多个 profiles,分别指定不同的过期时间、使用场景等参数;后续在签名证书时使用某个 profile;
==signing==:表示该证书可用于签名其它证书;生成的 ca.pem 证书中 CA=TRUE;
==server auth==:表示 client 可以用该 CA 对 server 提供的证书进行验证;
==client auth==:表示 server 可以用该 CA 对 client 提供的证书进行验证;
cat > ca-csr.json <<EOF
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF“CN”:Common Name,kube-apiserver 从证书中提取该字段作为请求的用户名 (User Name);浏览器使用该字段验证网站是否合法;
“O”:Organization,kube-apiserver 从证书中提取该字段作为请求用户所属的组 (Group);
==生成 CA 证书和私钥==:
cfssl gencert -initca ca-csr.json | cfssljson -bare ca
ls ca*==创建 etcd 证书签名请求:==
cat > etcd-csr.json <<EOF
{
"CN": "etcd",
"hosts": [
"127.0.0.1",
"192.168.0.170",
"192.168.0.171"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOFhosts 字段指定授权使用该证书的 etcd 节点 IP;
每个节点IP 都要在里面 或者 每个机器申请一个对应IP的证书
生成 etcd 证书和私钥:
cfssl gencert -ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=kubernetes etcd-csr.json | cfssljson -bare etcd
ls etcd*
mkdir -p /etc/etcd/ssl
cp etcd.pem etcd-key.pem ca.pem /etc/etcd/ssl/将生成的私钥文件分发到master2上:
scp -r /etc/etcd/ssl root@192.168.0.171:/etc/etcd/3.安装etcd
wget http://github.com/coreos/etcd/releases/download/v3.1.10/etcd-v3.1.10-linux-amd64.tar.gz
tar -xvf etcd-v3.1.10-linux-amd64.tar.gz
mv etcd-v3.1.10-linux-amd64/etcd* /usr/local/bin
mkdir -p /var/lib/etcd # 必须先创建工作目录
cat > etcd.service <<EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd/
ExecStart=/usr/local/bin/etcd \\
--name=${NODE_NAME} \\
--cert-file=/etc/etcd/ssl/etcd.pem \\
--key-file=/etc/etcd/ssl/etcd-key.pem \\
--peer-cert-file=/etc/etcd/ssl/etcd.pem \\
--peer-key-file=/etc/etcd/ssl/etcd-key.pem \\
--trusted-ca-file=/etc/etcd/ssl/ca.pem \\
--peer-trusted-ca-file=/etc/etcd/ssl/ca.pem \\
--initial-advertise-peer-urls=https://${NODE_IP}:2380 \\
--listen-peer-urls=https://${NODE_IP}:2380 \\
--listen-client-urls=https://${NODE_IP}:2379,http://127.0.0.1:2379 \\
--advertise-client-urls=https://${NODE_IP}:2379 \\
--initial-cluster-token=etcd-cluster-0 \\
--initial-cluster=${ETCD_NODES} \\
--initial-cluster-state=new \\
--data-dir=/var/lib/etcd
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
#注意,上方的环境变量一定要先配置好再进行这一步操作,在master2上export环境变量时注意修改ip
mv etcd.service /etc/systemd/system/
systemctl daemon-reload
systemctl enable etcd
systemctl start etcd
systemctl status etcd
master2同样方法安装etcd
验证服务
etcdctl \
--endpoints=https://${NODE_IP}:2379 \
--ca-file=/etc/etcd/ssl/ca.pem \
--cert-file=/etc/etcd/ssl/etcd.pem \
--key-file=/etc/etcd/ssl/etcd-key.pem \
cluster-health预期结果:
2018-04-06 20:07:41.355496 I | warning: ignoring ServerName for user-provided CA for backwards compatibility is deprecated
2018-04-06 20:07:41.357436 I | warning: ignoring ServerName for user-provided CA for backwards compatibility is deprecated
member 57d56677d6df8a53 is healthy: got healthy result from https://192.168.0.170:2379
member 7ba40ace706232da is healthy: got healthy result from https://192.168.0.171:2379若有失败,重新配置
systemctl stop etcd
rm -Rf /var/lib/etcd
rm -Rf /var/lib/etcd-cluster
mkdir -p /var/lib/etcd
systemctl start etcd五.docker安装
若原来已经安装docker版本,建议卸载后安装docker-ce版本:
yum -y remove docker docker-common基于aliyun安装docker-ce方法:
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
# Step 2: 添加软件源信息
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# Step 3: 更新并安装 Docker-CE
sudo yum makecache fast
sudo yum -y install docker-ce
# Step 4: 开启Docker服务
sudo service docker start && systemctl enbale docker 六.安装kubelet、kubectl、kubeadm、kubecni
准备好提前下载好的rpm包:
[root@170 pkgs]# cd /root/k8s_images/pkgs
[root@170 pkgs]# ls
etcd-v3.1.10-linux-amd64.tar.gz kubeadm-1.9.0-0.x86_64.rpm kubectl-1.9.0-0.x86_64.rpm kubelet-1.9.9-9.x86_64.rpm kubernetes-cni-0.6.0-0.x86_64.rpm socat-1.7.3.2-2.el7.x86_64.rpm
[root@170 pkgs]# yum -y install *.rpm
修改kubelet启动参数里的cgroup驱动以便兼容docker:
vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
#Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=systemd"
Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=cgroupfs"
systemctl enable docker && systemctl restart docker
systemctl daemon-reload && systemctl restart kubelet在master2上同样操作
七.kubeadm初始化
将准备好的本地的docker images镜像导入本地仓库内
[root@170 docker_images]# ls
etcd-amd64_v3.1.10.tar k8s-dns-dnsmasq-nanny-amd64_v1.14.7.tar k8s-dns-sidecar-amd64_1.14.7.tar kube-controller-manager-amd64_v1.9.0.tar kubernetes-dashboard_v1.8.1.tar pause-amd64_3.0.tar
flannel:v0.9.1-amd64.tar k8s-dns-kube-dns-amd64_1.14.7.tar kube-apiserver-amd64_v1.9.0.tar kube-proxy-amd64_v1.9.0.tar kube-scheduler-amd64_v1.9.0.tar
[root@170 docker_images]# for i in `ls`;do docker load -i $i;doneconfig.yaml初始化配置文件:
cat <<EOF > config.yaml
apiVersion: kubeadm.k8s.io/v1alpha1
kind: MasterConfiguration
etcd:
endpoints:
- https://192.168.0.170:2379
- https://192.168.0.171:2379
caFile: /etc/etcd/ssl/ca.pem
certFile: /etc/etcd/ssl/etcd.pem
keyFile: /etc/etcd/ssl/etcd-key.pem
dataDir: /var/lib/etcd
networking:
podSubnet: 10.244.0.0/16
kubernetesVersion: 1.9.0
api:
advertiseAddress: "192.168.0.170"
token: "b99a00.a144ef80536d4344"
tokenTTL: "0s"
apiServerCertSANs:
- "170"
- "171"
- 192.168.0.169
- 192.168.0.170
- 192.168.0.171
featureGates:
CoreDNS: true
EOF初始化集群
kubeadm init --config config.yaml结果:
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
as root:
kubeadm join --token b99a00.a144ef80536d4344 192.168.0.169:6443 --discovery-token-ca-cert-hash sha256:ebc2f64e9bcb14639f26db90288b988c90efc43828829c557b6b66bbe6d68dfa
[root@170 docker_images]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
170 Ready master 5h v1.9.0 <none> CentOS Linux 7 (Core) 3.10.0-693.el7.x86_64 docker://18.3.0
171 Ready master 4h v1.9.0 <none> CentOS Linux 7 (Core) 3.10.0-693.el7.x86_64 docker://18.3.0
注意:提示信息中的kubeadm join那一行请保存好,后期使用kubeadm扩增集群时,需要在新的node上使用这行命令加入集群
按照提示创建目录和kubeconfig文件,否则kubectl无法正常获取集群信息:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config配置master2:
#拷贝pki 证书
mkdir -p /etc/kubernetes/pki
scp -r /etc/kubernetes/pki/ root@192.168.0.171:/etc/kubernetes/
#拷贝初始化配置
scp config.yaml root@192.168.0.171:/etc/kubernetes/
#在master2上初始化
kubeadm init --config /etc/kubernetes/config.yaml 八、安装网络插件kube-router
wget https://github.com/cloudnativelabs/kube-router/blob/master/daemonset/kubeadm-kuberouter.yaml
kubectl apply -f kubeadm-kuberouter.yaml
[root@170 docker_images]# kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-546545bc84-j5mds 1/1 Running 2 5h
kube-system kube-apiserver-170 1/1 Running 2 5h
kube-system kube-apiserver-171 1/1 Running 2 4h
kube-system kube-controller-manager-170 1/1 Running 2 5h
kube-system kube-controller-manager-171 1/1 Running 2 4h
kube-system kube-proxy-5dg4j 1/1 Running 2 4h
kube-system kube-proxy-s6jtn 1/1 Running 2 5h
kube-system kube-router-wbxvq 1/1 Running 2 4h
kube-system kube-router-xrkbw 1/1 Running 2 4h
kube-system kube-scheduler-170 1/1 Running 2 5h
kube-system kube-scheduler-171 1/1 Running 2 4h
部署完成
默认情况下,为了保证master的安全,master是不会被调度到app的。使用调度tanit规则打破这个限制,使pod可以部署在master中:
kubectl taint nodes --all node-role.kubernetes.io/master-配置私有docker仓库,加速使用:
vim /lib/systemd/system/docker.service
注释#ExecStart=/usr/bin/dockerd
ExecStart=/usr/bin/dockerd --insecure-registry registry.yourself.com:5000
#填写自己的docker仓库地址