序列在现实世界中是非常常见的一种数据形式,即在时间维度上传感器采集的数据流。我们最常见的序列数据像语音,自然语言,视频等信号,它们的共同点就是有很强的上下文。一般而言,任何高级有效的模型在处理这种数据时都会考虑这种上下文关系,充分挖掘潜藏的时空相关性,以对数据进行建模,比如混合动态纹理模型。而异常呢,一般在不同场景中有不同的定义,比如一个心脏跳动的信号,在平稳中突然跳动。那么这个跳动就是异常,任何高级的系统都会捕捉到异常并报警。无论是哪种异常,在计算机的世界里,无非就是在特征维度张成的空间中,根据相应的度量形式寻找远离簇的孤立点。其实,异常检测在现实世界中有着广泛的应用,并在各领域扮演着重要的角色,比如网络入侵,欺诈检测,视频监控等。
本文主要讨论在序列数据中如何建立有效的非监督模型去发现异常。非监督的框架在现实世界中更加有效,因为数据的标签很难有效得到。总之,这类问题有3个挑战:
- 噪声:任何系统都存在噪声,当然噪声有不同的表现形式。正因为噪声的存在,使得某些正常数据看似异常,给该类问题带来挑战。
- 时间相干性:由于存在很强的上下文关系,因此异常检测会面临相关性挑战。另外,序列数据一般会随着时间不断演变进化;更有甚者,异常/正常也会随着时间演变。比如,心脏跳动信号,平稳中出现跳动,跳动中突然平稳。
- 数据维度:比如在视频监控中,我们面临的数据是高维的。设计的模型一方面能应对这种高维数据,一方面得有时间复杂度的把控。
下面介绍3篇文献,学习他们的建模方法。其中,一篇基于传统的类似混合动态纹理模型,另两篇基于比较火的RNN和LSTM模型。
第一篇文献是国内中山大学在视觉领域-前景检测方面的研究成果,Complex background subtraction by pursuing dynamic spatio-temporal models。总的来说,提出的方法最核心的思想即是在一个定义的隐空间中考虑时间相干性;并提出了模型在在线检测中的更新机制。我们具体看一下建模过程:
表示在
个连续帧中相同位置处的数据,其中
表示在第
帧的当前位置处提取的特征向量。该特征向量是在以该位置为中心的小立方体(比如
pixels)中提取类似于local ternary patterns (LTP)的特征。在这个特征向量空间中,作者采用了一组正交基
来表示其中的点,并刻画序列数据的一致性:
其中 为系数, 为误差项。在系数层这个隐空间中,作者采用了矩阵 来表征数据的动态性,并刻画序列数据的时间相干性:
最终的问题形式化为:
因此,解决这类问题的一个严峻挑战-时间相干性,就转化为了在观测数据下,求解数据一致性矩阵 和时间相干性矩阵 。该问题的求解采用交替优化的策略, 和 ( )。比如在当前数据 下,求解 :
上述问题可通过对 的奇异值分解求解。对于 :
检测部分:当有新的数据 时,即可通过 求解重构误差判断其是否是异常。并更新模型,比如更新 :
表示最近观测的样本数,即span of observations。
第二篇文献为TIP2017年上的文章Unsupervised Sequential Outlier Detection With Deep Architectures。这个工作与上一个工作有着异曲同工之妙,同样是在隐层空间中考虑时间相关性;上一篇用矩阵
来线性刻画,那么这篇文章这是用循环神经网络来非线性刻画。模型的层级结构如下:
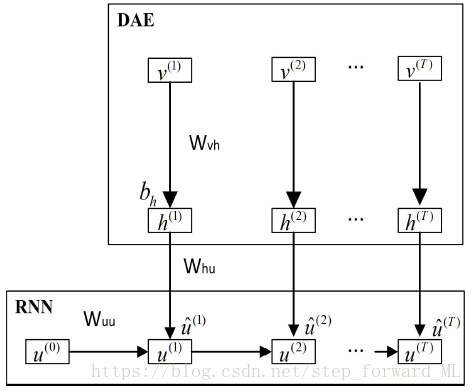
通过上图可知,该模型包含两部分:去噪自动编码器(DAE)和循环神经网络(RNN)。其中DAE主要用来提取特征,捕捉正常数据和异常数据间最本质的区别;RNN则充分利用上下文,并使学习器应对时间维度上的演变更加稳健。
h层为自动编码器的隐层,这里不做详细介绍。下面我们主要看RNN,与标准的循环神经网络不同,作者简化了其形式,即当前状态仅取决于上一个状态:
在各状态间同样权值共享。那么 呢:
最终的损失函数:
上述即为模型的整个图结构(graph)。训练过程如下:
首先,单独训练DAE,学习参数 ,得到h层的输出;
然后,根据损失函数,学习参数 。
最终,fine-tune,通过损失函数,学习所有参数。
在测试阶段,只需根据DAE的重构误差来判断是否异常。
第三篇文献为ICCV2015年上的文章Unsupervised Extraction of Video Highlights Via Robust Recurrent Auto-encoders。这个工作与上一个工作类似,同样是在隐层空间中考虑时间相关性;用LSTM而不是循环神经网络来非线性刻画。模型的层级结构如下:
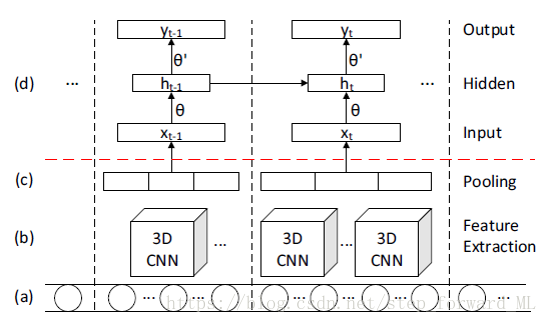
上图中(a)为视频帧序列,在一段时间内用3D CNN提取特征;红色虚线上是自动编码器,而在自动编码器的隐层(d)用LSTM刻画时间维度上的相干性。异常是否的判断同样考虑重构误差。