转载至:https://blog.csdn.net/qauchangqingwei/article/details/80831797
一 char和string的区别:
1 char是表示的是字符,定义的时候用单引号,只能存储一个字符。例如; char='d'.
而String表示的是字符串,定义的时候用双引号,可以存储一个或者多个字符。例如:String=“we are neuer”。
2 char是基本数据类型,而String是个类,属于引用数据类型。String类可以调用方法,具有面向对象的特征。
二 char类型
char在Java中是16位的,因为Java用的是Unicode。
三 String类型
1 java设计了两种不同的方法来生成字符串对象,一种是使用双引号,一种是调用String类的构造函数。
注:Java为String类型提供了缓冲池机制,当使用双引号定义对象时,Java环境首先去字符串缓冲池寻找内容相同的字符串,如果存在就拿出来使用,否则就创建一个新的字符串放在缓冲池中。
例如: String S=new String("abc''), 产生(或者创建)几个对象?
答案是:产生一个或者两个对象。如果常量池中原来没有“abc",就产两个对象,如果字符串常量池中"abc",就产生一个对象。
因此,这个问题如果换成 String str = new String("abc")涉及到几个String对象?合理的解释是2个。
1)String类是final类,也即意味着String类不能被继承,并且它的成员方法都默认为final方法。在Java中,被final修饰的类是不允许被继承的,并且该类中的成员方法都默认为final方法。
在这里要永远记住一点:“String对象一旦被创建就是固定不变的了,对String对象的任何改变都不影响到原对象,相关的任何change操作都会生成新的对象”。
2 字符串常量池
我们知道字符串的分配和其他对象分配一样,是需要消耗高昂的时间和空间的,而且字符串我们使用的非常多。JVM为了提高性能和减少内存的开销,在实例化字符串的时候进行了一些优化:使用字符串常量池。每当我们创建字符串常量时,JVM会首先检查字符串常量池,如果该字符串已经存在常量池中,那么就直接返回常量池中的实例引用。如果字符串不存在常量池中,就会实例化该字符串并且将其放到常量池中。由于String字符串的不可变性我们可以十分肯定常量池中一定不存在两个相同的字符串(这点对理解上面至关重要)。
Java中的常量池,实际上分为两种形态:静态常量池和运行时常量池。
所谓静态常量池,即*.class文件中的常量池,class文件中的常量池不仅仅包含字符串(数字)字面量,还包含类、方法的信息,占用class文件绝大部分空间。
而运行时常量池,则是jvm虚拟机在完成类装载操作后,将class文件中的常量池载入到内存中,并保存在方法区中,我们常说的常量池,就是指方法区中的运行时常量池。
例如下面的例子:

总结:虽然a、b、c、chenssy是不同的对象,但是从String的内部结构我们是可以理解上面的。String c = new String("chenssy");虽然c的内容是创建在堆中,但是他的内部value还是指向JVM常量池的chenssy的value,它构造chenssy时所用的参数依然是chenssy字符串常量。
例1
输出的结果: True
分析:当执行String str1="aaa"时,JVM首先会去字符串池中查找是否存在"aaa"这个对象,如果不存在,则在字符串池中创建"aaa"这个对象,然后将池中"aaa"这个对象的引用地址返回给字符串常量str1,这样str1会指向池中"aaa"这个字符串对象;如果存在,则不创建任何对象,直接将池中"aaa"这个对象的地址返回,赋给字符串常量。当创建字符串对象str2时,字符串池中已经存在"aaa"这个对象,直接把对象"aaa"的引用地址返回给str2,这样str2指向了池中"aaa"这个对象,也就是说str1和str2指向了同一个对象,因此语句System.out.println(str1 == str2)输出:true。
例2
输出的结果为:false
分析: 采用new关键字新建一个字符串对象时,JVM首先在字符串池中查找有没有"aaa"这个字符串对象,如果有,则不在池中再去创建"aaa"这个对象了,直接在堆中创建一个"aaa"字符串对象,然后将堆中的这个"aaa"对象的地址返回赋给引用str3,这样,str3就指向了堆中创建的这个"aaa"字符串对象;如果没有,则首先在字符串池中创建一个"aaa"字符串对象,然后再在堆中创建一个"aaa"字符串对象,然后将堆中这个"aaa"字符串对象的地址返回赋给str3引用,这样,str3指向了堆中创建的这个"aaa"字符串对象。当执行String str4=new String("aaa")时, 因为采用new关键字创建对象时,每次new出来的都是一个新的对象,也即是说引用str3和str4指向的是两个不同的对象,因此语句System.out.println(str3 == str4)输出:false。
例 3
输出结果:True,True。
分析:因为例子中的s0和s1中的"helloworld”都是字符串常量,它们在编译期就被确定了,所以s0==s1为true;而"hello”和"world”也都是字符串常量,当一个字符串由多个字符串常量连接而成时,它自己肯定也是字符串常量,所以s2也同样在编译期就被解析为一个字符串常量,所以s2也是常量池中"helloworld”的一个引用。所以我们得出s0==s1==s2。
例 4
答案:false,false,false。
分析:用new String() 创建的字符串不是常量,不能在编译期就确定,所以new String() 创建的字符串不放入常量池中,它们有自己的地址空间
s0还是常量池中"helloworld”的引用,s1因为无法在编译期确定,所以是运行时创建的新对象"helloworld”的引用,s2因为有后半部分new String(”world”)所以也无法在编译期确定,所以也是一个新创建对象"helloworld”的引用。
例 5:
输出的结果:false。
分析:JVM对于字符串引用,由于在字符串的"+"连接中,有字符串引用存在,而引用的值在程序编译期是无法确定的,即"a" + s1无法被编译器优化,只有在程序运行期来动态分配并将连接后的新地址赋给s2。所以上面程序的结果也就为false。
例 6:
输出结果: false。
分析:因为str3指向堆中的"abcdef"对象,而"abcdef"是字符串池中的对象,所以结果为false。JVM对String str="abc"对象放在常量池中是在编译时做的,而String str3=str1+str2是在运行时刻才能知道的。new对象也是在运行时才做的。而这段代码总共创建了5个对象,字符串池中两个、堆中三个。+运算符会在堆中建立来两个String对象,这两个对象的值分别是"abc"和"def",也就是说从字符串池中复制这两个值,然后在堆中创建两个对象,然后再建立对象str3,然后将"abcdef"的堆地址赋给str3。
步骤:
1)栈中开辟一块中间存放引用str1,str1指向池中String常量"abc"。
2)栈中开辟一块中间存放引用str2,str2指向池中String常量"def"。
3)栈中开辟一块中间存放引用str3。
4)str1 + str2通过StringBuilder的最后一步toString()方法还原一个新的String对象"abcdef",因此堆中开辟一块空间存放此对象。
5)引用str3指向堆中(str1 + str2)所还原的新String对象。
6)str3指向的对象在堆中,而常量"abcdef"在池中,输出为false。
例 7;
输出的结果:false。
分析:JVM对于字符串引用,由于在字符串的"+"连接中,有字符串引用存在,而引用的值在程序编译期是无法确定的,即"a" + s1无法被编译器优化,只有在程序运行期来动态分配并将连接后的新地址赋给s2。所以上面程序的结果也就为false。
例 8
执行上述代码,结果为:true、false。
分析:为什么出现上面的结果呢?这是因为,字符串字面量拼接操作是在Java编译器编译期间就执行了,也就是说编译器编译时,直接把"java"、"language"和"specification"这三个字面量进行"+"操作得到一个"javalanguagespecification" 常量,并且直接将这个常量放入字符串池中,这样做实际上是一种优化,将3个字面量合成一个,避免了创建多余的字符串对象。而字符串引用的"+"运算是在Java运行期间执行的,即str + str2 + str3在程序执行期间才会进行计算,它会在堆内存中重新创建一个拼接后的字符串对象。总结来说就是:字面量"+"拼接是在编译期间进行的,拼接后的字符串存放在字符串池中;而字符串引用的"+"拼接运算实在运行时进行的,新创建的字符串存放在堆中。
对于直接相加字符串,效率很高,因为在编译器便确定了它的值,也就是说形如"I"+"love"+"java"; 的字符串相加,在编译期间便被优化成了"Ilovejava"。对于间接相加(即包含字符串引用),形如s1+s2+s3; 效率要比直接相加低,因为在编译器不会对引用变量进行优化。
例 9
输出结果:true。
分析:和例子7中唯一不同的是s1字符串加了final修饰,对于final修饰的变量,它在编译时被解析为常量值的一个本地拷贝存储到自己的常量池中或嵌入到它的字节码流中。所以此时的"a" + s1和"a" + "b"效果是一样的。故上面程序的结果为true。
例 10
执行上述代码,结果为:false。
分析:这里面虽然将s1用final修饰了,但是由于其赋值是通过方法调用返回的,那么它的值只能在运行期间确定,因此s0和s2指向的不是同一个对象,故上面程序的结果为false。
三、总结
1.String类初始化后是不可变的(immutable)
String使用private final char value[]来实现字符串的存储,也就是说String对象创建之后,就不能再修改此对象中存储的字符串内容,就是因为如此,才说String类型是不可变的(immutable)。程序员不能对已有的不可变对象进行修改。我们自己也可以创建不可变对象,只要在接口中不提供修改数据的方法就可以。
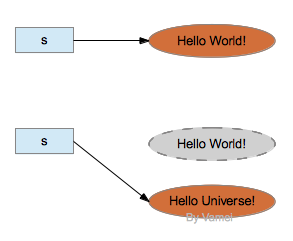
然而,String类对象确实有编辑字符串的功能,比如replace()。这些编辑功能是通过创建一个新的对象来实现的,而不是对原有对象进行修改。比如:
s = s.replace("World", "Universe");
上面对s.replace()的调用将创建一个新的字符串"Hello Universe!",并返回该对象的引用。通过赋值,引用s将指向该新的字符串。如果没有其他引用指向原有字符串"Hello World!",原字符串对象将被垃圾回收。
2.引用变量与对象
A aa;
这个语句声明一个类A的引用变量aa[我们常常称之为句柄],而对象一般通过new创建。所以aa仅仅是一个引用变量,它不是对象。
3.创建字符串的方式
创建字符串的方式归纳起来有两类:
(1)使用""引号创建字符串;
(2)使用new关键字创建字符串。
结合上面例子,总结如下:
(1)单独使用""引号创建的字符串都是常量,编译期就已经确定存储到String Pool中;
(2)使用new String("")创建的对象会存储到heap中,是运行期新创建的;
new创建字符串时首先查看池中是否有相同值的字符串,如果有,则拷贝一份到堆中,然后返回堆中的地址;如果池中没有,则在堆中创建一份,然后返回堆中的地址(注意,此时不需要从堆中复制到池中,否则,将使得堆中的字符串永远是池中的子集,导致浪费池的空间)!
(3)使用只包含常量的字符串连接符如"aa" + "aa"创建的也是常量,编译期就能确定,已经确定存储到String Pool中;
(4)使用包含变量的字符串连接符如"aa" + s1创建的对象是运行期才创建的,存储在heap中;
4.使用String不一定创建对象
在执行到双引号包含字符串的语句时,如String a = "123",JVM会先到常量池里查找,如果有的话返回常量池里的这个实例的引用,否则的话创建一个新实例并置入常量池里。所以,当我们在使用诸如String str = "abc";的格式定义对象时,总是想当然地认为,创建了String类的对象str。担心陷阱!对象可能并没有被创建!而可能只是指向一个先前已经创建的对象。只有通过new()方法才能保证每次都创建一个新的对象。
5.使用new String,一定创建对象
在执行String a = new String("123")的时候,首先走常量池的路线取到一个实例的引用,然后在堆上创建一个新的String实例,走以下构造函数给value属性赋值,然后把实例引用赋值给a:
从中我们可以看到,虽然是新创建了一个String的实例,但是value是等于常量池中的实例的value,即是说没有new一个新的字符数组来存放"123"。
6.关于String.intern()
intern方法使用:一个初始为空的字符串池,它由类String独自维护。当调用 intern方法时,如果池已经包含一个等于此String对象的字符串(用equals(oject)方法确定),则返回池中的字符串。否则,将此String对象添加到池中,并返回此String对象的引用。
它遵循以下规则:对于任意两个字符串 s 和 t,当且仅当 s.equals(t) 为 true 时,s.intern() == t.intern() 才为 true。
String.intern();
再补充介绍一点:存在于.class文件中的常量池,在运行期间被jvm装载,并且可以扩充。String的intern()方法就是扩充常量池的一个方法;当一个String实例str调用intern()方法时,java查找常量池中是否有相同unicode的字符串常量,如果有,则返回其引用,如果没有,则在常量池中增加一个unicode等于str的字符串并返回它的引用。
运行结果:false、false、true、true。
7.关于equals和==
(1)对于==,如果作用于基本数据类型的变量(byte,short,char,int,long,float,double,boolean ),则直接比较其存储的"值"是否相等;如果作用于引用类型的变量(String),则比较的是所指向的对象的地址(即是否指向同一个对象)。
(2)equals方法是基类Object中的方法,因此对于所有的继承于Object的类都会有该方法。在Object类中,equals方法是用来比较两个对象的引用是否相等,即是否指向同一个对象。
(3)对于equals方法,注意:equals方法不能作用于基本数据类型的变量。如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址;而String类对equals方法进行了重写,用来比较指向的字符串对象所存储的字符串是否相等。其他的一些类诸如Double,Date,Integer等,都对equals方法进行了重写用来比较指向的对象所存储的内容是否相等。
8 .String、StringBuffer、StringBuilder的区别
(1)可变与不可变:String是不可变字符串对象,StringBuilder和StringBuffer是可变字符串对象(其内部的字符数组长度可变)。
(2)是否多线程安全:String中的对象是不可变的,也就可以理解为常量,显然线程安全。StringBuffer 与 StringBuilder 中的方法和功能完全是等价的,只是StringBuffer 中的方法大都采用了synchronized 关键字进行修饰,因此是线程安全的,而 StringBuilder 没有这个修饰,可以被认为是非线程安全的。
(3)String、StringBuilder、StringBuffer三者的执行效率:
StringBuilder > StringBuffer > String 当然这个是相对的,不一定在所有情况下都是这样。比如String str = "hello"+ "world"的效率就比 StringBuilder st = new StringBuilder().append("hello").append("world")要高。因此,这三个类是各有利弊,应当根据不同的情况来进行选择使用:
当字符串相加操作或者改动较少的情况下,建议使用 String str="hello"这种形式;
当字符串相加操作较多的情况下,建议使用StringBuilder,如果采用了多线程,则使用StringBuffer。
9 String中的final用法
final StringBuffer a = new StringBuffer("111"); final StringBuffer b = new StringBuffer("222"); a=b;//此句编译不通过
final StringBuffer a = new StringBuffer(“111”);
a.append(“222”);//编译通过
10.字符串池的优缺点:
字符串池的优点就是避免了相同内容的字符串的创建,节省了内存,省去了创建相同字符串的时间,同时提升了性能;另一方面,字符串池的缺点就是牺牲了JVM在常量池中遍历对象所需要的时间,不过其时间成本相比而言比较低。
public class StringTest {运行结果:
s1 == s2 : true
s1.equals(s2) : true
s3 == s4 : false
s3.equals(s4) : true
s1 == s3 : false
s1.equals(s3) : true
str1 = str11 : true
str4 = str5 : false
str7 = str67 : false
str9 = str89 : true
