
参加此统计学习小组主要是巩固 python 语言,故所有笔记都以 python 代码实现。
完整代码见 github : StatisticLearning
如何描述数据的分布?可以从以下三个方面来描述:
- 集中趋势
- 离散程度
- 分布的形状
一、集中趋势
集中趋势反映了各数据向其中心值靠拢或聚集的程度。
本示例为给出的 .xlsx 文件中的表格数据,数据为 9 个家庭的人均月收入数据(单位:元):
1080 750 1080 1080 850 960 2000 1250 1630
1. 众数
众数(mode):一组数据中出现次数最多的变量值。
首先读取数据:
df = pd.read_excel('data/2_table1.xlsx')
为便于计算众数,使用了 collections 模块中的 Counter 类来计数, Counter 类继承自 dict 类,返回的是按数据出现次数由多到少排序的字典:
count = Counter(df['月收入'])
得到出现次数最多的变量值:
mode = count.most_common(1)[0][0]
print(mode)
输出为 「1080」即为该数据的众数。
或者直接用 numpy 库中的函数实现:
counts = np.bincount(df['月收入'])
print(np.argmax(counts))
2. 中位数
中位数(median):一组数据排序后处于中间位置上的变量值。
计算上述数据的中位数:
# 中位数
median = np.median(df['月收入'])
print(median)
3. 四分位数
四分位数(quartile):一组数据排序后处于 25% 位置上的数值(下四分位数)和处于 75% 位置上的数值(上四分位数)。

如果计算出来的位置是整数,四分位数就是该位置对应的值;
如果是在 0.5 的位置上,则取该位置两侧值的平均数;
如果是在 0.25 或 0.75 的位置上,则四分位数等于该位置的下侧值加上按比例分摊位置两侧数值的差值;
则定义四分位数的计算函数为:
def calculateQuartile(data, index):
if isinstance(index, int):
quartile = data[index]
elif (index*100 % 100) == 50.0:
quartile = (data[int(index) - 1] + data[int(index)])/2
else:
quartile = data[int(index)-1] + (data[int(index)] - data[int(index)-1]) * (index*100%100) / 100
return quartile
if __name__ == '__main__':
df = pd.read_excel('data/2_table1.xlsx')
data = np.sort(df['月收入'])
# 四分位数
# 下四分位数
index1 = len(data)/4
print(calculateQuartile(data, index1))
# 上四分位数
index2 = 3 * len(data) / 4
print(calculateQuartile(data, index2))
4. 平均数
平均数(mean)也称均值,是一组数据相加后除以数据的个数得到的结果。
平均数根据是否分组分为简单平均数和加权平均数:
-
简单平均数:根据未经分组数据计算的平均数,计算公式为:
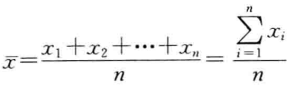
-
加权平均数:根据分组数据计算的平均数,计算公式为:
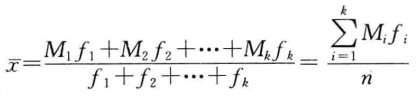
其中,M 为各组的组中值,n 为样本量。
平均数根据计算方式又分为算数平均数和几何平均数:
-
算术平均数:与上面简单平均数的计算方式一样。
-
几何平均数:n个变量值连乘积的n次方根:

python中求平均数可以使用 numpy 库的方法:
import numpy as np
np.mean(nums)
每一种具体的平均数的计算公式已在上面列出,这里就不分别进行 python 代码的编写了。
5. 众数、中位数和平均数的比较
5.1 众数、中位数和平均数的关系

该图是贾俊平《统计学》一书中众数、中位数和平均数的关系图,其中 Mo 为众数,Me 为中位数, x 为均值。
如果数据的分布是对称的,即为正态分布(也叫对称分布),即均值 = 中位数 = 众数;
如果数据是左偏分布,即均值<中位数<众数;
如果数据是右偏分布,即众数<中位数<均值
仅仅看这个图很容易感到迷惑,这不符合我们日常认知,我们往往会认为峰值偏右为右偏分布(图二),峰值偏左为左偏分布(图三),实际刚好相反。
这是因为,在这个图中,纵坐标表示的是「频率」,众数就是图中频率最大的变量值,中位数仅与样本的总数有关,在样本的中间位置,平均数在这里计算的是「加权平均数」。
5.2 众数、中位数和平均数的比较
| 中位数 | 众数 | 算数平均数 | 几何平均数 | |
|---|---|---|---|---|
| 英文名 | Median | Mode | Arithmetic mean | Geometric Mean |
| 别称 | 中值 | 均值 | ||
| 定义 | 一组数据排序后处于中间位置上的变量值 | 一组数据中出现次数最多的变量值 | n个变量的和除以n | n个变量值连乘积的n次方根 |
| 优点 | 一组数据中间位置上的代表值,不受极端值的影响 | 一组数据分布的峰值,不受极端值的影响 | 利用了全部数据信息,实际应用最广泛 | 不受极端值的影响 |
| 缺点 | 需要先排序 | 不唯一,可能有零到多个众数 | 易受极端值的影响 | 变量值不能为0或负数,仅适用于计算平均比率 |
| 适用场景 | 顺序数据的集中趋势测度值 | 分类数据的集中趋势测度值 | 数值型数据的集中趋势测度值 | 计算现象的平均增长率 |
二、离散程度
离散程度反映了各数据远离其中心值的趋势。
1. 分类数据:异众比率
异众比率(variation ratio):非众数组的频数占总频数的比例。
拿上面第一章中 9 个家庭的人均月收入数据来计算异众比率,python代码为:
# 众数
count = Counter(df['月收入'])
modeCount = count.most_common(1)[0][1]
# print(modeCount)
totalCount = len(df['月收入'])
nomodeCount = totalCount - modeCount
# 异众比率
ratio = nomodeCount / totalCount
print(ratio)
2. 顺序数据:四分位差
四分位差(quartile deviation):也称内距或四分间距(inter-quartile range),是上四分位数与下四分位数只差,四分位数在上面第一章第 3 节已经讲了,这里就不再赘述。
3. 数值型数据:方差和标准差
| 英文名 | 概念 | 公式 | |
|---|---|---|---|
| 极差 | range | 一组数据的最大值与最小值之差 | |
| 平均差 | mean deviation | 各变量值与其平均数离差绝对值的平均数 | $M_{d}=\frac{\sum_{i=1}^{n}\left |
| 方差 | variance | 各变量值与其平均数离差平方的平均数 | |
| 标准差 | standard deviation | 方差的平方根 | |
| 标准分数 | standard score | 各变量值与其平均数的离差除以标准差 | |
| 离散系数 | coefficient of variation | 数据的标准差与平均数之比 |
三、分布的形状
分布的形状,反映了数据分布的偏态和峰态。
1. 偏态
偏态:对数据分布对称性的测度。
偏态系数:测度偏态的统计量。
如果偏态系数等于 0,则数据的分布是对称的;
如果偏态系数不等于 0,泽数据的分布是不对称的;
如果偏态系数大于 1 或小于 -1 ,称为高度偏态分布;
如果偏态系数在 0.5 到 1,或 -1 到 -0.5 之间,称为中等偏态分布。
公式为:
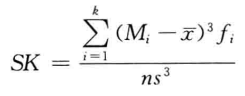
2. 峰态
峰态:对数据分布平峰或尖峰程度的测度。
峰态系数:测度峰态的统计量。
如果一组数据服从标准正态分布,则峰态系数的值等于 0;
如果峰态系数的值不等于 0,称为平峰分布或尖峰分布;
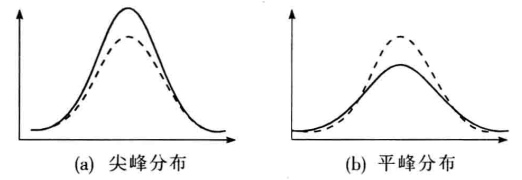
公式为:

参考资料:
《统计学(第七版)》贾俊平,所有数据都来自该书。
统计学学习小组参加自公众号「数据科学家联盟」。
